 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Channel Soil Moisture Measurement: High Accuracy and Low Crosstalk Through Optical-Semiconductor Based Differential Sensing
Jun 09, 2026Soil moisture measurement plays a key role in irrigation and environmental management. Yet it remains unreliable due to heterogeneous soils, limited sensing volumes, temperature drift, and parasitic inter-channel coupling. This work presents a compact multi-depth capacitive probe that extends a parallel-plate geometry from previous work with differential activation to suppress stray capacitances and improve accuracy. An equivalent-circuit model quantifies parasitic effects, and optically coupled transistor bridges isolate each sensing layer. Raw capacitance is converted to volumetric water content and plant-available water using established calibration models. Laboratory results show a fourfold reduction in temperature sensitivity, strong confinement of the sensing volume, and improved repeatability in heterogeneous soils. Field validation against reference sensors demonstrates high accuracy and precision comparable to widely used instruments, enabling a practical and scalable solution for agricultural and urban soil-moisture monitoring.
Comprehensive Signal Quality Evaluation of a Wearable Textile ECG Garment: A Sex-Balanced Study
Aug 29, 2025We introduce a novel wearable textile-garment featuring an innovative electrode placement aimed at minimizing noise and motion artifacts, thereby enhancing signal fidelity in Electrocardiography (ECG) recordings. We present a comprehensive, sex-balanced evaluation involving 15 healthy males and 15 healthy female participants to ensure the device's suitability across anatomical and physiological variations. The assessment framework encompasses distinct evaluation approaches: quantitative signal quality indices to objectively benchmark device performance; rhythm-based analyzes of physiological parameters such as heart rate and heart rate variability; machine learning classification tasks to assess application-relevant predictive utility; morphological analysis of ECG features including amplitude and interval parameters; and investigations of the effects of electrode projection angle given by the textile / body shape, with all analyzes stratified by sex to elucidate sex-specific influences. Evaluations were conducted across various activity phases representing real-world conditions. The results demonstrate that the textile system achieves signal quality highly concordant with reference devices in both rhythm and morphological analyses, exhibits robust classification performance, and enables identification of key sex-specific determinants affecting signal acquisition. These findings underscore the practical viability of textile-based ECG garments for physiological monitoring as well as psychophysiological state detection. Moreover, we identify the importance of incorporating sex-specific design considerations to ensure equitable and reliable cardiac diagnostics in wearable health technologies.
Simplicity is Key: An Unsupervised Pretraining Approach for Sparse Radio Channels
May 19, 2025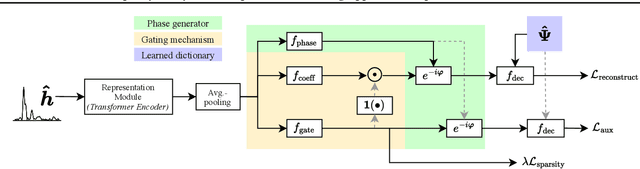

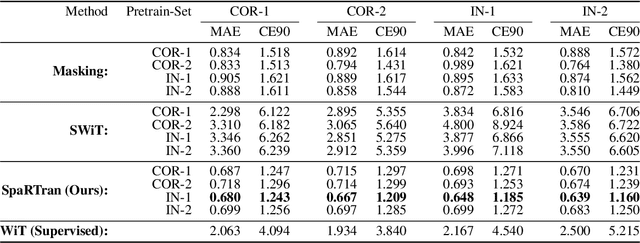
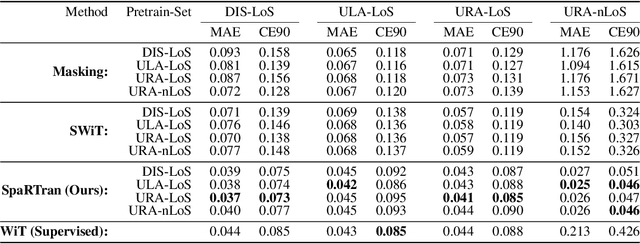
We introduce the Sparse pretrained Radio Transformer (SpaRTran), an unsupervised representation learning approach based on the concept of compressed sensing for radio channels. Our approach learns embeddings that focus on the physical properties of radio propagation, to create the optimal basis for fine-tuning on radio-based downstream tasks. SpaRTran uses a sparse gated autoencoder that induces a simplicity bias to the learned representations, resembling the sparse nature of radio propagation. For signal reconstruction, it learns a dictionary that holds atomic features, which increases flexibility across signal waveforms and spatiotemporal signal patterns. Our experiments show that SpaRTran reduces errors by up to 85 % compared to state-of-the-art methods when fine-tuned on radio fingerprinting, a challenging downstream task. In addition, our method requires less pretraining effort and offers greater flexibility, as we train it solely on individual radio signals. SpaRTran serves as an excellent base model that can be fine-tuned for various radio-based downstream tasks, effectively reducing the cost for labeling. In addition, it is significantly more versatile than existing methods and demonstrates superior generalization.
