 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactNet: A Billion-Scale Knowledge Graph for Multilingual Factual Grounding
Feb 03, 2026While LLMs exhibit remarkable fluency, their utility is often compromised by factual hallucinations and a lack of traceable provenance. Existing resources for grounding mitigate this but typically enforce a dichotomy: they offer either structured knowledge without textual context (e.g., knowledge bases) or grounded text with limited scale and linguistic coverage. To bridge this gap, we introduce FactNet, a massive, open-source resource designed to unify 1.7 billion atomic assertions with 3.01 billion auditable evidence pointers derived exclusively from 316 Wikipedia editions. Unlike recent synthetic approaches, FactNet employs a strictly deterministic construction pipeline, ensuring that every evidence unit is recoverable with byte-level precision. Extensive auditing confirms a high grounding precision of 92.1%, even in long-tail languages. Furthermore, we establish FactNet-Bench, a comprehensive evaluation suite for Knowledge Graph Completion, Question Answering, and Fact Checking. FactNet provides the community with a foundational, reproducible resource for training and evaluating trustworthy, verifiable multilingual systems.
From Unaligned to Aligned: Scaling Multilingual LLMs with Multi-Way Parallel Corpora
May 20, 2025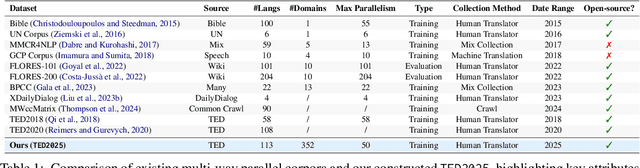

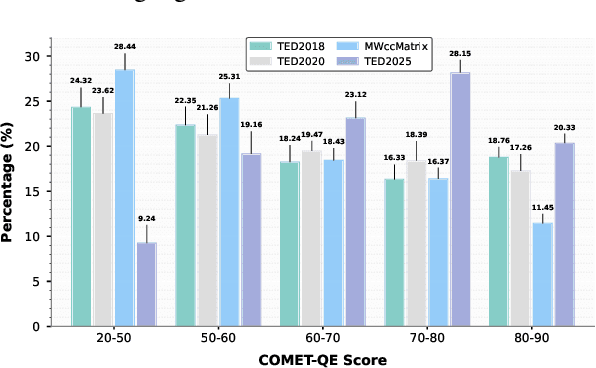
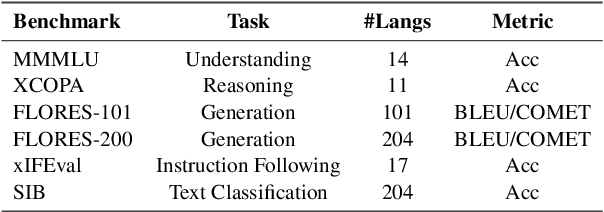
Continued pretraining and instruction tuning on large-scale multilingual data have proven to be effective in scaling large language models (LLMs) to low-resource languages. However, the unaligned nature of such data limits its ability to effectively capture cross-lingual semantics. In contrast, multi-way parallel data, where identical content is aligned across multiple languages, provides stronger cross-lingual consistency and offers greater potential for improving multilingual performance. In this paper, we introduce a large-scale, high-quality multi-way parallel corpus, TED2025, based on TED Talks. The corpus spans 113 languages, with up to 50 languages aligned in parallel, ensuring extensive multilingual coverage. Using this dataset, we investigate best practices for leveraging multi-way parallel data to enhance LLMs, including strategies for continued pretraining, instruction tuning, and the analysis of key influencing factors. Experiments on six multilingual benchmarks show that models trained on multiway parallel data consistently outperform those trained on unaligned multilingual data.
DCAD-2000: A Multilingual Dataset across 2000+ Languages with Data Cleaning as Anomaly Detection
Feb 17, 2025The rapid development of multilingual large language models (LLMs) highlights the need for high-quality, diverse, and clean multilingual datasets. In this paper, we introduce DCAD-2000 (Data Cleaning as Anomaly Detection), a large-scale multilingual corpus built using newly extracted Common Crawl data and existing multilingual datasets. DCAD-2000 includes over 2,282 languages, 46.72TB of data, and 8.63 billion documents, spanning 155 high- and medium-resource languages and 159 writing scripts. To overcome the limitations of current data cleaning methods, which rely on manual heuristic thresholds, we propose reframing data cleaning as an anomaly detection task. This dynamic filtering approach significantly enhances data quality by identifying and removing noisy or anomalous content. We evaluate the quality of DCAD-2000 on the FineTask benchmark, demonstrating substantial improvements in multilingual dataset quality and task performance.
