 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqDialN: Sequential Visual Dialog Networks in Joint Visual-Linguistic Representation Space
Aug 02, 2020
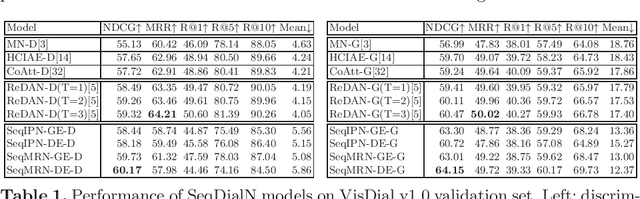
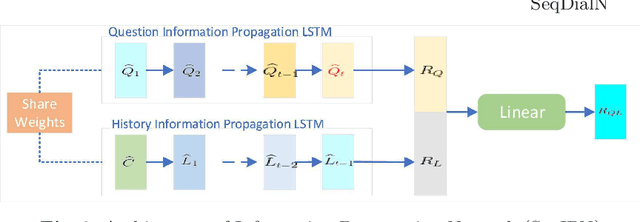

In this work, we formulate a visual dialog as an information flow in which each piece of information is encoded with the joint visual-linguistic representation of a single dialog round. Based on this formulation, we consider the visual dialog task as a sequence problem consisting of ordered visual-linguistic vectors. For featurization, we use a Dense Symmetric Co-Attention network as a lightweight vison-language joint representation generator to fuse multimodal features (i.e., image and text), yielding better computation and data efficiencies. For inference, we propose two Sequential Dialog Networks (SeqDialN): the first uses LSTM for information propagation (IP) and the second uses a modified Transformer for multi-step reasoning (MR). Our architecture separates the complexity of multimodal feature fusion from that of inference, which allows simpler design of the inference engine. IP based SeqDialN is our baseline with a simple 2-layer LSTM design that achieves decent performance. MR based SeqDialN, on the other hand, recurrently refines the semantic question/history representations through the self-attention stack of Transformer and produces promising results on the visual dialog task. On VisDial v1.0 test-std dataset, our best single generative SeqDialN achieves 62.54% NDCG and 48.63% MRR; our ensemble generative SeqDialN achieves 63.78% NDCG and 49.98% MRR, which set a new state-of-the-art generative visual dialog model. We fine-tune discriminative SeqDialN with dense annotations and boost the performance up to 72.41% NDCG and 55.11% MRR. In this work, we discuss the extensive experiments we have conducted to demonstrate the effectiveness of our model components. We also provide visualization for the reasoning process from the relevant conversation rounds and discuss our fine-tuning methods. Our code is available at https://github.com/xiaoxiaoheimei/SeqDialN
Offline Handwritten Chinese Text Recognition with Convolutional Neural Networks
Jun 28, 2020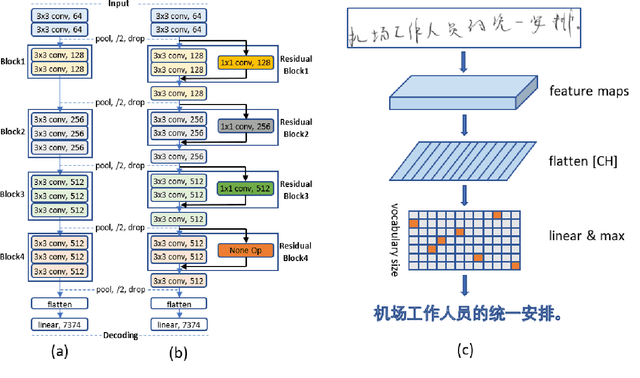
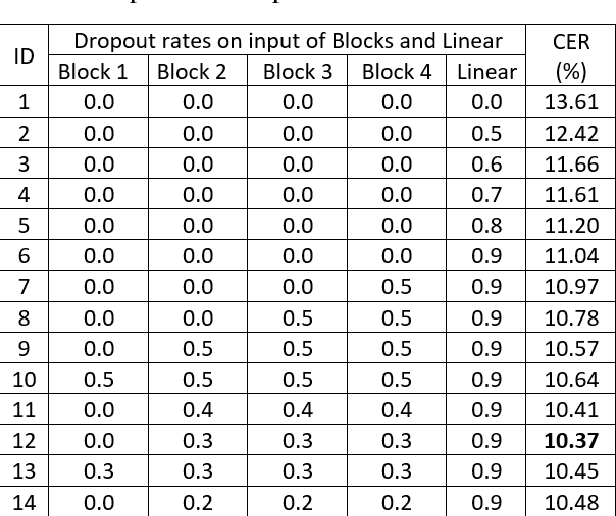
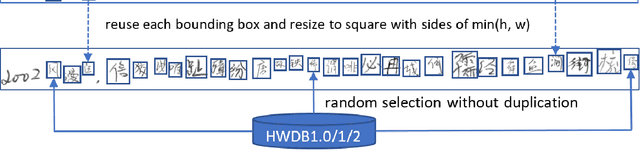
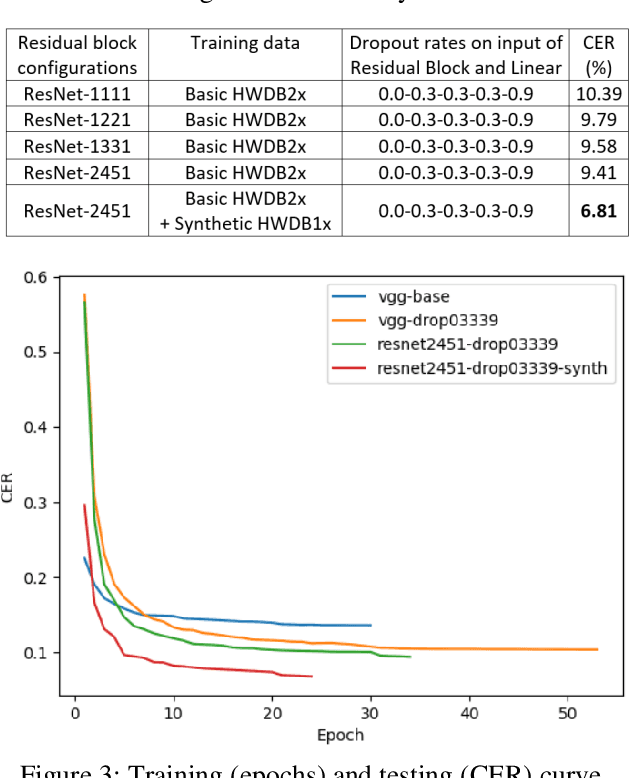
Deep learning based methods have been dominating the text recognition tasks in different and multilingual scenarios. The offline handwritten Chinese text recognition (HCTR) is one of the most challenging tasks because it involves thousands of characters, variant writing styles and complex data collection process. Recently, the recurrent-free architectures for text recognition appears to be competitive as its highly parallelism and comparable results. In this paper, we build the models using only the convolutional neural networks and use CTC as the loss function. To reduce the overfitting, we apply dropout after each max-pooling layer and with extreme high rate on the last one before the linear layer. The CASIA-HWDB database is selected to tune and evaluate the proposed models. With the existing text samples as templates, we randomly choose isolated character samples to synthesis more text samples for training. We finally achieve 6.81% character error rate (CER) on the ICDAR 2013 competition set, which is the best published result without language model correction.