 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Learn from Risk: Explicit Risk-Utility Reinforcement Learning for Efficient and Safe Driving Strategies
Paper and Code
Mar 16, 2022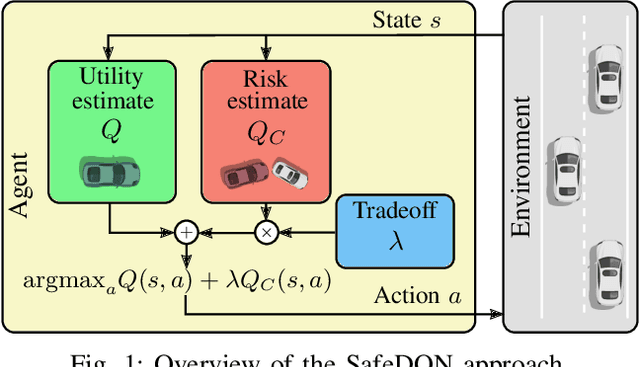
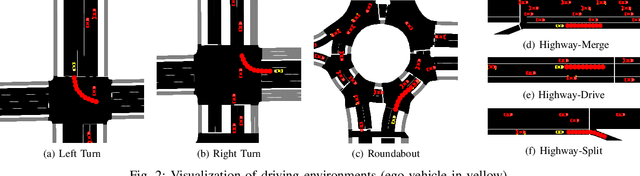
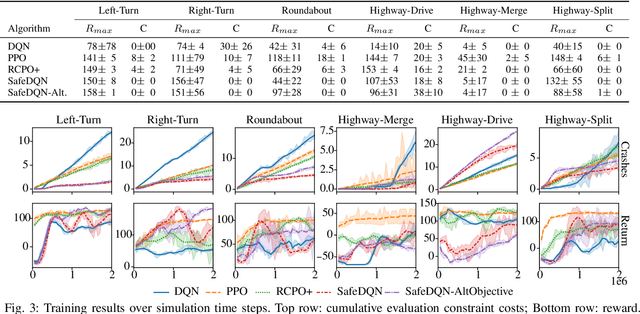
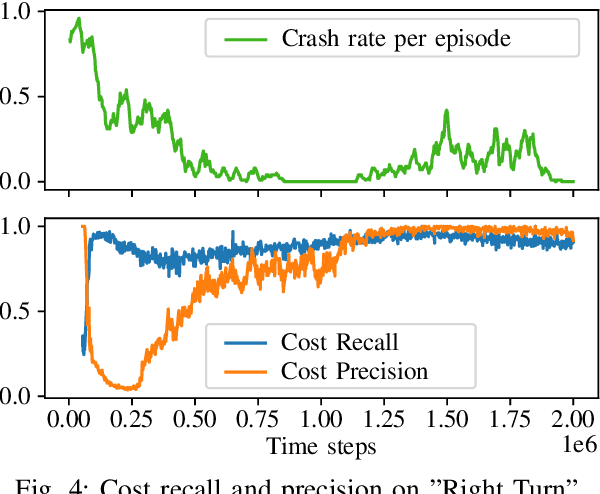
Autonomous driving has the potential to revolutionize mobility and is hence an active area of research. In practice, the behavior of autonomous vehicles must be acceptable, i.e., efficient, safe, and interpretable. While vanilla reinforcement learning (RL) finds performant behavioral strategies, they are often unsafe and uninterpretable. Safety is introduced through Safe RL approaches, but they still mostly remain uninterpretable as the learned behaviour is jointly optimized for safety and performance without modeling them separately. Interpretable machine learning is rarely applied to RL. This paper proposes SafeDQN, which allows to make the behavior of autonomous vehicles safe and interpretable while still being efficient. SafeDQN offers an understandable, semantic trade-off between the expected risk and the utility of actions while being algorithmically transparent. We show that SafeDQN finds interpretable and safe driving policies for a variety of scenarios and demonstrate how state-of-the-art saliency techniques can help to assess both risk and utility.