 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEAL: Data-Efficient Adversarial Learning for High-Quality Infrared Imaging
Mar 02, 2025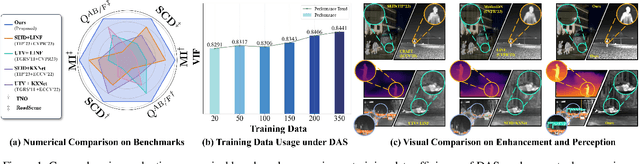
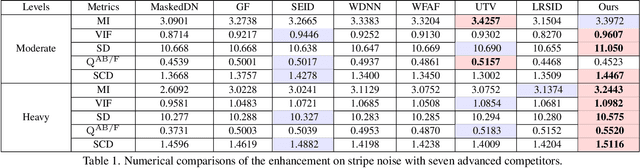
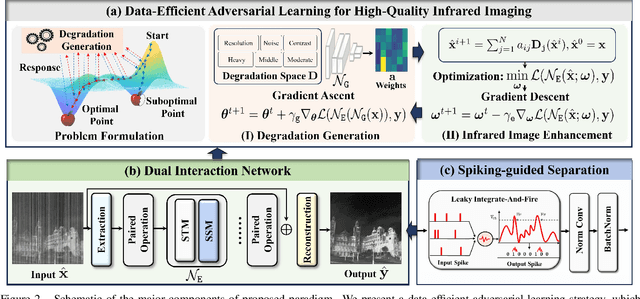
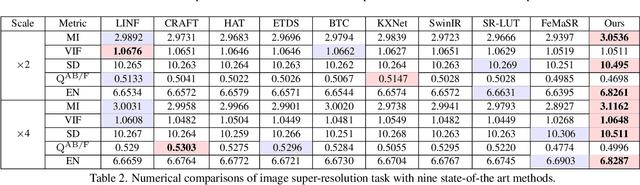
Thermal imaging is often compromised by dynamic, complex degradations caused by hardware limitations and unpredictable environmental factors. The scarcity of high-quality infrared data, coupled with the challenges of dynamic, intricate degradations, makes it difficult to recover details using existing methods. In this paper, we introduce thermal degradation simulation integrated into the training process via a mini-max optimization, by modeling these degraded factors as adversarial attacks on thermal images. The simulation is dynamic to maximize objective functions, thus capturing a broad spectrum of degraded data distributions. This approach enables training with limited data, thereby improving model performance.Additionally, we introduce a dual-interaction network that combines the benefits of spiking neural networks with scale transformation to capture degraded features with sharp spike signal intensities. This architecture ensures compact model parameters while preserving efficient feature representation. Extensive experiments demonstrate that our method not only achieves superior visual quality under diverse single and composited degradation, but also delivers a significant reduction in processing when trained on only fifty clear images, outperforming existing techniques in efficiency and accuracy. The source code will be available at https://github.com/LiuZhu-CV/DEAL.
Automatic Classification of Bug Reports Based on Multiple Text Information and Reports' Intention
Aug 02, 2022With the rapid growth of software scale and complexity, a large number of bug reports are submitted to the bug tracking system. In order to speed up defect repair, these reports need to be accurately classified so that they can be sent to the appropriate developers. However, the existing classification methods only use the text information of the bug report, which leads to their low performance. To solve the above problems, this paper proposes a new automatic classification method for bug reports. The innovation is that when categorizing bug reports, in addition to using the text information of the report, the intention of the report (i.e. suggestion or explanation) is also considered, thereby improving the performance of the classification. First, we collect bug reports from four ecosystems (Apache, Eclipse, Gentoo, Mozilla) and manually annotate them to construct an experimental data set. Then, we use Natural Language Processing technology to preprocess the data. On this basis, BERT and TF-IDF are used to extract the features of the intention and the multiple text information. Finally, the features are used to train the classifiers. The experimental result on five classifiers (including K-Nearest Neighbor, Naive Bayes, Logistic Regression, Support Vector Machine, and Random Forest) show that our proposed method achieves better performance and its F-Measure achieves from 87.3% to 95.5%.
