 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeFENet: Robust Deep Homography Estimation via Semantic-Driven Feature Enhancement
Dec 09, 2024



Images captured in harsh environments often exhibit blurred details, reduced contrast, and color distortion, which hinder feature detection and matching, thereby affecting the accuracy and robustness of homography estimation. While visual enhancement can improve contrast and clarity, it may introduce visual-tolerant artifacts that obscure the structural integrity of images. Considering the resilience of semantic information against environmental interference, we propose a semantic-driven feature enhancement network for robust homography estimation, dubbed SeFENet. Concretely, we first introduce an innovative hierarchical scale-aware module to expand the receptive field by aggregating multi-scale information, thereby effectively extracting image features under diverse harsh conditions. Subsequently, we propose a semantic-guided constraint module combined with a high-level perceptual framework to achieve degradation-tolerant with semantic feature. A meta-learning-based training strategy is introduced to mitigate the disparity between semantic and structural features. By internal-external alternating optimization, the proposed network achieves implicit semantic-wise feature enhancement, thereby improving the robustness of homography estimation in adverse environments by strengthening the local feature comprehension and context information extraction. Experimental results under both normal and harsh conditions demonstrate that SeFENet significantly outperforms SOTA methods, reducing point match error by at least 41\% on the large-scale datasets.
HUPE: Heuristic Underwater Perceptual Enhancement with Semantic Collaborative Learning
Nov 29, 2024Underwater images are often affected by light refraction and absorption, reducing visibility and interfering with subsequent applications. Existing underwater image enhancement methods primarily focus on improving visual quality while overlooking practical implications. To strike a balance between visual quality and application, we propose a heuristic invertible network for underwater perception enhancement, dubbed HUPE, which enhances visual quality and demonstrates flexibility in handling other downstream tasks. Specifically, we introduced an information-preserving reversible transformation with embedded Fourier transform to establish a bidirectional mapping between underwater images and their clear images. Additionally, a heuristic prior is incorporated into the enhancement process to better capture scene information. To further bridge the feature gap between vision-based enhancement images and application-oriented images, a semantic collaborative learning module is applied in the joint optimization process of the visual enhancement task and the downstream task, which guides the proposed enhancement model to extract more task-oriented semantic features while obtaining visually pleasing images. Extensive experiments, both quantitative and qualitative, demonstrate the superiority of our HUPE over state-of-the-art methods. The source code is available at https://github.com/ZengxiZhang/HUPE.
Dual Adversarial Resilience for Collaborating Robust Underwater Image Enhancement and Perception
Sep 03, 2023



Due to the uneven scattering and absorption of different light wavelengths in aquatic environments, underwater images suffer from low visibility and clear color deviations. With the advancement of autonomous underwater vehicles, extensive research has been conducted on learning-based underwater enhancement algorithms. These works can generate visually pleasing enhanced images and mitigate the adverse effects of degraded images on subsequent perception tasks. However, learning-based methods are susceptible to the inherent fragility of adversarial attacks, causing significant disruption in results. In this work, we introduce a collaborative adversarial resilience network, dubbed CARNet, for underwater image enhancement and subsequent detection tasks. Concretely, we first introduce an invertible network with strong perturbation-perceptual abilities to isolate attacks from underwater images, preventing interference with image enhancement and perceptual tasks. Furthermore, we propose a synchronized attack training strategy with both visual-driven and perception-driven attacks enabling the network to discern and remove various types of attacks. Additionally, we incorporate an attack pattern discriminator to heighten the robustness of the network against different attacks. Extensive experiments demonstrate that the proposed method outputs visually appealing enhancement images and perform averagely 6.71% higher detection mAP than state-of-the-art methods.
WaterFlow: Heuristic Normalizing Flow for Underwater Image Enhancement and Beyond
Aug 02, 2023
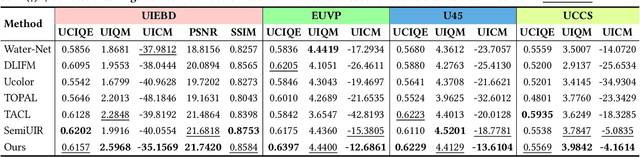