Human-inspired Explanations for Vision Transformers and Convolutional Neural Networks
Aug 20, 2024We introduce Foveation-based Explanations (FovEx), a novel human-inspired visual explainability (XAI) method for Deep Neural Networks. Our method achieves state-of-the-art performance on both transformer (on 4 out of 5 metrics) and convolutional models (on 3 out of 5 metrics), demonstrating its versatility. Furthermore, we show the alignment between the explanation map produced by FovEx and human gaze patterns (+14\% in NSS compared to RISE, +203\% in NSS compared to gradCAM), enhancing our confidence in FovEx's ability to close the interpretation gap between humans and machines.
FovEx: Human-inspired Explanations for Vision Transformers and Convolutional Neural Networks
Aug 04, 2024Explainability in artificial intelligence (XAI) remains a crucial aspect for fostering trust and understanding in machine learning models. Current visual explanation techniques, such as gradient-based or class-activation-based methods, often exhibit a strong dependence on specific model architectures. Conversely, perturbation-based methods, despite being model-agnostic, are computationally expensive as they require evaluating models on a large number of forward passes. In this work, we introduce Foveation-based Explanations (FovEx), a novel XAI method inspired by human vision. FovEx seamlessly integrates biologically inspired perturbations by iteratively creating foveated renderings of the image and combines them with gradient-based visual explorations to determine locations of interest efficiently. These locations are selected to maximize the performance of the model to be explained with respect to the downstream task and then combined to generate an attribution map. We provide a thorough evaluation with qualitative and quantitative assessments on established benchmarks. Our method achieves state-of-the-art performance on both transformers (on 4 out of 5 metrics) and convolutional models (on 3 out of 5 metrics), demonstrating its versatility among various architectures. Furthermore, we show the alignment between the explanation map produced by FovEx and human gaze patterns (+14\% in NSS compared to RISE, +203\% in NSS compared to GradCAM). This comparison enhances our confidence in FovEx's ability to close the interpretation gap between humans and machines.
Velocity-Based Channel Charting with Spatial Distribution Map Matching