Rating the Crisis of Online Public Opinion Using a Multi-Level Index System
Jul 29, 2022
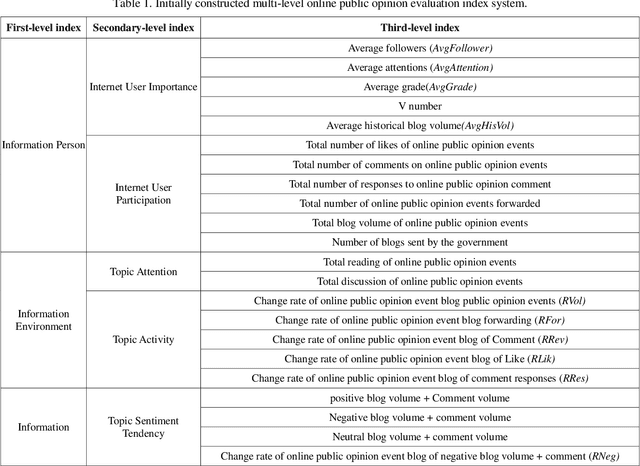
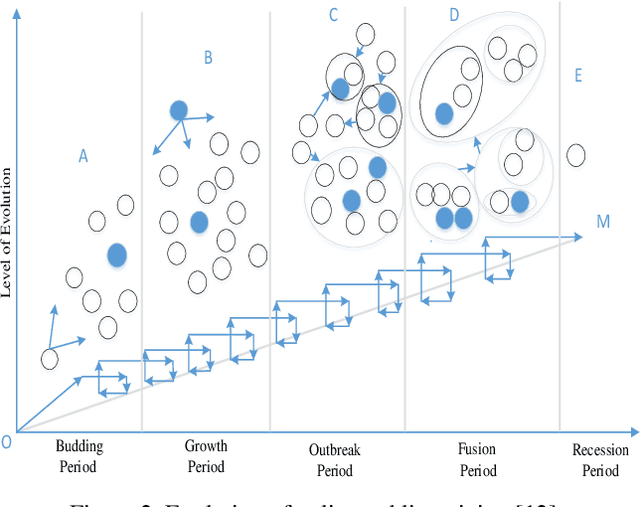
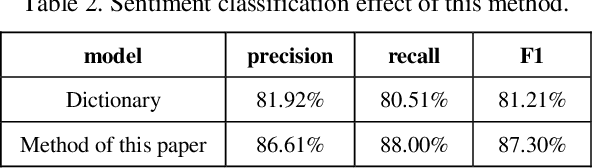
Online public opinion usually spreads rapidly and widely, thus a small incident probably evolves into a large social crisis in a very short time, and results in a heavy loss in credit or economic aspects. We propose a method to rate the crisis of online public opinion based on a multi-level index system to evaluate the impact of events objectively. Firstly, the dissemination mechanism of online public opinion is explained from the perspective of information ecology. According to the mechanism, some evaluation indexes are selected through correlation analysis and principal component analysis. Then, a classification model of text emotion is created via the training by deep learning to achieve the accurate quantification of the emotional indexes in the index system. Finally, based on the multi-level evaluation index system and grey correlation analysis, we propose a method to rate the crisis of online public opinion. The experiment with the real-time incident show that this method can objectively evaluate the emotional tendency of Internet users and rate the crisis in different dissemination stages of online public opinion. It is helpful to realizing the crisis warning of online public opinion and timely blocking the further spread of the crisis.
SeqDialN: Sequential Visual Dialog Networks in Joint Visual-Linguistic Representation Space
Aug 02, 2020
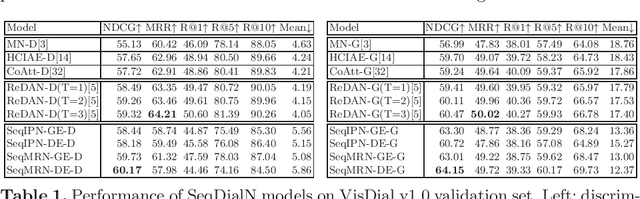
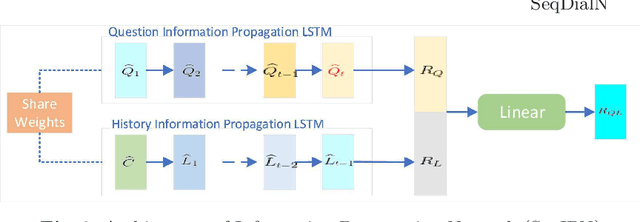

In this work, we formulate a visual dialog as an information flow in which each piece of information is encoded with the joint visual-linguistic representation of a single dialog round. Based on this formulation, we consider the visual dialog task as a sequence problem consisting of ordered visual-linguistic vectors. For featurization, we use a Dense Symmetric Co-Attention network as a lightweight vison-language joint representation generator to fuse multimodal features (i.e., image and text), yielding better computation and data efficiencies. For inference, we propose two Sequential Dialog Networks (SeqDialN): the first uses LSTM for information propagation (IP) and the second uses a modified Transformer for multi-step reasoning (MR). Our architecture separates the complexity of multimodal feature fusion from that of inference, which allows simpler design of the inference engine. IP based SeqDialN is our baseline with a simple 2-layer LSTM design that achieves decent performance. MR based SeqDialN, on the other hand, recurrently refines the semantic question/history representations through the self-attention stack of Transformer and produces promising results on the visual dialog task. On VisDial v1.0 test-std dataset, our best single generative SeqDialN achieves 62.54% NDCG and 48.63% MRR; our ensemble generative SeqDialN achieves 63.78% NDCG and 49.98% MRR, which set a new state-of-the-art generative visual dialog model. We fine-tune discriminative SeqDialN with dense annotations and boost the performance up to 72.41% NDCG and 55.11% MRR. In this work, we discuss the extensive experiments we have conducted to demonstrate the effectiveness of our model components. We also provide visualization for the reasoning process from the relevant conversation rounds and discuss our fine-tuning methods. Our code is available at https://github.com/xiaoxiaoheimei/SeqDialN