 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCountSteer: Steering Attention for Object Counting in Diffusion Models
Nov 14, 2025Text-to-image diffusion models generate realistic and coherent images but often fail to follow numerical instructions in text, revealing a gap between language and visual representation. Interestingly, we found that these models are not entirely blind to numbers-they are implicitly aware of their own counting accuracy, as their internal signals shift in consistent ways depending on whether the output meets the specified count. This observation suggests that the model already encodes a latent notion of numerical correctness, which can be harnessed to guide generation more precisely. Building on this intuition, we introduce CountSteer, a training-free method that improves generation of specified object counts by steering the model's cross-attention hidden states during inference. In our experiments, CountSteer improved object-count accuracy by about 4% without compromising visual quality, demonstrating a simple yet effective step toward more controllable and semantically reliable text-to-image generation.
Riemannian Geometric-based Meta Learning
Mar 14, 2025


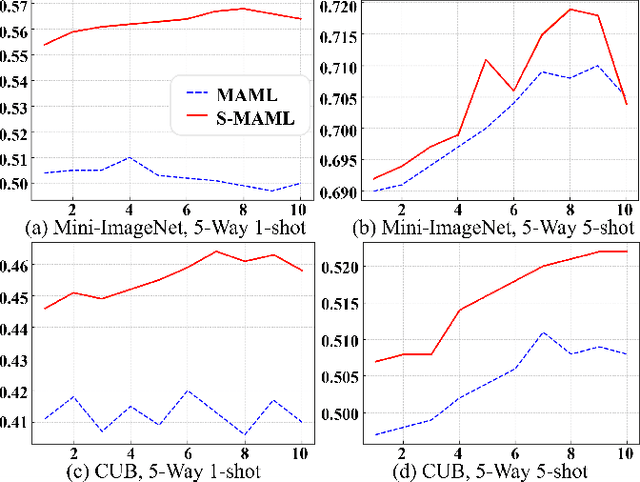
Meta-learning, or "learning to learn," aims to enable models to quickly adapt to new tasks with minimal data. While traditional methods like Model-Agnostic Meta-Learning (MAML) optimize parameters in Euclidean space, they often struggle to capture complex learning dynamics, particularly in few-shot learning scenarios. To address this limitation, we propose Stiefel-MAML, which integrates Riemannian geometry by optimizing within the Stiefel manifold, a space that naturally enforces orthogonality constraints. By leveraging the geometric structure of the Stiefel manifold, we improve parameter expressiveness and enable more efficient optimization through Riemannian gradient calculations and retraction operations. We also introduce a novel kernel-based loss function defined on the Stiefel manifold, further enhancing the model's ability to explore the parameter space. Experimental results on benchmark datasets--including Omniglot, Mini-ImageNet, FC-100, and CUB--demonstrate that Stiefel-MAML consistently outperforms traditional MAML, achieving superior performance across various few-shot learning tasks. Our findings highlight the potential of Riemannian geometry to enhance meta-learning, paving the way for future research on optimizing over different geometric structures.
