 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-Automated Usability Evaluation Framework for Interactive Image Segmentation Systems
Sep 01, 2019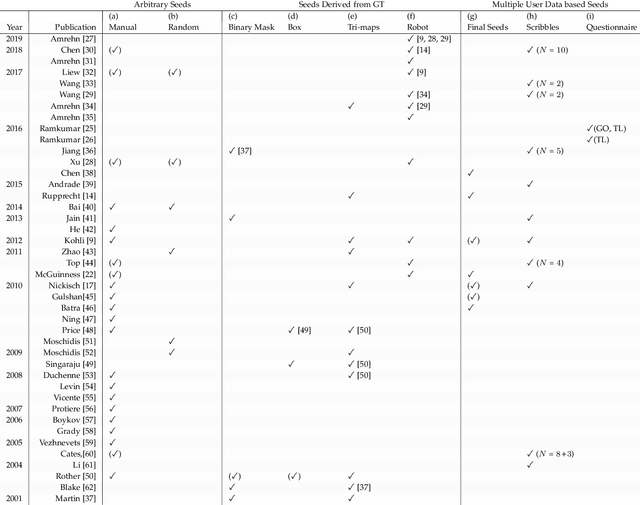
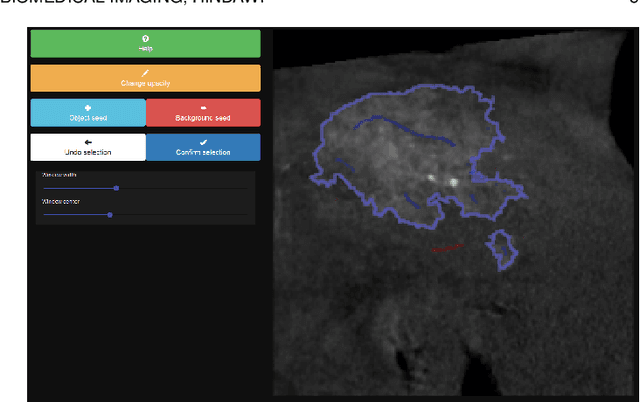
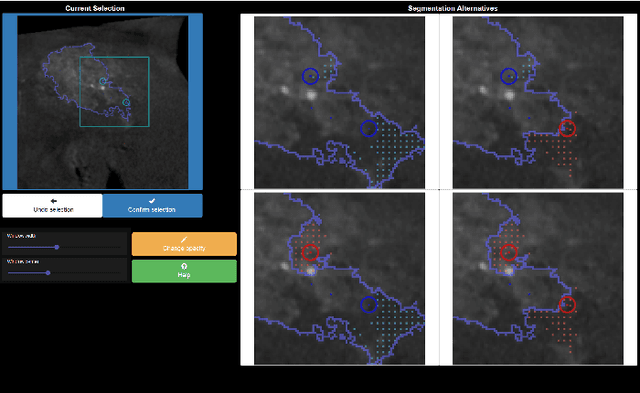
For complex segmentation tasks, the achievable accuracy of fully automated systems is inherently limited. Specifically, when a precise segmentation result is desired for a small amount of given data sets, semi-automatic methods exhibit a clear benefit for the user. The optimization of human computer interaction (HCI) is an essential part of interactive image segmentation. Nevertheless, publications introducing novel interactive segmentation systems (ISS) often lack an objective comparison of HCI aspects. It is demonstrated, that even when the underlying segmentation algorithm is the same throughout interactive prototypes, their user experience may vary substantially. As a result, users prefer simple interfaces as well as a considerable degree of freedom to control each iterative step of the segmentation. In this article, an objective method for the comparison of ISS is proposed, based on extensive user studies. A summative qualitative content analysis is conducted via abstraction of visual and verbal feedback given by the participants. A direct assessment of the segmentation system is executed by the users via the system usability scale (SUS) and AttrakDiff-2 questionnaires. Furthermore, an approximation of the findings regarding usability aspects in those studies is introduced, conducted solely from the system-measurable user actions during their usage of interactive segmentation prototypes. The prediction of all questionnaire results has an average relative error of 8.9%, which is close to the expected precision of the questionnaire results themselves. This automated evaluation scheme may significantly reduce the resources necessary to investigate each variation of a prototype's user interface (UI) features and segmentation methodologies.