Underwater images suffer from light refraction and absorption, which impairs visibility and interferes the subsequent applications. Existing underwater image enhancement methods mainly focus on image quality improvement, ignoring the effect on practice. To balance the visual quality and application, we propose a heuristic normalizing flow for detection-driven underwater image enhancement, dubbed WaterFlow. Specifically, we first develop an invertible mapping to achieve the translation between the degraded image and its clear counterpart. Considering the differentiability and interpretability, we incorporate the heuristic prior into the data-driven mapping procedure, where the ambient light and medium transmission coefficient benefit credible generation. Furthermore, we introduce a detection perception module to transmit the implicit semantic guidance into the enhancement procedure, where the enhanced images hold more detection-favorable features and are able to promote the detection performance. Extensive experiments prove the superiority of our WaterFlow, against state-of-the-art methods quantitatively and qualitatively.
Multi-Spectral Image Stitching via Spatial Graph Reasoning
Jul 31, 2023



Multi-spectral image stitching leverages the complementarity between infrared and visible images to generate a robust and reliable wide field-of-view (FOV) scene. The primary challenge of this task is to explore the relations between multi-spectral images for aligning and integrating multi-view scenes. Capitalizing on the strengths of Graph Convolutional Networks (GCNs) in modeling feature relationships, we propose a spatial graph reasoning based multi-spectral image stitching method that effectively distills the deformation and integration of multi-spectral images across different viewpoints. To accomplish this, we embed multi-scale complementary features from the same view position into a set of nodes. The correspondence across different views is learned through powerful dense feature embeddings, where both inter- and intra-correlations are developed to exploit cross-view matching and enhance inner feature disparity. By introducing long-range coherence along spatial and channel dimensions, the complementarity of pixel relations and channel interdependencies aids in the reconstruction of aligned multi-view features, generating informative and reliable wide FOV scenes. Moreover, we release a challenging dataset named ChaMS, comprising both real-world and synthetic sets with significant parallax, providing a new option for comprehensive evaluation. Extensive experiments demonstrate that our method surpasses the state-of-the-arts.
Contrastive Learning Based Recursive Dynamic Multi-Scale Network for Image Deraining
May 29, 2023Rain streaks significantly decrease the visibility of captured images and are also a stumbling block that restricts the performance of subsequent computer vision applications. The existing deep learning-based image deraining methods employ manually crafted networks and learn a straightforward projection from rainy images to clear images. In pursuit of better deraining performance, they focus on elaborating a more complicated architecture rather than exploiting the intrinsic properties of the positive and negative information. In this paper, we propose a contrastive learning-based image deraining method that investigates the correlation between rainy and clear images and leverages a contrastive prior to optimize the mutual information of the rainy and restored counterparts. Given the complex and varied real-world rain patterns, we develop a recursive mechanism. It involves multi-scale feature extraction and dynamic cross-level information recruitment modules. The former advances the portrayal of diverse rain patterns more precisely, while the latter can selectively compensate high-level features for shallow-level information. We term the proposed recursive dynamic multi-scale network with a contrastive prior, RDMC. Extensive experiments on synthetic benchmarks and real-world images demonstrate that the proposed RDMC delivers strong performance on the depiction of rain streaks and outperforms the state-of-the-art methods. Moreover, a practical evaluation of object detection and semantic segmentation shows the effectiveness of the proposed method.
Modality-Invariant Representation for Infrared and Visible Image Registration
Apr 12, 2023Since the differences in viewing range, resolution and relative position, the multi-modality sensing module composed of infrared and visible cameras needs to be registered so as to have more accurate scene perception. In practice, manual calibration-based registration is the most widely used process, and it is regularly calibrated to maintain accuracy, which is time-consuming and labor-intensive. To cope with these problems, we propose a scene-adaptive infrared and visible image registration. Specifically, in regard of the discrepancy between multi-modality images, an invertible translation process is developed to establish a modality-invariant domain, which comprehensively embraces the feature intensity and distribution of both infrared and visible modalities. We employ homography to simulate the deformation between different planes and develop a hierarchical framework to rectify the deformation inferred from the proposed latent representation in a coarse-to-fine manner. For that, the advanced perception ability coupled with the residual estimation conducive to the regression of sparse offsets, and the alternate correlation search facilitates a more accurate correspondence matching. Moreover, we propose the first ground truth available misaligned infrared and visible image dataset, involving three synthetic sets and one real-world set. Extensive experiments validate the effectiveness of the proposed method against the state-of-the-arts, advancing the subsequent applications.