Nov 14, 2023Fingerprint-based localization improves the positioning performance in challenging, non-line-of-sight (NLoS) dominated indoor environments. However, fingerprinting models require an expensive life-cycle management including recording and labeling of radio signals for the initial training and regularly at environmental changes. Alternatively, channel-charting avoids this labeling effort as it implicitly associates relative coordinates to the recorded radio signals. Then, with reference real-world coordinates (positions) we can use such charts for positioning tasks. However, current channel-charting approaches lag behind fingerprinting in their positioning accuracy and still require reference samples for localization, regular data recording and labeling to keep the models up to date. Hence, we propose a novel framework that does not require reference positions. We only require information from velocity information, e.g., from pedestrian dead reckoning or odometry to model the channel charts, and topological map information, e.g., a building floor plan, to transform the channel charts into real coordinates. We evaluate our approach on two different real-world datasets using 5G and distributed single-input/multiple-output system (SIMO) radio systems. Our experiments show that even with noisy velocity estimates and coarse map information, we achieve similar position accuracies
Indoor Localization with Robust Global Channel Charting: A Time-Distance-Based Approach
Oct 07, 2022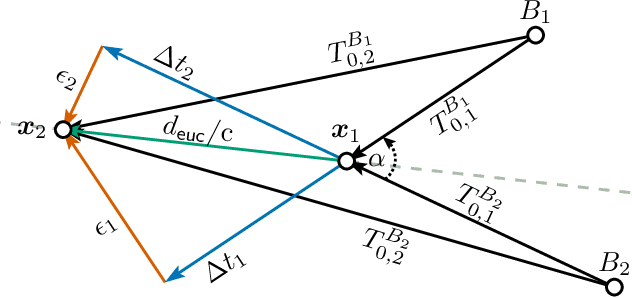
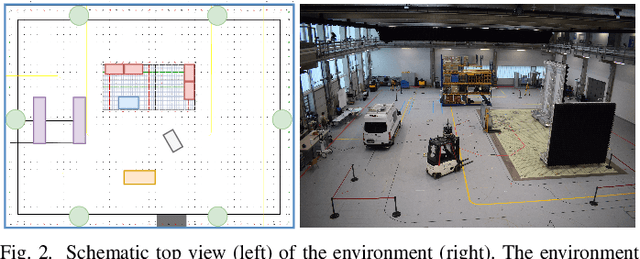
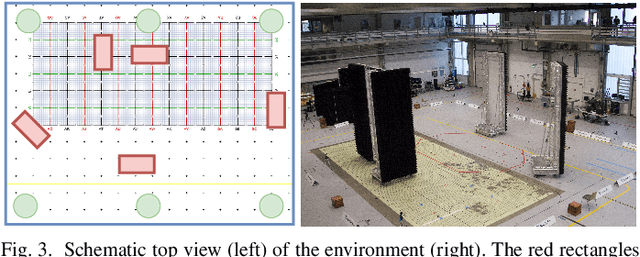
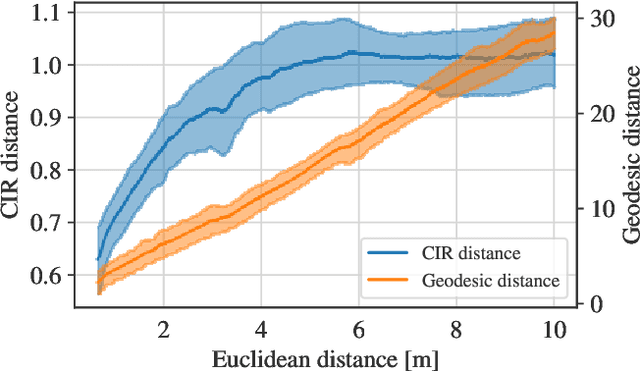
Fingerprinting-based positioning significantly improves the indoor localization performance in non-line-of-sight-dominated areas. However, its deployment and maintenance is cost-intensive as it needs ground-truth reference systems for both the initial training and the adaption to environmental changes. In contrast, channel charting (CC) works without explicit reference information and only requires the spatial correlations of channel state information (CSI). While CC has shown promising results in modelling the geometry of the radio environment, a deeper insight into CC for localization using multi-anchor large-bandwidth measurements is still pending. We contribute a novel distance metric for time-synchronized single-input/single-output CSIs that approaches a linear correlation to the Euclidean distance. This allows to learn the environment's global geometry without annotations. To efficiently optimize the global channel chart we approximate the metric with a Siamese neural network. This enables full CC-assisted fingerprinting and positioning only using a linear transformation from the chart to the real-world coordinates. We compare our approach to the state-of-the-art of CC on two different real-world data sets recorded with a 5G and UWB radio setup. Our approach outperforms others with localization accuracies of 0.69m for the UWB and 1.4m for the 5G setup. We show that CC-assisted fingerprinting enables highly accurate localization and reduces (or eliminates) the need for annotated training data.
