 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniFusion: A Unified Image Fusion Framework with Robust Representation and Source-Aware Preservation
Mar 15, 2026Image fusion aims to integrate complementary information from multiple source images to produce a more informative and visually consistent representation, benefiting both human perception and downstream vision tasks. Despite recent progress, most existing fusion methods are designed for specific tasks (i.e., multi-modal, multi-exposure, or multi-focus fusion) and struggle to effectively preserve source information during the fusion process. This limitation primarily arises from task-specific architectures and the degradation of source information caused by deep-layer propagation. To overcome these issues, we propose UniFusion, a unified image fusion framework designed to achieve cross-task generalization. First, leveraging DINOv3 for modality-consistent feature extraction, UniFusion establishes a shared semantic space for diverse inputs. Second, to preserve the understanding of each source image, we introduce a reconstruction-alignment loss to maintain consistency between fused outputs and inputs. Finally, we employ a bilevel optimization strategy to decouple and jointly optimize reconstruction and fusion objectives, effectively balancing their coupling relationship and ensuring smooth convergence. Extensive experiments across multiple fusion tasks demonstrate UniFusion's superior visual quality, generalization ability, and adaptability to real-world scenarios. Code is available at https://github.com/dusongcheng/UniFusion.
Toward Real-world Infrared Image Super-Resolution: A Unified Autoregressive Framework and Benchmark Dataset
Mar 05, 2026Infrared image super-resolution (IISR) under real-world conditions is a practically significant yet rarely addressed task. Pioneering works are often trained and evaluated on simulated datasets or neglect the intrinsic differences between infrared and visible imaging. In practice, however, real infrared images are affected by coupled optical and sensing degradations that jointly deteriorate both structural sharpness and thermal fidelity. To address these challenges, we propose Real-IISR, a unified autoregressive framework for real-world IISR that progressively reconstructs fine-grained thermal structures and clear backgrounds in a scale-by-scale manner via thermal-structural guided visual autoregression. Specifically, a Thermal-Structural Guidance module encodes thermal priors to mitigate the mismatch between thermal radiation and structural edges. Since non-uniform degradations typically induce quantization bias, Real-IISR adopts a Condition-Adaptive Codebook that dynamically modulates discrete representations based on degradation-aware thermal priors. Also, a Thermal Order Consistency Loss enforces a monotonic relation between temperature and pixel intensity, ensuring relative brightness order rather than absolute values to maintain physical consistency under spatial misalignment and thermal drift. We build FLIR-IISR, a real-world IISR dataset with paired LR-HR infrared images acquired via automated focus variation and motion-induced blur. Extensive experiments demonstrate the promising performance of Real-IISR, providing a unified foundation for real-world IISR and benchmarking. The dataset and code are available at: https://github.com/JZD151/Real-IISR.
Bridging Human Evaluation to Infrared and Visible Image Fusion
Mar 04, 2026Infrared and visible image fusion (IVIF) integrates complementary modalities to enhance scene perception. Current methods predominantly focus on optimizing handcrafted losses and objective metrics, often resulting in fusion outcomes that do not align with human visual preferences. This challenge is further exacerbated by the ill-posed nature of IVIF, which severely limits its effectiveness in human perceptual environments such as security surveillance and driver assistance systems. To address these limitations, we propose a feedback reinforcement framework that bridges human evaluation to infrared and visible image fusion. To address the lack of human-centric evaluation metrics and data, we introduce the first large-scale human feedback dataset for IVIF, containing multidimensional subjective scores and artifact annotations, and enriched by a fine-tuned large language model with expert review. Based on this dataset, we design a domain-specific reward function and train a reward model to quantify perceptual quality. Guided by this reward, we fine-tune the fusion network through Group Relative Policy Optimization, achieving state-of-the-art performance that better aligns fused images with human aesthetics. Code is available at https://github.com/ALKA-Wind/EVAFusion.