D-Cube: Exploiting Hyper-Features of Diffusion Model for Robust Medical Classification
Nov 17, 2024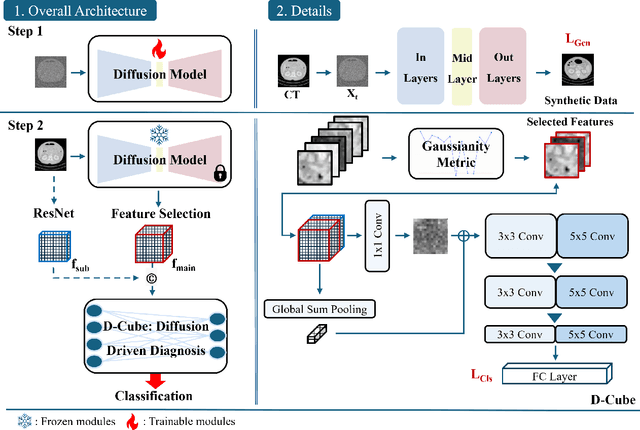
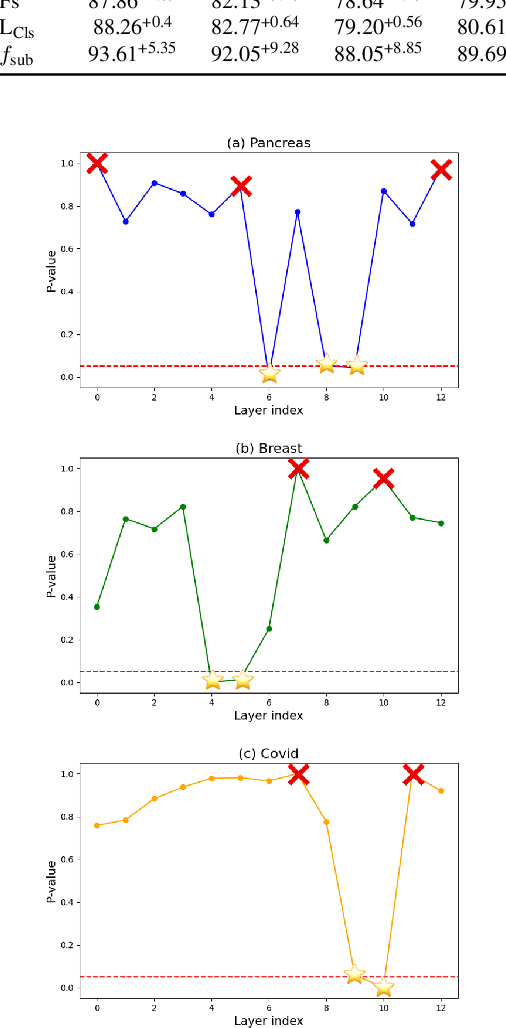

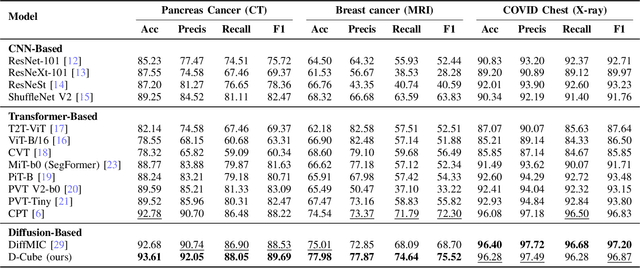
The integration of deep learning technologies in medical imaging aims to enhance the efficiency and accuracy of cancer diagnosis, particularly for pancreatic and breast cancers, which present significant diagnostic challenges due to their high mortality rates and complex imaging characteristics. This paper introduces Diffusion-Driven Diagnosis (D-Cube), a novel approach that leverages hyper-features from a diffusion model combined with contrastive learning to improve cancer diagnosis. D-Cube employs advanced feature selection techniques that utilize the robust representational capabilities of diffusion models, enhancing classification performance on medical datasets under challenging conditions such as data imbalance and limited sample availability. The feature selection process optimizes the extraction of clinically relevant features, significantly improving classification accuracy and demonstrating resilience in imbalanced and limited data scenarios. Experimental results validate the effectiveness of D-Cube across multiple medical imaging modalities, including CT, MRI, and X-ray, showing superior performance compared to existing baseline models. D-Cube represents a new strategy in cancer detection, employing advanced deep learning techniques to achieve state-of-the-art diagnostic accuracy and efficiency.