Joint Localization and Activation Editing for Low-Resource Fine-Tuning
Feb 03, 2025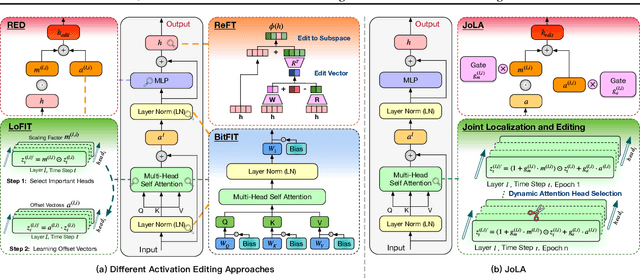
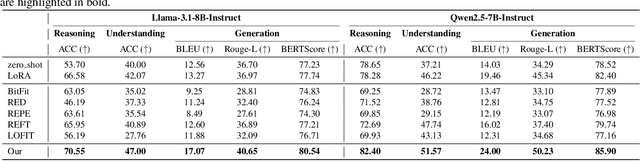
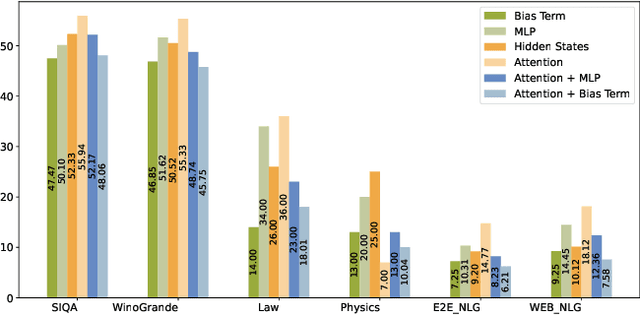
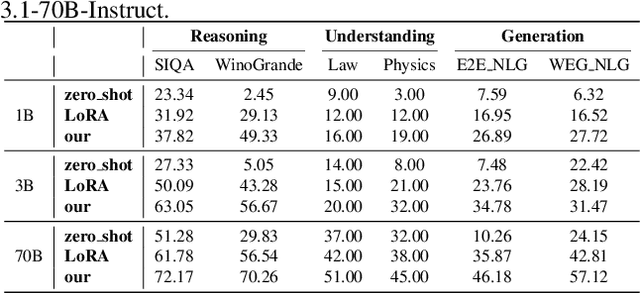
Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, are commonly used to adapt LLMs. However, the effectiveness of standard PEFT methods is limited in low-resource scenarios with only a few hundred examples. Recent advances in interpretability research have inspired the emergence of activation editing techniques, which modify the activations of specific model components. These methods, due to their extremely small parameter counts, show promise for small datasets. However, their performance is highly dependent on identifying the correct modules to edit and often lacks stability across different datasets. In this paper, we propose Joint Localization and Activation Editing (JoLA), a method that jointly learns (1) which heads in the Transformer to edit (2) whether the intervention should be additive, multiplicative, or both and (3) the intervention parameters themselves - the vectors applied as additive offsets or multiplicative scalings to the head output. Through evaluations on three benchmarks spanning commonsense reasoning, natural language understanding, and natural language generation, we demonstrate that JoLA consistently outperforms existing methods.
