 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Multilingual Machine Translation through Imitation Learning
Paper and Code
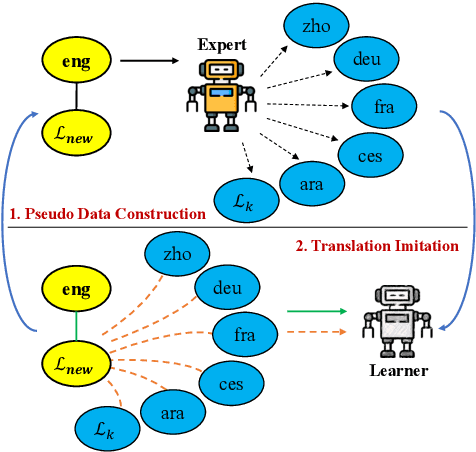
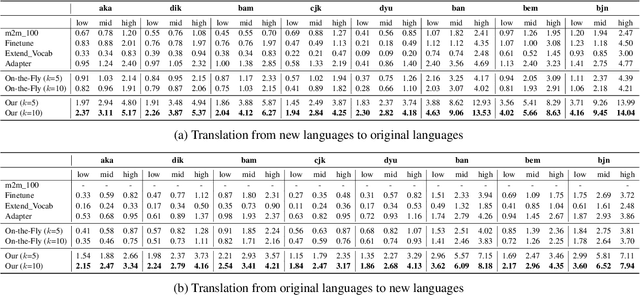
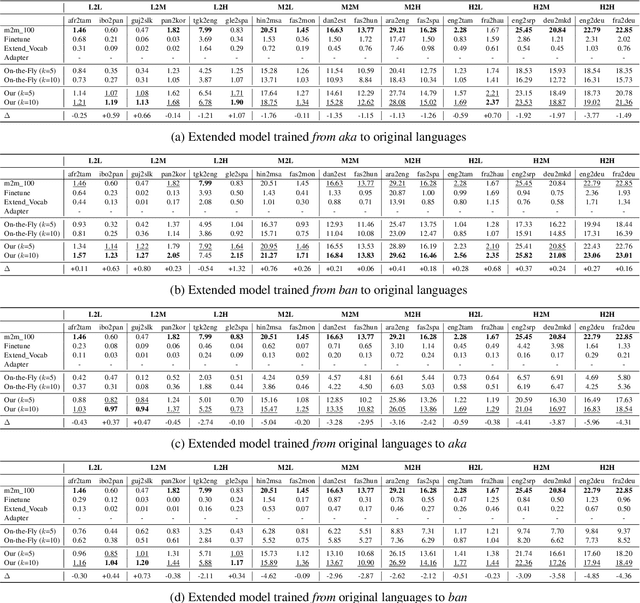
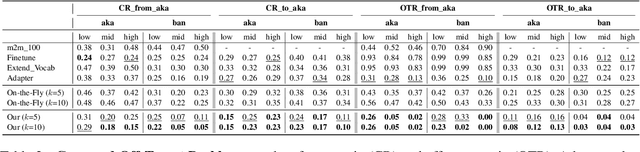
Despite the growing variety of languages supported by existing multilingual neural machine translation (MNMT) models, most of the world's languages are still being left behind. We aim to extend large-scale MNMT models to a new language, allowing for translation between the newly added and all of the already supported languages in a challenging scenario: using only a parallel corpus between the new language and English. Previous approaches, such as continued training on parallel data including the new language, suffer from catastrophic forgetting (i.e., performance on other languages is reduced). Our novel approach Imit-MNMT treats the task as an imitation learning process, which mimicks the behavior of an expert, a technique widely used in the computer vision area, but not well explored in NLP. More specifically, we construct a pseudo multi-parallel corpus of the new and the original languages by pivoting through English, and imitate the output distribution of the original MNMT model. Extensive experiments show that our approach significantly improves the translation performance between the new and the original languages, without severe catastrophic forgetting. We also demonstrate that our approach is capable of solving copy and off-target problems, which are two common issues existence in current large-scale MNMT models.