Unsupervised Training of a Dynamic Context-Aware Deep Denoising Framework for Low-Dose Fluoroscopic Imaging
Oct 29, 2024



Fluoroscopy is critical for real-time X-ray visualization in medical imaging. However, low-dose images are compromised by noise, potentially affecting diagnostic accuracy. Noise reduction is crucial for maintaining image quality, especially given such challenges as motion artifacts and the limited availability of clean data in medical imaging. To address these issues, we propose an unsupervised training framework for dynamic context-aware denoising of fluoroscopy image sequences. First, we train the multi-scale recurrent attention U-Net (MSR2AU-Net) without requiring clean data to address the initial noise. Second, we incorporate a knowledge distillation-based uncorrelated noise suppression module and a recursive filtering-based correlated noise suppression module enhanced with motion compensation to further improve motion compensation and achieve superior denoising performance. Finally, we introduce a novel approach by combining these modules with a pixel-wise dynamic object motion cross-fusion matrix, designed to adapt to motion, and an edge-preserving loss for precise detail retention. To validate the proposed method, we conducted extensive numerical experiments on medical image datasets, including 3500 fluoroscopy images from dynamic phantoms (2,400 images for training, 1,100 for testing) and 350 clinical images from a spinal surgery patient. Moreover, we demonstrated the robustness of our approach across different imaging modalities by testing it on the publicly available 2016 Low Dose CT Grand Challenge dataset, using 4,800 images for training and 1,136 for testing. The results demonstrate that the proposed approach outperforms state-of-the-art unsupervised algorithms in both visual quality and quantitative evaluation while achieving comparable performance to well-established supervised learning methods across low-dose fluoroscopy and CT imaging.
Noise2Contrast: Multi-Contrast Fusion Enables Self-Supervised Tomographic Image Denoising
Dec 09, 2022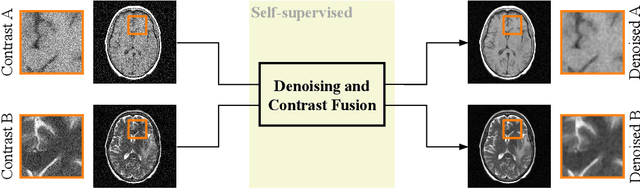
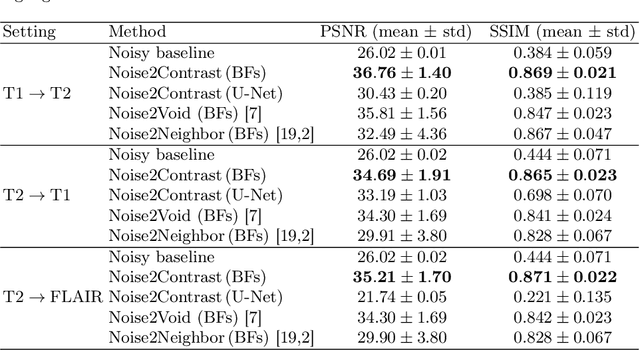
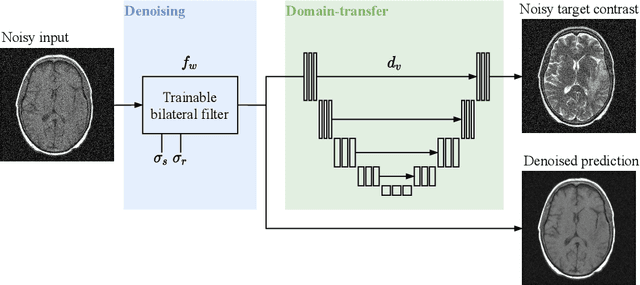

Self-supervised image denoising techniques emerged as convenient methods that allow training denoising models without requiring ground-truth noise-free data. Existing methods usually optimize loss metrics that are calculated from multiple noisy realizations of similar images, e.g., from neighboring tomographic slices. However, those approaches fail to utilize the multiple contrasts that are routinely acquired in medical imaging modalities like MRI or dual-energy CT. In this work, we propose the new self-supervised training scheme Noise2Contrast that combines information from multiple measured image contrasts to train a denoising model. We stack denoising with domain-transfer operators to utilize the independent noise realizations of different image contrasts to derive a self-supervised loss. The trained denoising operator achieves convincing quantitative and qualitative results, outperforming state-of-the-art self-supervised methods by 4.7-11.0%/4.8-7.3% (PSNR/SSIM) on brain MRI data and by 43.6-50.5%/57.1-77.1% (PSNR/SSIM) on dual-energy CT X-ray microscopy data with respect to the noisy baseline. Our experiments on different real measured data sets indicate that Noise2Contrast training generalizes to other multi-contrast imaging modalities.
