 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Grasp Prediction with Visual-Language Inputs
Paper and Code
Feb 28, 2023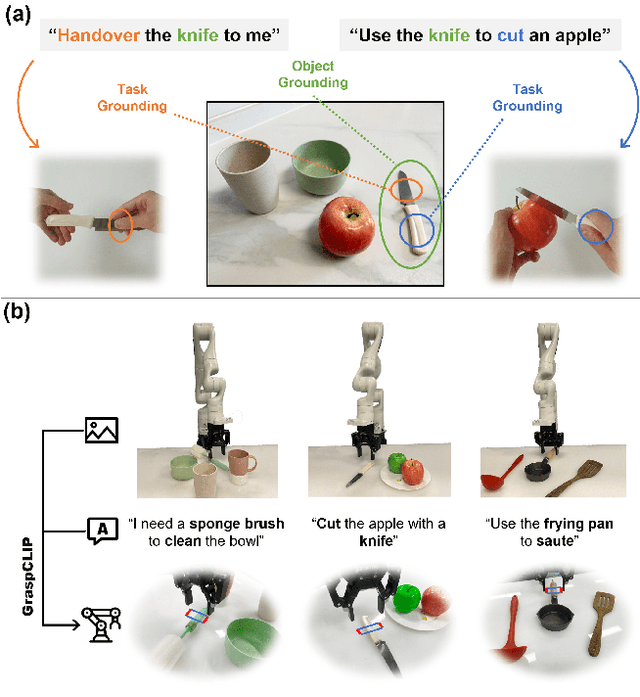
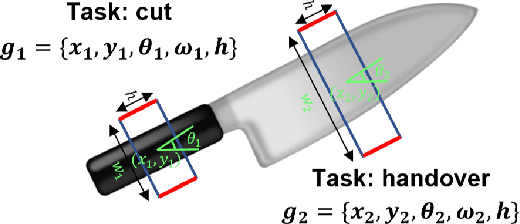
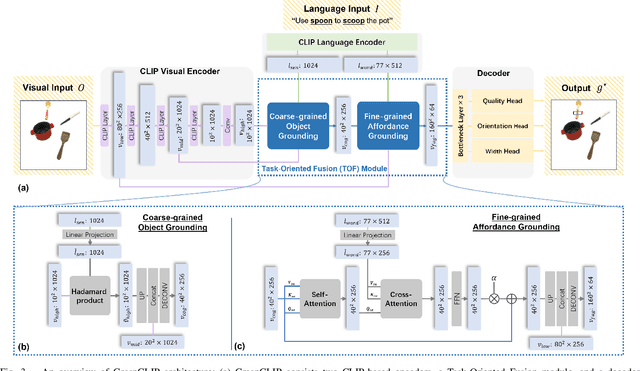
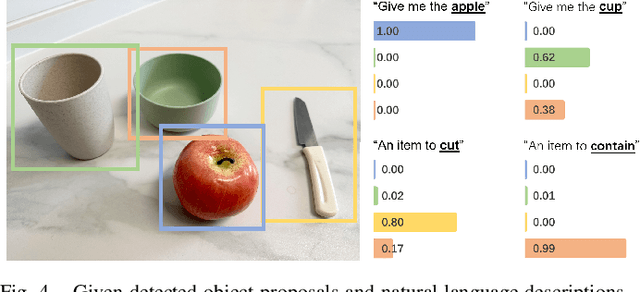
To perform household tasks, assistive robots receive commands in the form of user language instructions for tool manipulation. The initial stage involves selecting the intended tool (i.e., object grounding) and grasping it in a task-oriented manner (i.e., task grounding). Nevertheless, prior researches on visual-language grasping (VLG) focus on object grounding, while disregarding the fine-grained impact of tasks on object grasping. Task-incompatible grasping of a tool will inevitably limit the success of subsequent manipulation steps. Motivated by this problem, this paper proposes GraspCLIP, which addresses the challenge of task grounding in addition to object grounding to enable task-oriented grasp prediction with visual-language inputs. Evaluation on a custom dataset demonstrates that GraspCLIP achieves superior performance over established baselines with object grounding only. The effectiveness of the proposed method is further validated on an assistive robotic arm platform for grasping previously unseen kitchen tools given the task specification. Our presentation video is available at: https://www.youtube.com/watch?v=e1wfYQPeAXU.