Expert-Data Alignment Governs Generation Quality in Decentralized Diffusion Models
Feb 02, 2026Decentralized Diffusion Models (DDMs) route denoising through experts trained independently on disjoint data clusters, which can strongly disagree in their predictions. What governs the quality of generations in such systems? We present the first ever systematic investigation of this question. A priori, the expectation is that minimizing denoising trajectory sensitivity -- minimizing how perturbations amplify during sampling -- should govern generation quality. We demonstrate this hypothesis is incorrect: a stability-quality dissociation. Full ensemble routing, which combines all expert predictions at each step, achieves the most stable sampling dynamics and best numerical convergence while producing the worst generation quality (FID 47.9 vs. 22.6 for sparse Top-2 routing). Instead, we identify expert-data alignment as the governing principle: generation quality depends on routing inputs to experts whose training distribution covers the current denoising state. Across two distinct DDM systems, we validate expert-data alignment using (i) data-cluster distance analysis, confirming sparse routing selects experts with data clusters closest to the current denoising state, and (ii) per-expert analysis, showing selected experts produce more accurate predictions than non-selected ones, and (iii) expert disagreement analysis, showing quality degrades when experts disagree. For DDM deployment, our findings establish that routing should prioritize expert-data alignment over numerical stability metrics.
HATIR: Heat-Aware Diffusion for Turbulent Infrared Video Super-Resolution
Jan 08, 2026Infrared video has been of great interest in visual tasks under challenging environments, but often suffers from severe atmospheric turbulence and compression degradation. Existing video super-resolution (VSR) methods either neglect the inherent modality gap between infrared and visible images or fail to restore turbulence-induced distortions. Directly cascading turbulence mitigation (TM) algorithms with VSR methods leads to error propagation and accumulation due to the decoupled modeling of degradation between turbulence and resolution. We introduce HATIR, a Heat-Aware Diffusion for Turbulent InfraRed Video Super-Resolution, which injects heat-aware deformation priors into the diffusion sampling path to jointly model the inverse process of turbulent degradation and structural detail loss. Specifically, HATIR constructs a Phasor-Guided Flow Estimator, rooted in the physical principle that thermally active regions exhibit consistent phasor responses over time, enabling reliable turbulence-aware flow to guide the reverse diffusion process. To ensure the fidelity of structural recovery under nonuniform distortions, a Turbulence-Aware Decoder is proposed to selectively suppress unstable temporal cues and enhance edge-aware feature aggregation via turbulence gating and structure-aware attention. We built FLIR-IVSR, the first dataset for turbulent infrared VSR, comprising paired LR-HR sequences from a FLIR T1050sc camera (1024 X 768) spanning 640 diverse scenes with varying camera and object motion conditions. This encourages future research in infrared VSR. Project page: https://github.com/JZ0606/HATIR
DifIISR: A Diffusion Model with Gradient Guidance for Infrared Image Super-Resolution
Mar 03, 2025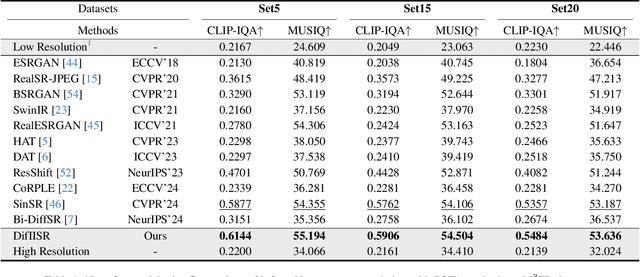
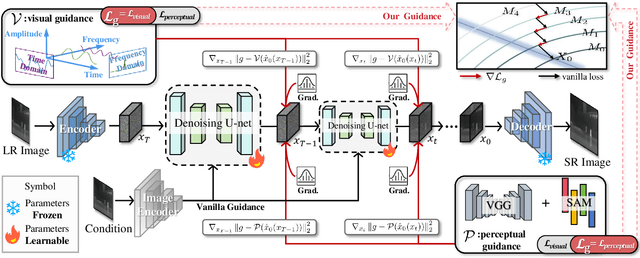