Rigid and non-rigid motion compensation in weight-bearing cone-beam CT of the knee using inertial measurements
Feb 24, 2021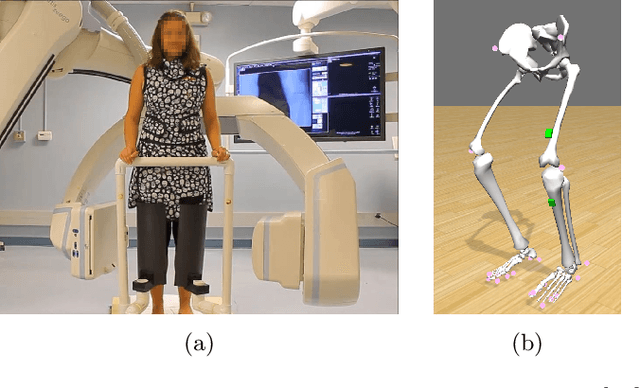
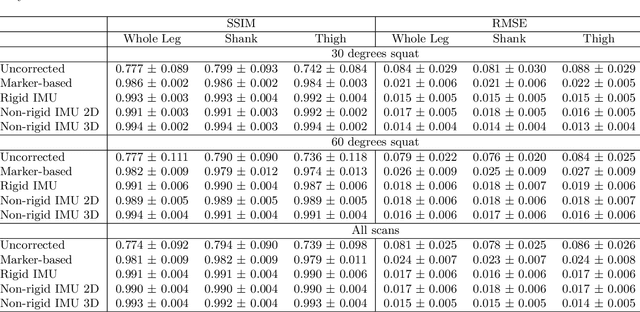

Involuntary subject motion is the main source of artifacts in weight-bearing cone-beam CT of the knee. To achieve image quality for clinical diagnosis, the motion needs to be compensated. We propose to use inertial measurement units (IMUs) attached to the leg for motion estimation. We perform a simulation study using real motion recorded with an optical tracking system. Three IMU-based correction approaches are evaluated, namely rigid motion correction, non-rigid 2D projection deformation and non-rigid 3D dynamic reconstruction. We present an initialization process based on the system geometry. With an IMU noise simulation, we investigate the applicability of the proposed methods in real applications. All proposed IMU-based approaches correct motion at least as good as a state-of-the-art marker-based approach. The structural similarity index and the root mean squared error between motion-free and motion corrected volumes are improved by 24-35% and 78-85%, respectively, compared with the uncorrected case. The noise analysis shows that the noise levels of commercially available IMUs need to be improved by a factor of $10^5$ which is currently only achieved by specialized hardware not robust enough for the application. The presented study confirms the feasibility of this novel approach and defines improvements necessary for a real application.