How to Learn from Risk: Explicit Risk-Utility Reinforcement Learning for Efficient and Safe Driving Strategies
Mar 16, 2022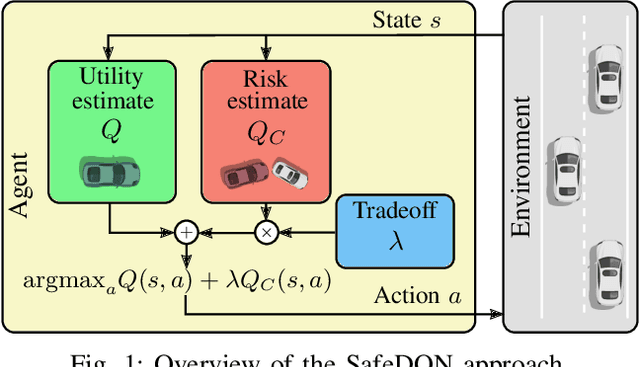
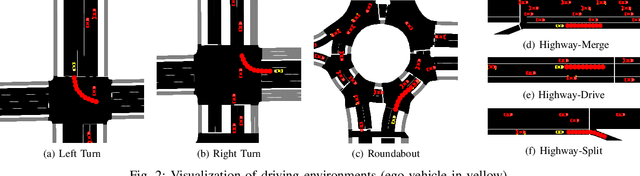
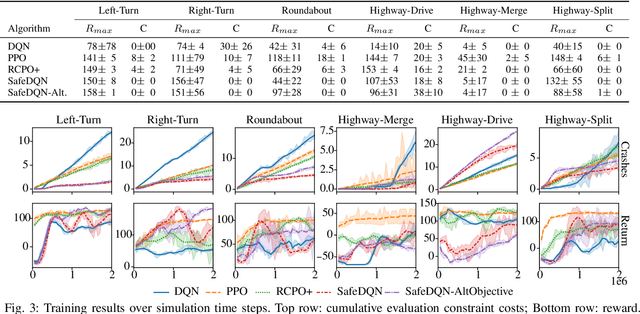
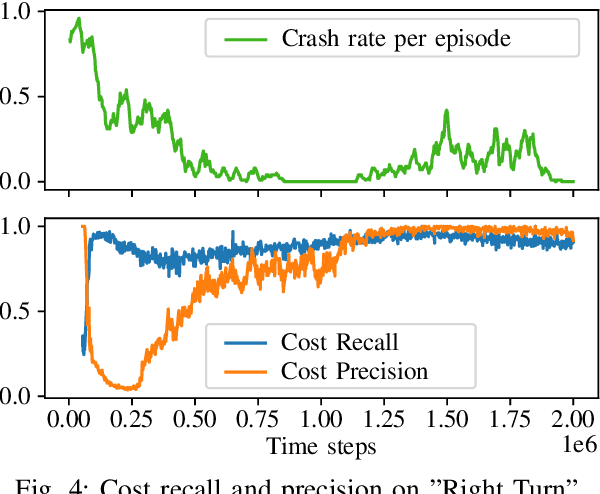
Autonomous driving has the potential to revolutionize mobility and is hence an active area of research. In practice, the behavior of autonomous vehicles must be acceptable, i.e., efficient, safe, and interpretable. While vanilla reinforcement learning (RL) finds performant behavioral strategies, they are often unsafe and uninterpretable. Safety is introduced through Safe RL approaches, but they still mostly remain uninterpretable as the learned behaviour is jointly optimized for safety and performance without modeling them separately. Interpretable machine learning is rarely applied to RL. This paper proposes SafeDQN, which allows to make the behavior of autonomous vehicles safe and interpretable while still being efficient. SafeDQN offers an understandable, semantic trade-off between the expected risk and the utility of actions while being algorithmically transparent. We show that SafeDQN finds interpretable and safe driving policies for a variety of scenarios and demonstrate how state-of-the-art saliency techniques can help to assess both risk and utility.
An Introduction to Multi-Agent Reinforcement Learning and Review of its Application to Autonomous Mobility
Mar 15, 2022
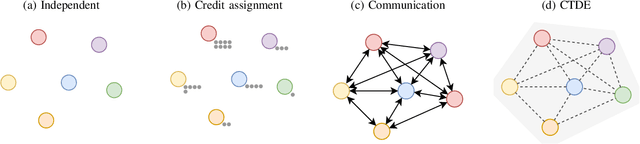
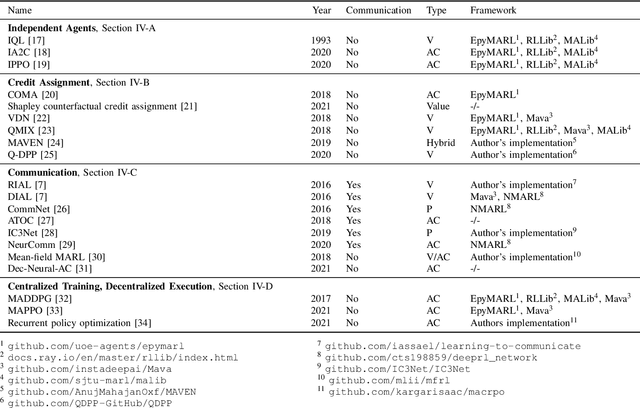
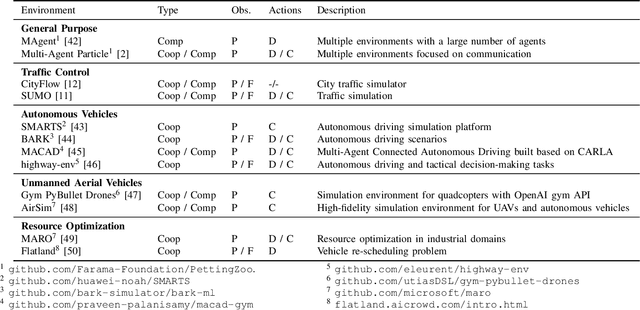
Many scenarios in mobility and traffic involve multiple different agents that need to cooperate to find a joint solution. Recent advances in behavioral planning use Reinforcement Learning to find effective and performant behavior strategies. However, as autonomous vehicles and vehicle-to-X communications become more mature, solutions that only utilize single, independent agents leave potential performance gains on the road. Multi-Agent Reinforcement Learning (MARL) is a research field that aims to find optimal solutions for multiple agents that interact with each other. This work aims to give an overview of the field to researchers in autonomous mobility. We first explain MARL and introduce important concepts. Then, we discuss the central paradigms that underlie MARL algorithms, and give an overview of state-of-the-art methods and ideas in each paradigm. With this background, we survey applications of MARL in autonomous mobility scenarios and give an overview of existing scenarios and implementations.