Infrared imaging is essential for autonomous driving and robotic operations as a supportive modality due to its reliable performance in challenging environments. Despite its popularity, the limitations of infrared cameras, such as low spatial resolution and complex degradations, consistently challenge imaging quality and subsequent visual tasks. Hence, infrared image super-resolution (IISR) has been developed to address this challenge. While recent developments in diffusion models have greatly advanced this field, current methods to solve it either ignore the unique modal characteristics of infrared imaging or overlook the machine perception requirements. To bridge these gaps, we propose DifIISR, an infrared image super-resolution diffusion model optimized for visual quality and perceptual performance. Our approach achieves task-based guidance for diffusion by injecting gradients derived from visual and perceptual priors into the noise during the reverse process. Specifically, we introduce an infrared thermal spectrum distribution regulation to preserve visual fidelity, ensuring that the reconstructed infrared images closely align with high-resolution images by matching their frequency components. Subsequently, we incorporate various visual foundational models as the perceptual guidance for downstream visual tasks, infusing generalizable perceptual features beneficial for detection and segmentation. As a result, our approach gains superior visual results while attaining State-Of-The-Art downstream task performance. Code is available at https://github.com/zirui0625/DifIISR
Infrared and Visible Image Fusion: From Data Compatibility to Task Adaption
Jan 18, 2025Infrared-visible image fusion (IVIF) is a critical task in computer vision, aimed at integrating the unique features of both infrared and visible spectra into a unified representation. Since 2018, the field has entered the deep learning era, with an increasing variety of approaches introducing a range of networks and loss functions to enhance visual performance. However, challenges such as data compatibility, perception accuracy, and efficiency remain. Unfortunately, there is a lack of recent comprehensive surveys that address this rapidly expanding domain. This paper fills that gap by providing a thorough survey covering a broad range of topics. We introduce a multi-dimensional framework to elucidate common learning-based IVIF methods, from visual enhancement strategies to data compatibility and task adaptability. We also present a detailed analysis of these approaches, accompanied by a lookup table clarifying their core ideas. Furthermore, we summarize performance comparisons, both quantitatively and qualitatively, focusing on registration, fusion, and subsequent high-level tasks. Beyond technical analysis, we discuss potential future directions and open issues in this area. For further details, visit our GitHub repository: https://github.com/RollingPlain/IVIF_ZOO.
SeFENet: Robust Deep Homography Estimation via Semantic-Driven Feature Enhancement
Dec 09, 2024



Images captured in harsh environments often exhibit blurred details, reduced contrast, and color distortion, which hinder feature detection and matching, thereby affecting the accuracy and robustness of homography estimation. While visual enhancement can improve contrast and clarity, it may introduce visual-tolerant artifacts that obscure the structural integrity of images. Considering the resilience of semantic information against environmental interference, we propose a semantic-driven feature enhancement network for robust homography estimation, dubbed SeFENet. Concretely, we first introduce an innovative hierarchical scale-aware module to expand the receptive field by aggregating multi-scale information, thereby effectively extracting image features under diverse harsh conditions. Subsequently, we propose a semantic-guided constraint module combined with a high-level perceptual framework to achieve degradation-tolerant with semantic feature. A meta-learning-based training strategy is introduced to mitigate the disparity between semantic and structural features. By internal-external alternating optimization, the proposed network achieves implicit semantic-wise feature enhancement, thereby improving the robustness of homography estimation in adverse environments by strengthening the local feature comprehension and context information extraction. Experimental results under both normal and harsh conditions demonstrate that SeFENet significantly outperforms SOTA methods, reducing point match error by at least 41\% on the large-scale datasets.