Inertial Measurements for Motion Compensation in Weight-bearing Cone-beam CT of the Knee
Jul 09, 2020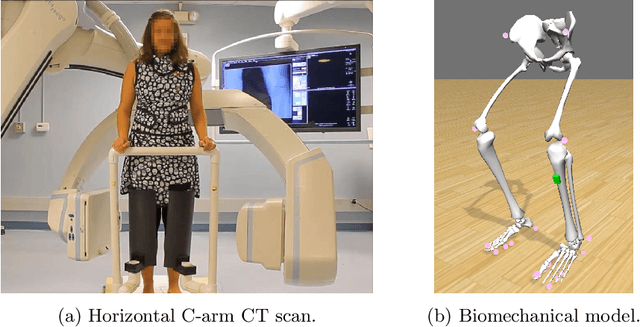
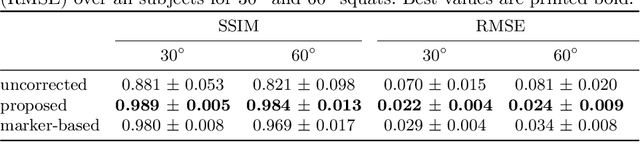
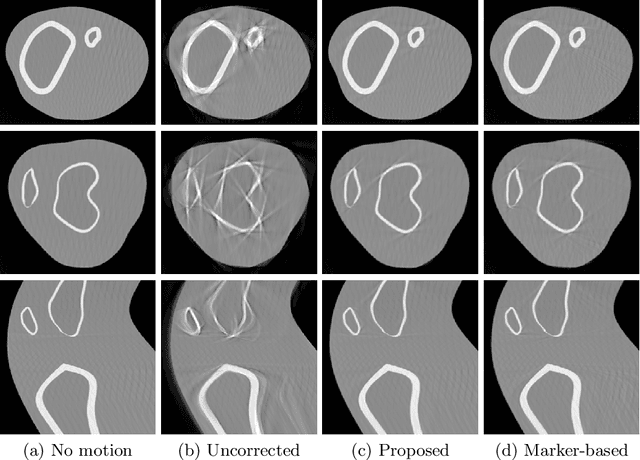

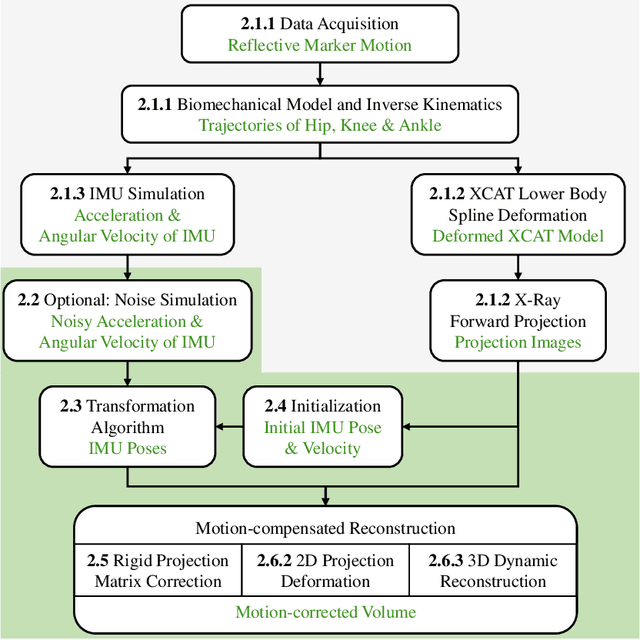
Involuntary motion during weight-bearing cone-beam computed tomography (CT) scans of the knee causes artifacts in the reconstructed volumes making them unusable for clinical diagnosis. Currently, image-based or marker-based methods are applied to correct for this motion, but often require long execution or preparation times. We propose to attach an inertial measurement unit (IMU) containing an accelerometer and a gyroscope to the leg of the subject in order to measure the motion during the scan and correct for it. To validate this approach, we present a simulation study using real motion measured with an optical 3D tracking system. With this motion, an XCAT numerical knee phantom is non-rigidly deformed during a simulated CT scan creating motion corrupted projections. A biomechanical model is animated with the same tracked motion in order to generate measurements of an IMU placed below the knee. In our proposed multi-stage algorithm, these signals are transformed to the global coordinate system of the CT scan and applied for motion compensation during reconstruction. Our proposed approach can effectively reduce motion artifacts in the reconstructed volumes. Compared to the motion corrupted case, the average structural similarity index and root mean squared error with respect to the