 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially- and non-differentially-private random decision trees
Paper and Code
Feb 05, 2015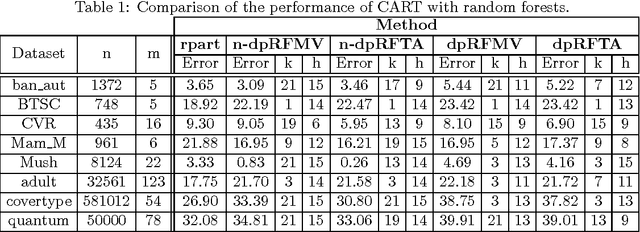
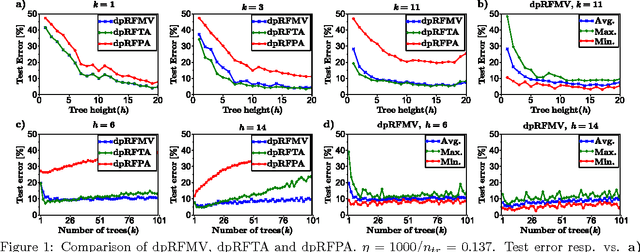
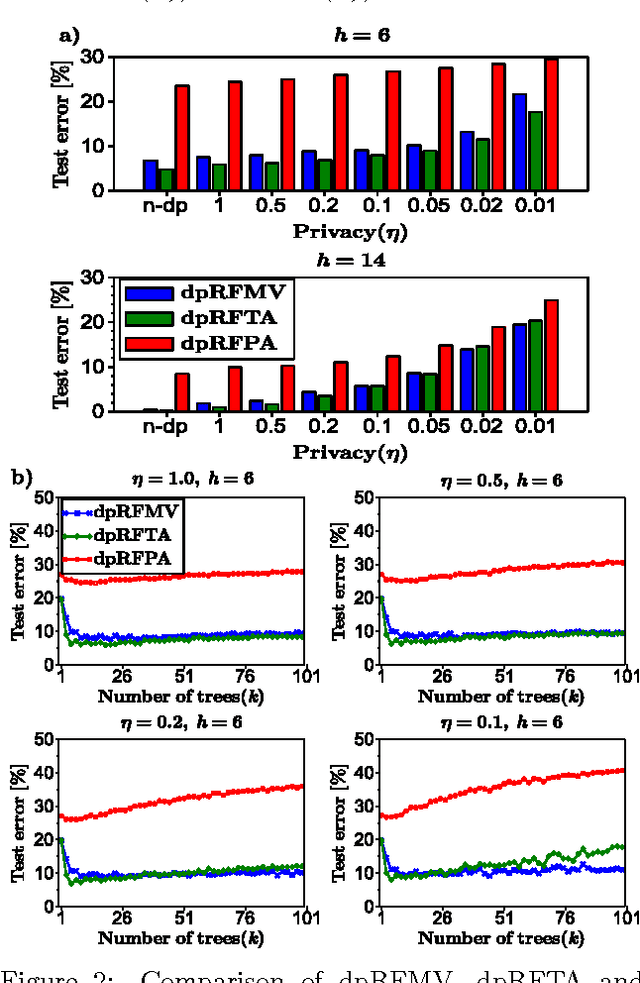
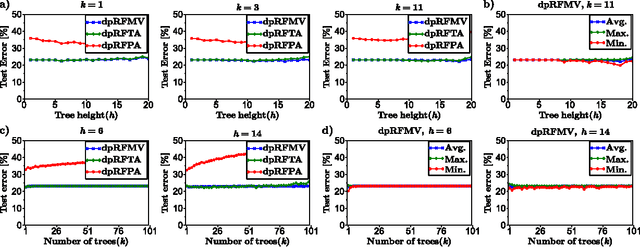
We consider supervised learning with random decision trees, where the tree construction is completely random. The method is popularly used and works well in practice despite the simplicity of the setting, but its statistical mechanism is not yet well-understood. In this paper we provide strong theoretical guarantees regarding learning with random decision trees. We analyze and compare three different variants of the algorithm that have minimal memory requirements: majority voting, threshold averaging and probabilistic averaging. The random structure of the tree enables us to adapt these methods to a differentially-private setting thus we also propose differentially-private versions of all three schemes. We give upper-bounds on the generalization error and mathematically explain how the accuracy depends on the number of random decision trees. Furthermore, we prove that only logarithmic (in the size of the dataset) number of independently selected random decision trees suffice to correctly classify most of the data, even when differential-privacy guarantees must be maintained. We empirically show that majority voting and threshold averaging give the best accuracy, also for conservative users requiring high privacy guarantees. Furthermore, we demonstrate that a simple majority voting rule is an especially good candidate for the differentially-private classifier since it is much less sensitive to the choice of forest parameters than other methods.