HUPE: Heuristic Underwater Perceptual Enhancement with Semantic Collaborative Learning
Nov 29, 2024Underwater images are often affected by light refraction and absorption, reducing visibility and interfering with subsequent applications. Existing underwater image enhancement methods primarily focus on improving visual quality while overlooking practical implications. To strike a balance between visual quality and application, we propose a heuristic invertible network for underwater perception enhancement, dubbed HUPE, which enhances visual quality and demonstrates flexibility in handling other downstream tasks. Specifically, we introduced an information-preserving reversible transformation with embedded Fourier transform to establish a bidirectional mapping between underwater images and their clear images. Additionally, a heuristic prior is incorporated into the enhancement process to better capture scene information. To further bridge the feature gap between vision-based enhancement images and application-oriented images, a semantic collaborative learning module is applied in the joint optimization process of the visual enhancement task and the downstream task, which guides the proposed enhancement model to extract more task-oriented semantic features while obtaining visually pleasing images. Extensive experiments, both quantitative and qualitative, demonstrate the superiority of our HUPE over state-of-the-art methods. The source code is available at https://github.com/ZengxiZhang/HUPE.
Towards Robust Image Stitching: An Adaptive Resistance Learning against Compatible Attacks
Feb 25, 2024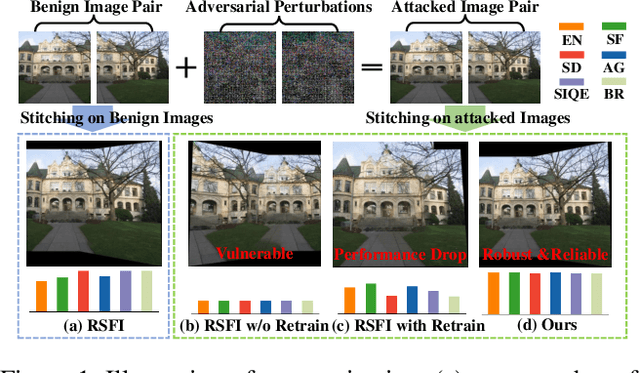
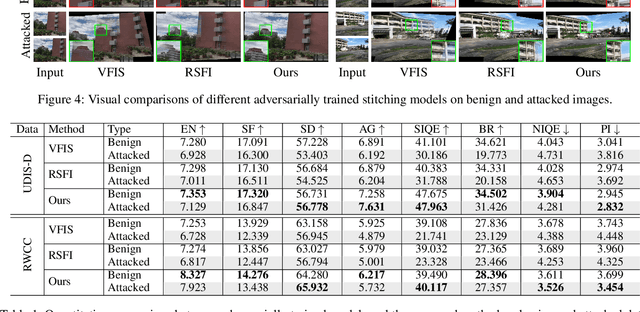
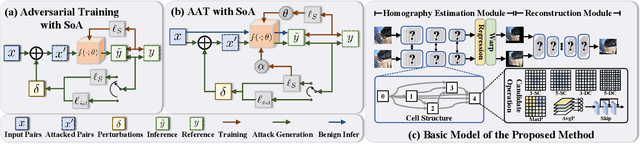

Image stitching seamlessly integrates images captured from varying perspectives into a single wide field-of-view image. Such integration not only broadens the captured scene but also augments holistic perception in computer vision applications. Given a pair of captured images, subtle perturbations and distortions which go unnoticed by the human visual system tend to attack the correspondence matching, impairing the performance of image stitching algorithms. In light of this challenge, this paper presents the first attempt to improve the robustness of image stitching against adversarial attacks. Specifically, we introduce a stitching-oriented attack~(SoA), tailored to amplify the alignment loss within overlapping regions, thereby targeting the feature matching procedure. To establish an attack resistant model, we delve into the robustness of stitching architecture and develop an adaptive adversarial training~(AAT) to balance attack resistance with stitching precision. In this way, we relieve the gap between the routine adversarial training and benign models, ensuring resilience without quality compromise. Comprehensive evaluation across real-world and synthetic datasets validate the deterioration of SoA on stitching performance. Furthermore, AAT emerges as a more robust solution against adversarial perturbations, delivering superior stitching results. Code is available at:https://github.com/Jzy2017/TRIS.