Style-Specific Neurons for Steering LLMs in Text Style Transfer
Oct 01, 2024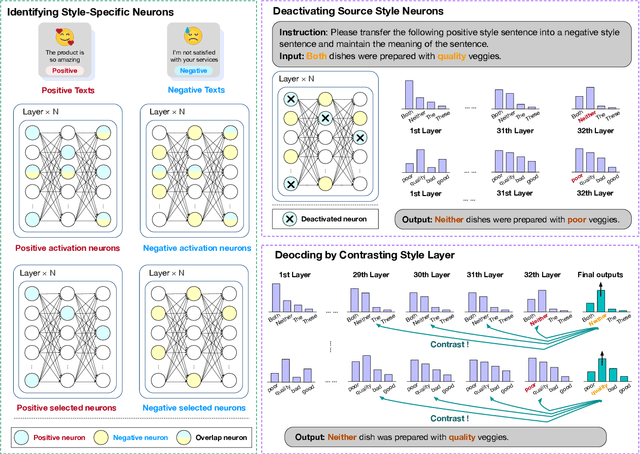
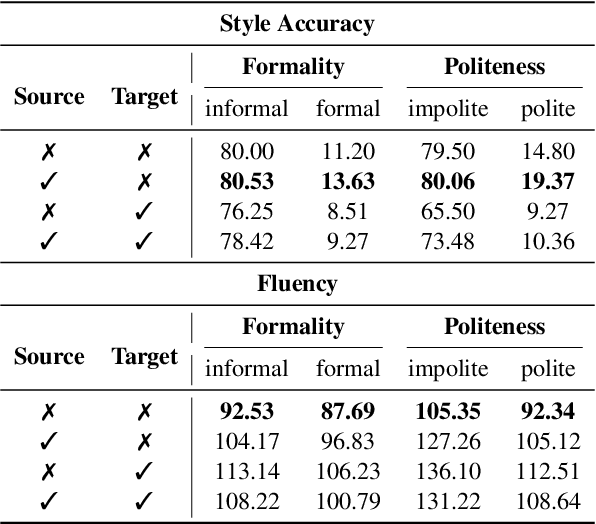
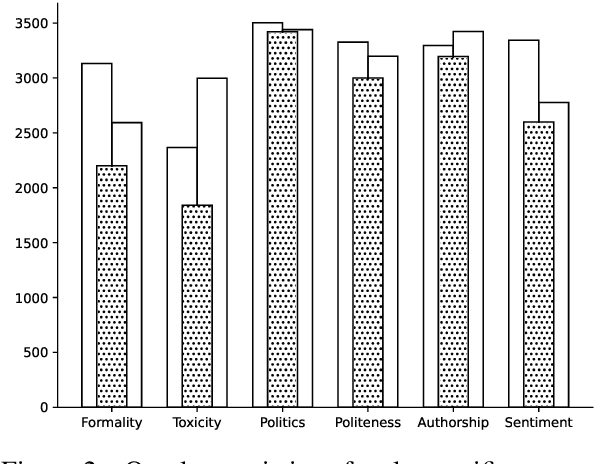
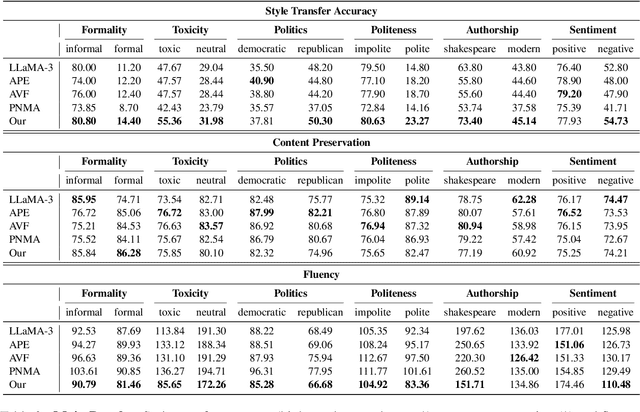
Text style transfer (TST) aims to modify the style of a text without altering its original meaning. Large language models (LLMs) demonstrate superior performance across multiple tasks, including TST. However, in zero-shot setups, they tend to directly copy a significant portion of the input text to the output without effectively changing its style. To enhance the stylistic variety and fluency of the text, we present sNeuron-TST, a novel approach for steering LLMs using style-specific neurons in TST. Specifically, we identify neurons associated with the source and target styles and deactivate source-style-only neurons to give target-style words a higher probability, aiming to enhance the stylistic diversity of the generated text. However, we find that this deactivation negatively impacts the fluency of the generated text, which we address by proposing an improved contrastive decoding method that accounts for rapid token probability shifts across layers caused by deactivated source-style neurons. Empirical experiments demonstrate the effectiveness of the proposed method on six benchmarks, encompassing formality, toxicity, politics, politeness, authorship, and sentiment.