On Laughter and Speech-Laugh, Based on Observations of Child-Robot Interaction
Aug 30, 2019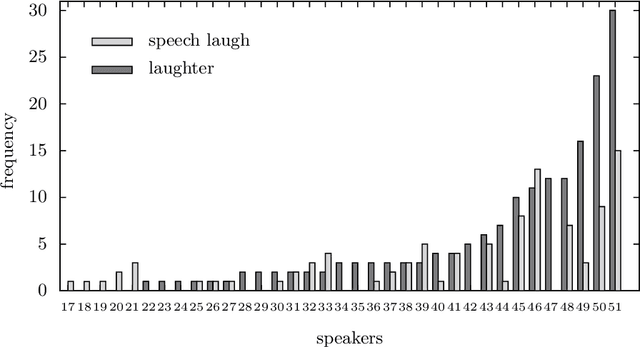
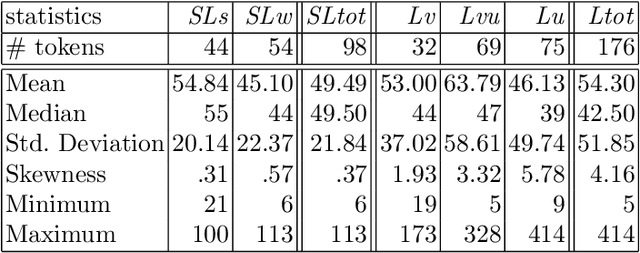
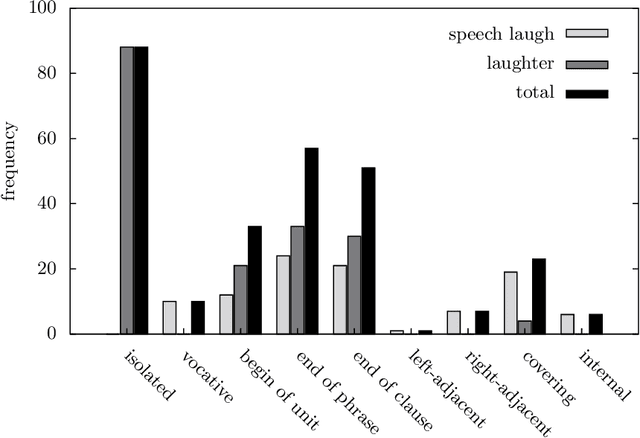
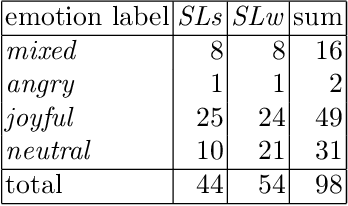
In this article, we study laughter found in child-robot interaction where it had not been prompted intentionally. Different types of laughter and speech-laugh are annotated and processed. In a descriptive part, we report on the position of laughter and speech-laugh in syntax and dialogue structure, and on communicative functions. In a second part, we report on automatic classification performance and on acoustic characteristics, based on extensive feature selection procedures.
The Random Forest Classifier in WEKA: Discussion and New Developments for Imbalanced Data
Jan 04, 2019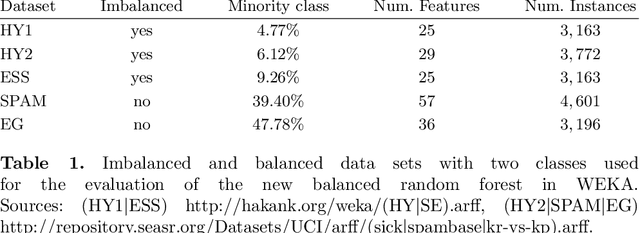
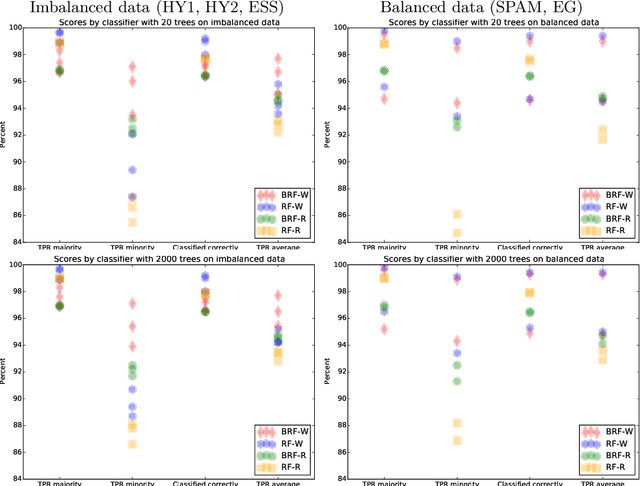
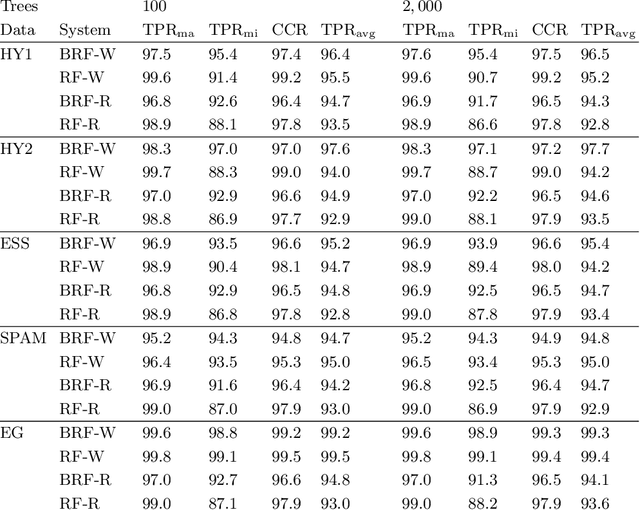
Data analysis and machine learning have become an integrative part of the modern scientific methodology, providing automated techniques to predict further information based on observations. One of these classification and regression techniques is the random forest approach. Those decision tree based predictors are best known for their good computational performance and scalability. However, in case of severely imbalanced training data, as often seen in medical studies' data with large control groups, the training algorithm or the sampling process has to be altered in order to improve the prediction quality for minority classes. In this work, a balanced random forest approach for WEKA is proposed. Furthermore, the prediction quality of the unmodified random forest implementation and the new balanced random forest version for WEKA are evaluated against reference implementations in R. Two-class problems on balanced data sets and imbalanced medical studies' data are investigated. A superior prediction quality using the proposed method for imbalanced data is shown compared to the other three techniques.
