 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow many labeled license plates are needed?
Aug 25, 2018
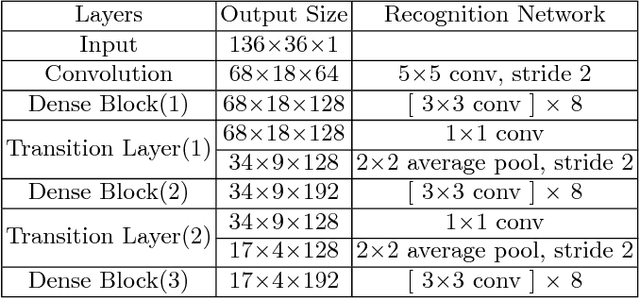

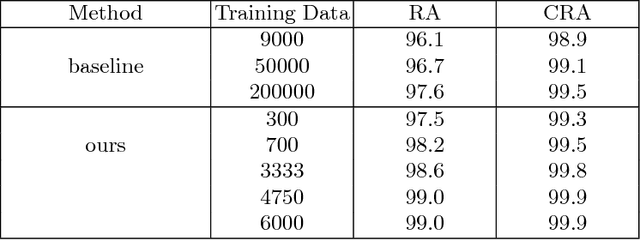
Training a good deep learning model often requires a lot of annotated data. As a large amount of labeled data is typically difficult to collect and even more difficult to annotate, data augmentation and data generation are widely used in the process of training deep neural networks. However, there is no clear common understanding on how much labeled data is needed to get satisfactory performance. In this paper, we try to address such a question using vehicle license plate character recognition as an example application. We apply computer graphic scripts and Generative Adversarial Networks to generate and augment a large number of annotated, synthesized license plate images with realistic colors, fonts, and character composition from a small number of real, manually labeled license plate images. Generated and augmented data are mixed and used as training data for the license plate recognition network modified from DenseNet. The experimental results show that the model trained from the generated mixed training data has good generalization ability, and the proposed approach achieves a new state-of-the-art accuracy on Dataset-1 and AOLP, even with a very limited number of original real license plates. In addition, the accuracy improvement caused by data generation becomes more significant when the number of labeled images is reduced. Data augmentation also plays a more significant role when the number of labeled images is increased.
Collaborative Learning for Deep Neural Networks
May 30, 2018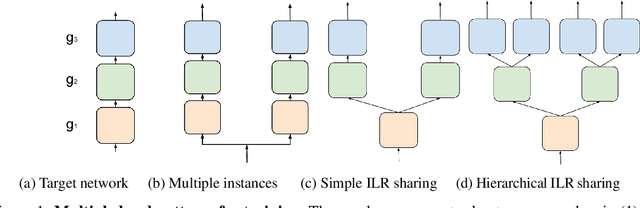

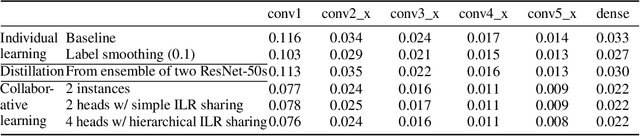
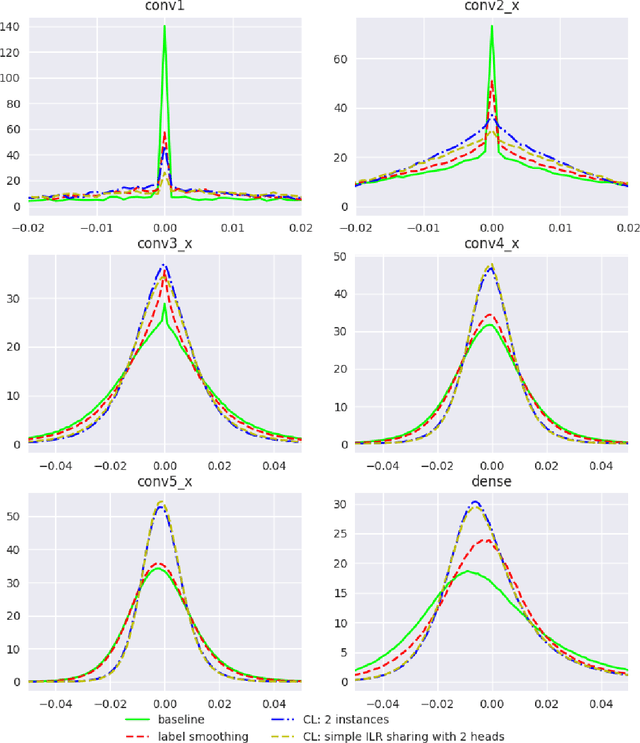
We introduce collaborative learning in which multiple classifier heads of the same network are simultaneously trained on the same training data to improve generalization and robustness to label noise with no extra inference cost. It acquires the strengths from auxiliary training, multi-task learning and knowledge distillation. There are two important mechanisms involved in collaborative learning. First, the consensus of multiple views from different classifier heads on the same example provides supplementary information as well as regularization to each classifier, thereby improving generalization. Second, intermediate-level representation (ILR) sharing with backpropagation rescaling aggregates the gradient flows from all heads, which not only reduces training computational complexity, but also facilitates supervision to the shared layers. The empirical results on CIFAR and ImageNet datasets demonstrate that deep neural networks learned as a group in a collaborative way significantly reduce the generalization error and increase the robustness to label noise.