no-motion case improved by 13-21% and 68-70%, respectively. These results are qualitatively and quantitatively on par with a state-of-the-art marker-based method we compared our approach to. The presented study shows the feasibility of this novel approach, and yields promising results towards a purely IMU-based motion compensation in C-arm CT.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020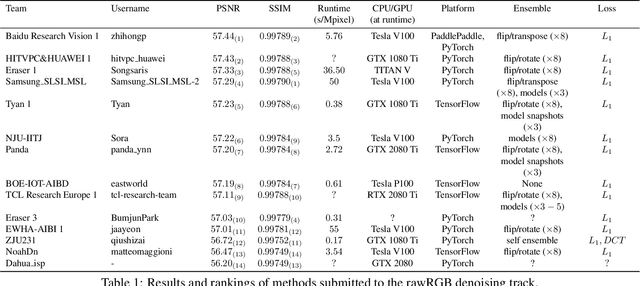
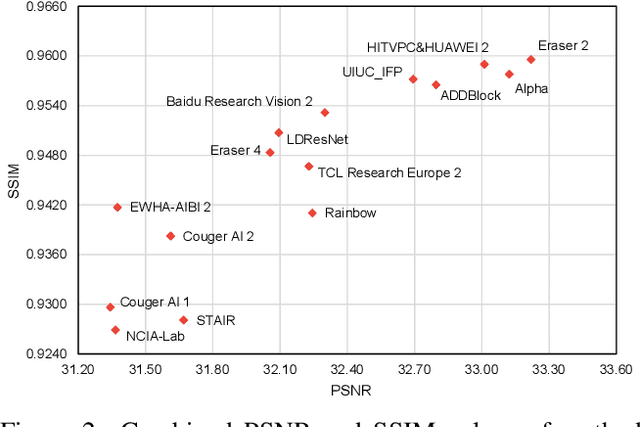
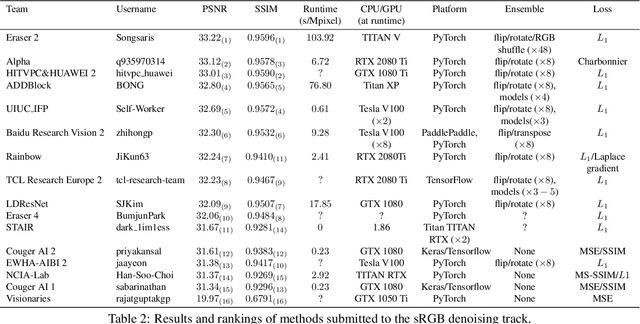
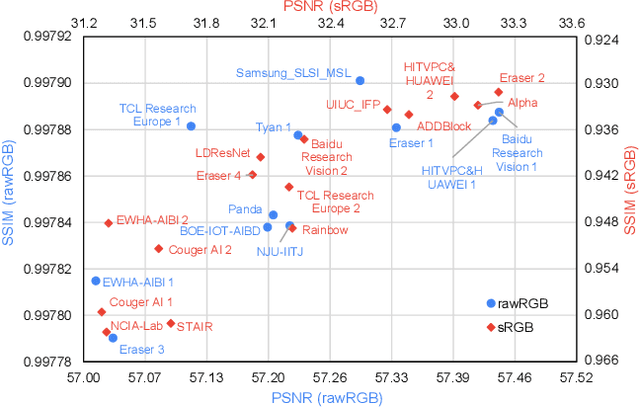
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Multi-Channel Volumetric Neural Network for Knee Cartilage Segmentation in Cone-beam CT
Dec 03, 2019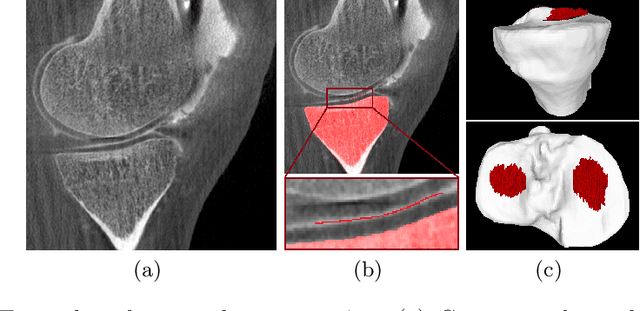
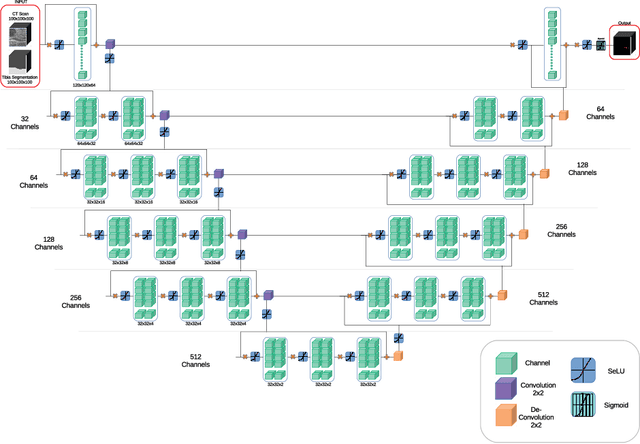

Analyzing knee cartilage thickness and strain under load can help to further the understanding of the effects of diseases like Osteoarthritis. A precise segmentation of the cartilage is a necessary prerequisite for this analysis. This segmentation task has mainly been addressed in Magnetic Resonance Imaging, and was rarely investigated on contrast-enhanced Computed Tomography, where contrast agent visualizes the border between femoral and tibial cartilage. To overcome the main drawback of manual segmentation, namely its high time investment, we propose to use a 3D Convolutional Neural Network for this task. The presented architecture consists of a V-Net with SeLu activation, and a Tversky loss function. Due to the high imbalance between very few cartilage