Precision Learning: Towards Use of Known Operators in Neural Networks
Oct 12, 2018
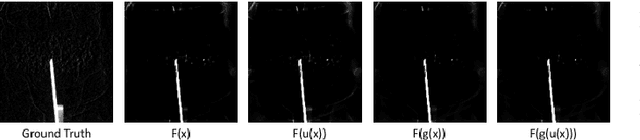
In this paper, we consider the use of prior knowledge within neural networks. In particular, we investigate the effect of a known transform within the mapping from input data space to the output domain. We demonstrate that use of known transforms is able to change maximal error bounds. In order to explore the effect further, we consider the problem of X-ray material decomposition as an example to incorporate additional prior knowledge. We demonstrate that inclusion of a non-linear function known from the physical properties of the system is able to reduce prediction errors therewith improving prediction quality from SSIM values of 0.54 to 0.88. This approach is applicable to a wide set of applications in physics and signal processing that provide prior knowledge on such transforms. Also maximal error estimation and network understanding could be facilitated within the context of precision learning.
* accepted on ICPR 2018
Robust Seed Mask Generation for Interactive Image Segmentation
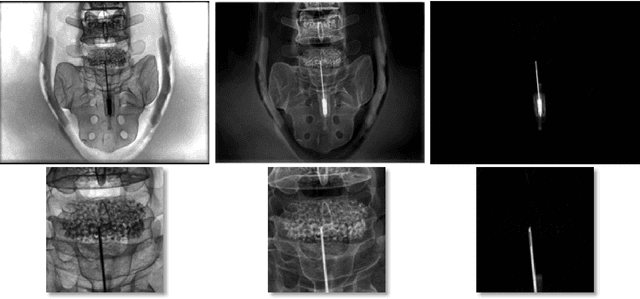
Nov 20, 2017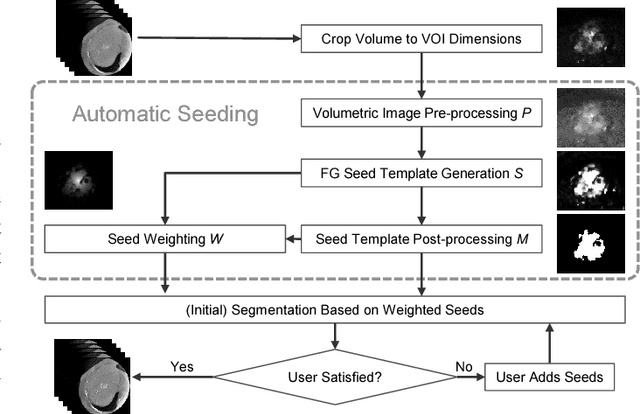
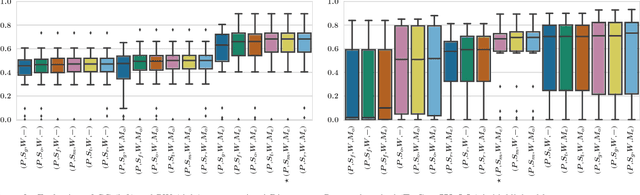

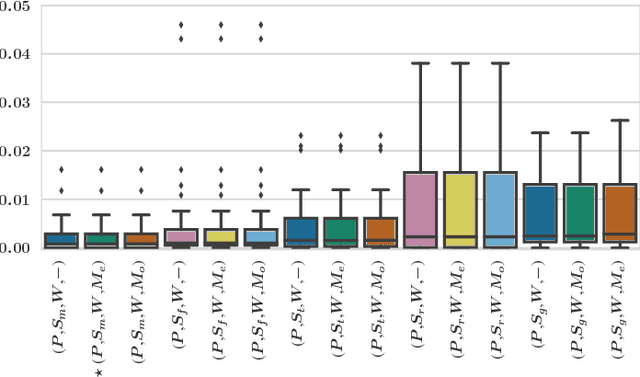
In interactive medical image segmentation, anatomical structures are extracted from reconstructed volumetric images. The first iterations of user interaction traditionally consist of drawing pictorial hints as an initial estimate of the object to extract. Only after this time consuming first phase, the efficient selective refinement of current segmentation results begins. Erroneously labeled seeds, especially near the border of the object, are challenging to detect and replace for a human and may substantially impact the overall segmentation quality. We propose an automatic seeding pipeline as well as a configuration based on saliency recognition, in order to skip the time-consuming initial interaction phase during segmentation. A median Dice score of 68.22% is reached before the first user interaction on the test data set with an error rate in seeding of only 0.088%.