LLMs Beyond English: Scaling the Multilingual Capability of LLMs with Cross-Lingual Feedback
Jun 03, 2024
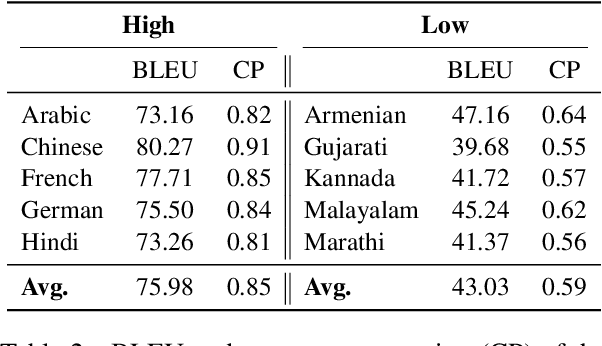
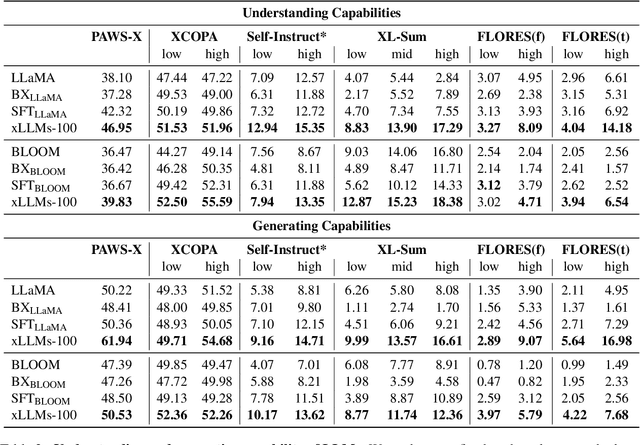
To democratize large language models (LLMs) to most natural languages, it is imperative to make these models capable of understanding and generating texts in many languages, in particular low-resource ones. While recent multilingual LLMs demonstrate remarkable performance in such capabilities, these LLMs still support a limited number of human languages due to the lack of training data for low-resource languages. Moreover, these LLMs are not yet aligned with human preference for downstream tasks, which is crucial for the success of LLMs in English. In this paper, we introduce xLLaMA-100 and xBLOOM-100 (collectively xLLMs-100), which scale the multilingual capabilities of LLaMA and BLOOM to 100 languages. To do so, we construct two datasets: a multilingual instruction dataset including 100 languages, which represents the largest language coverage to date, and a cross-lingual human feedback dataset encompassing 30 languages. We perform multilingual instruction tuning on the constructed instruction data and further align the LLMs with human feedback using the DPO algorithm on our cross-lingual human feedback dataset. We evaluate the multilingual understanding and generating capabilities of xLLMs-100 on five multilingual benchmarks. Experimental results show that xLLMs-100 consistently outperforms its peers across the benchmarks by considerable margins, defining a new state-of-the-art multilingual LLM that supports 100 languages.
Extending Multilingual Machine Translation through Imitation Learning
Nov 14, 2023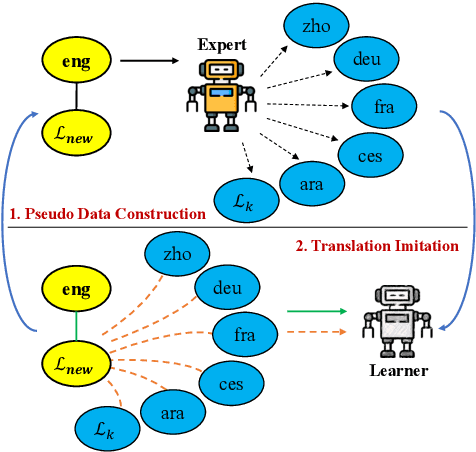
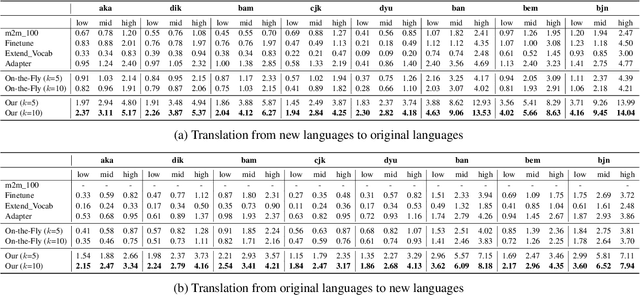
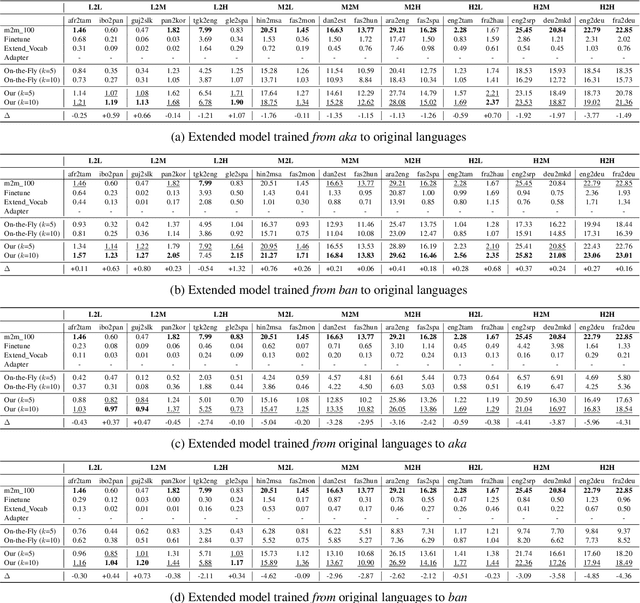
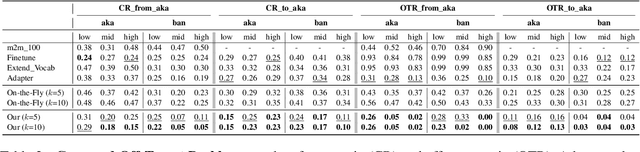
Despite the growing variety of languages supported by existing multilingual neural machine translation (MNMT) models, most of the world's languages are still being left behind. We aim to extend large-scale MNMT models to a new language, allowing for translation between the newly added and all of the already supported languages in a challenging scenario: using only a parallel corpus between the new language and English. Previous approaches, such as continued training on parallel data including the new language, suffer from catastrophic forgetting (i.e., performance on other languages is reduced). Our novel approach Imit-MNMT treats the task as an imitation learning process, which mimicks the behavior of an expert, a technique widely used in the computer vision area, but