pixels and many background pixels, a high false positive rate is to be expected. To reduce this rate, the two largest segmented point clouds are extracted using a connected component analysis, since they most likely represent the medial and lateral tibial cartilage surfaces. The resulting segmentations are compared to manual segmentations, and achieve on average a recall of 0.69, which confirms the feasibility of this approach.
Precision Learning: Towards Use of Known Operators in Neural Networks
Oct 12, 2018
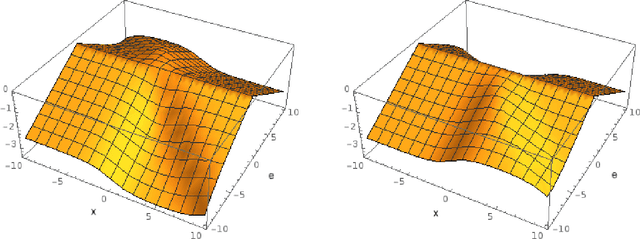
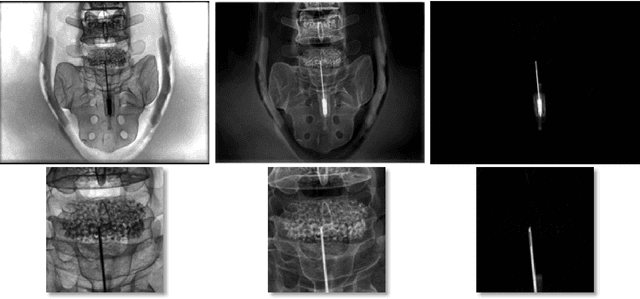
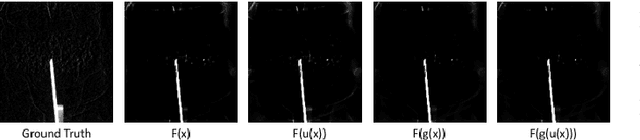
In this paper, we consider the use of prior knowledge within neural networks. In particular, we investigate the effect of a known transform within the mapping from input data space to the output domain. We demonstrate that use of known transforms is able to change maximal error bounds. In order to explore the effect further, we consider the problem of X-ray material decomposition as an example to incorporate additional prior knowledge. We demonstrate that inclusion of a non-linear function known from the physical properties of the system is able to reduce prediction errors therewith improving prediction quality from SSIM values of 0.54 to 0.88. This approach is applicable to a wide set of applications in physics and signal processing that provide prior knowledge on such transforms. Also maximal error estimation and network understanding could be facilitated within the context of precision learning.
* accepted on ICPR 2018