Rigid and non-rigid motion compensation in weight-bearing cone-beam CT of the knee using inertial measurements
Feb 24, 2021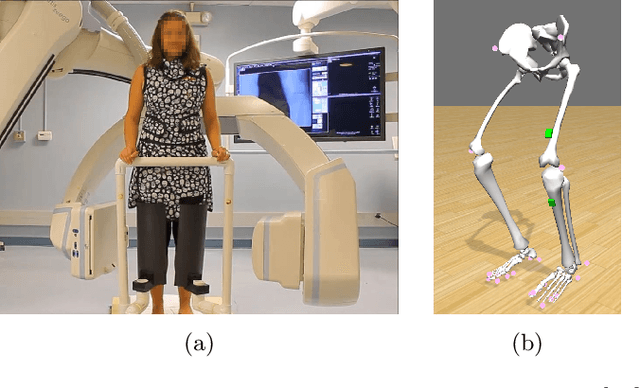
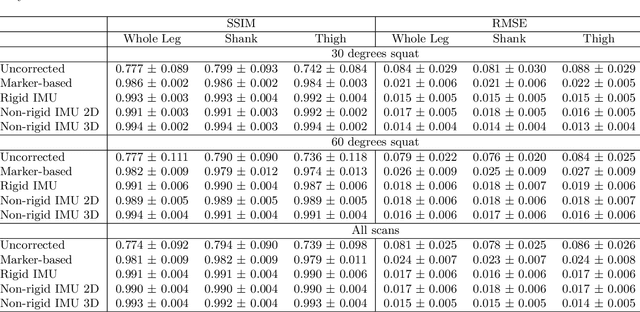
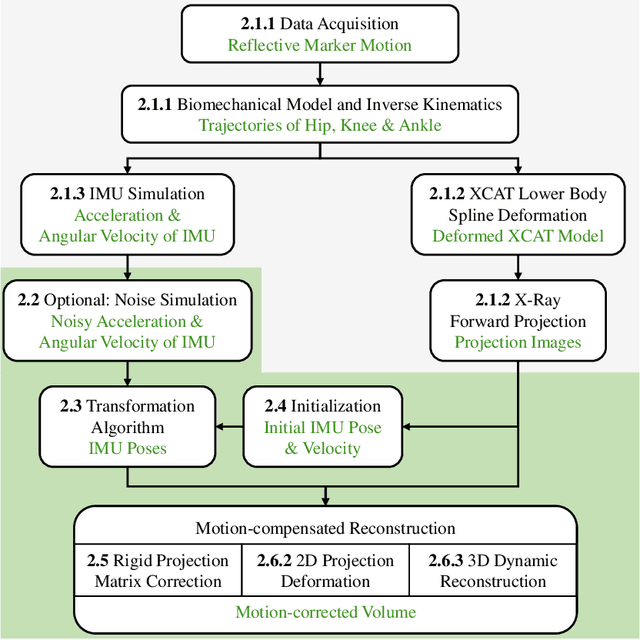

Involuntary subject motion is the main source of artifacts in weight-bearing cone-beam CT of the knee. To achieve image quality for clinical diagnosis, the motion needs to be compensated. We propose to use inertial measurement units (IMUs) attached to the leg for motion estimation. We perform a simulation study using real motion recorded with an optical tracking system. Three IMU-based correction approaches are evaluated, namely rigid motion correction, non-rigid 2D projection deformation and non-rigid 3D dynamic reconstruction. We present an initialization process based on the system geometry. With an IMU noise simulation, we investigate the applicability of the proposed methods in real applications. All proposed IMU-based approaches correct motion at least as good as a state-of-the-art marker-based approach. The structural similarity index and the root mean squared error between motion-free and motion corrected volumes are improved by 24-35% and 78-85%, respectively, compared with the uncorrected case. The noise analysis shows that the noise levels of commercially available IMUs need to be improved by a factor of $10^5$ which is currently only achieved by specialized hardware not robust enough for the application. The presented study confirms the feasibility of this novel approach and defines improvements necessary for a real application.