Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving both domain robustness and domain adaptability in machine translation
Paper and Code
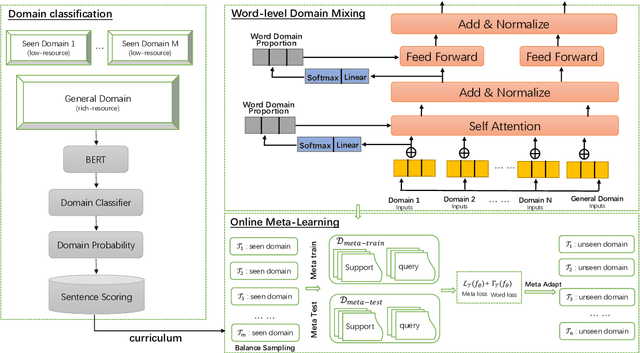

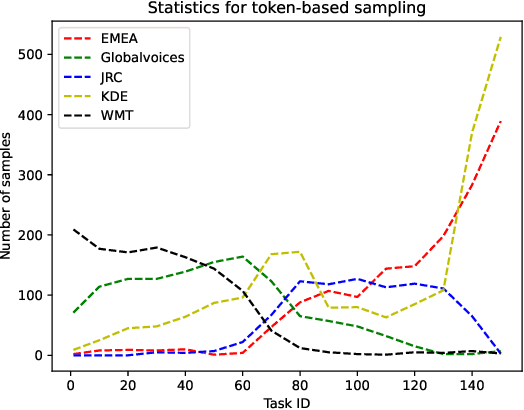

We address two problems of domain adaptation in neural machine translation. First, we want to reach domain robustness, i.e., good quality of both domains from the training data, and domains unseen in the training data. Second, we want our systems to be adaptive, i.e., making it possible to finetune systems with just hundreds of in-domain parallel sentences. In this paper, we introduce a novel combination of two previous approaches, word adaptive modelling, which addresses domain robustness, and meta-learning, which addresses domain adaptability, and we present empirical results showing that our new combination improves both of these properties.
View paper on