 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Orthogonality Regularization with Disentangled Norm in Training Deep CNNs
Jun 16, 2023



Orthogonality regularization has been developed to prevent deep CNNs from training instability and feature redundancy. Among existing proposals, kernel orthogonality regularization enforces orthogonality by minimizing the residual between the Gram matrix formed by convolutional filters and the orthogonality matrix. We propose a novel measure for achieving better orthogonality among filters, which disentangles diagonal and correlation information from the residual. The model equipped with the measure under the principle of imposing strict orthogonality between filters surpasses previous regularization methods in near-orthogonality. Moreover, we observe the benefits of improved strict filter orthogonality in relatively shallow models, but as model depth increases, the performance gains in models employing strict kernel orthogonality decrease sharply. Furthermore, based on the observation of the potential conflict between strict kernel orthogonality and growing model capacity, we propose a relaxation theory on kernel orthogonality regularization. The relaxed kernel orthogonality achieves enhanced performance on models with increased capacity, shedding light on the burden of strict kernel orthogonality on deep model performance. We conduct extensive experiments with our kernel orthogonality regularization toolkit on ResNet and WideResNet in CIFAR-10 and CIFAR-100. We observe state-of-the-art gains in model performance from the toolkit, which includes both strict orthogonality and relaxed orthogonality regularization, and obtain more robust models with expressive features. These experiments demonstrate the efficacy of our toolkit and subtly provide insights into the often overlooked challenges posed by strict orthogonality, addressing the burden of strict orthogonality on capacity-rich models.
How many labeled license plates are needed?
Aug 25, 2018
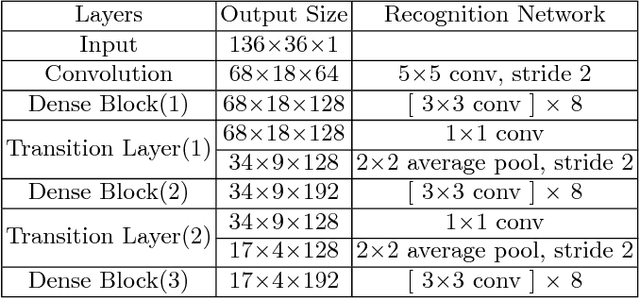

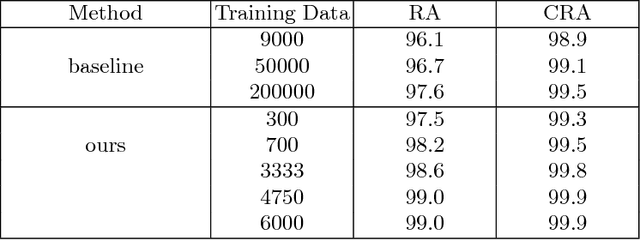
Training a good deep learning model often requires a lot of annotated data. As a large amount of labeled data is typically difficult to collect and even more difficult to annotate, data augmentation and data generation are widely used in the process of training deep neural networks. However, there is no clear common understanding on how much labeled data is needed to get satisfactory performance. In this paper, we try to address such a question using vehicle license plate character recognition as an example application. We apply computer graphic scripts and Generative Adversarial Networks to generate and augment a large number of annotated, synthesized license plate images with realistic colors, fonts, and character composition from a small number of real, manually labeled license plate images. Generated and augmented data are mixed and used as training data for the license plate recognition network modified from DenseNet. The experimental results show that the model trained from the generated mixed training data has good generalization ability, and the proposed approach achieves a new state-of-the-art accuracy on Dataset-1 and AOLP, even with a very limited number of original real license plates. In addition, the accuracy improvement caused by data generation becomes more significant when the number of labeled images is reduced. Data augmentation also plays a more significant role when the number of labeled images is increased.