not well explored in NLP. More specifically, we construct a pseudo multi-parallel corpus of the new and the original languages by pivoting through English, and imitate the output distribution of the original MNMT model. Extensive experiments show that our approach significantly improves the translation performance between the new and the original languages, without severe catastrophic forgetting. We also demonstrate that our approach is capable of solving copy and off-target problems, which are two common issues existence in current large-scale MNMT models.
Mitigating Data Imbalance and Representation Degeneration in Multilingual Machine Translation
May 22, 2023



Despite advances in multilingual neural machine translation (MNMT), we argue that there are still two major challenges in this area: data imbalance and representation degeneration. The data imbalance problem refers to the imbalance in the amount of parallel corpora for all language pairs, especially for long-tail languages (i.e., very low-resource languages). The representation degeneration problem refers to the problem of encoded tokens tending to appear only in a small subspace of the full space available to the MNMT model. To solve these two issues, we propose Bi-ACL, a framework that uses only target-side monolingual data and a bilingual dictionary to improve the performance of the MNMT model. We define two modules, named bidirectional autoencoder and bidirectional contrastive learning, which we combine with an online constrained beam search and a curriculum learning sampling strategy. Extensive experiments show that our proposed method is more effective both in long-tail languages and in high-resource languages. We also demonstrate that our approach is capable of transferring knowledge between domains and languages in zero-shot scenarios.
Improving both domain robustness and domain adaptability in machine translation
Dec 15, 2021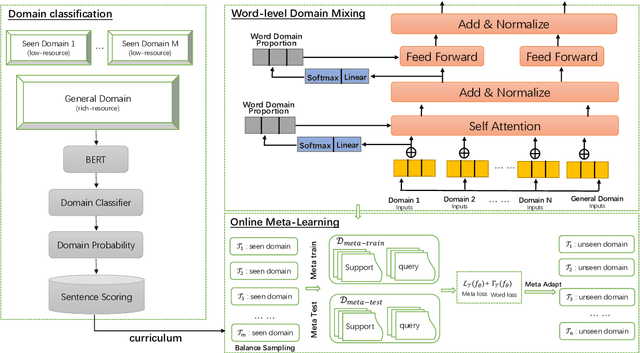

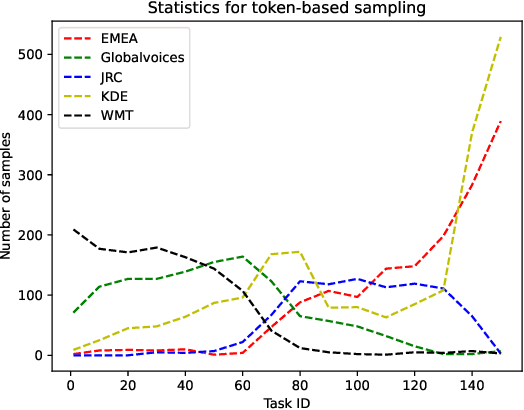

We address two problems of domain adaptation in neural machine translation. First, we want to reach domain robustness, i.e., good quality of both domains from the training data, and domains unseen in the training data. Second, we want our systems to be adaptive, i.e., making it possible to finetune systems with just hundreds of in-domain parallel sentences. In this paper, we introduce a novel combination of two previous approaches, word adaptive modelling, which addresses domain robustness, and meta-learning, which addresses domain adaptability, and we present empirical results showing that our new combination improves both of these properties.