UI-Net: Interactive Artificial Neural Networks for Iterative Image Segmentation Based on a User Model
Sep 11, 2017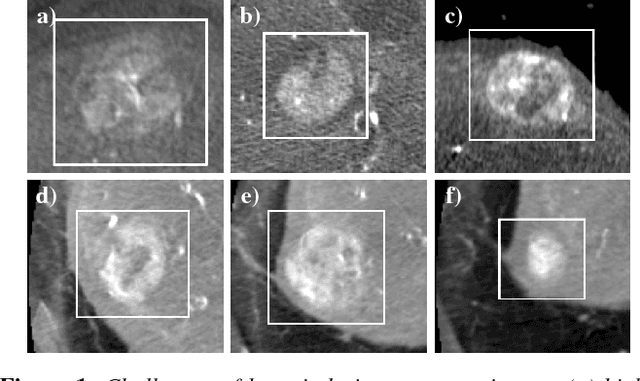
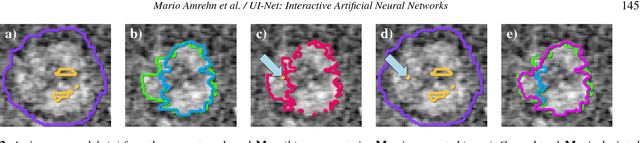
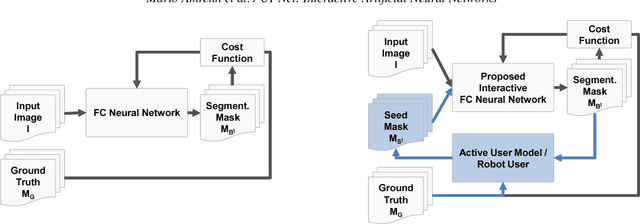
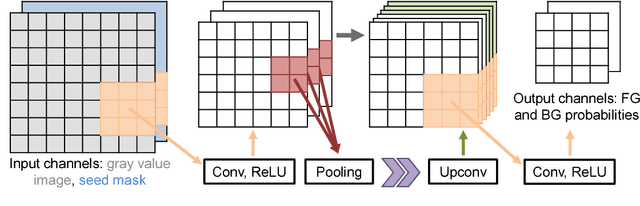
For complex segmentation tasks, fully automatic systems are inherently limited in their achievable accuracy for extracting relevant objects. Especially in cases where only few data sets need to be processed for a highly accurate result, semi-automatic segmentation techniques exhibit a clear benefit for the user. One area of application is medical image processing during an intervention for a single patient. We propose a learning-based cooperative segmentation approach which includes the computing entity as well as the user into the task. Our system builds upon a state-of-the-art fully convolutional artificial neural network (FCN) as well as an active user model for training. During the segmentation process, a user of the trained system can iteratively add additional hints in form of pictorial scribbles as seed points into the FCN system to achieve an interactive and precise segmentation result. The segmentation quality of interactive FCNs is evaluated. Iterative FCN approaches can yield superior results compared to networks without the user input channel component, due to a consistent improvement in segmentation quality after each interaction.
* This work is submitted to the 2017 Eurographics Workshop on Visual Computing for Biology and Medicine
A Self-Taught Artificial Agent for Multi-Physics Computational Model Personalization
May 01, 2016
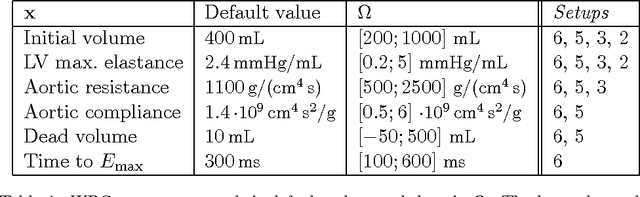
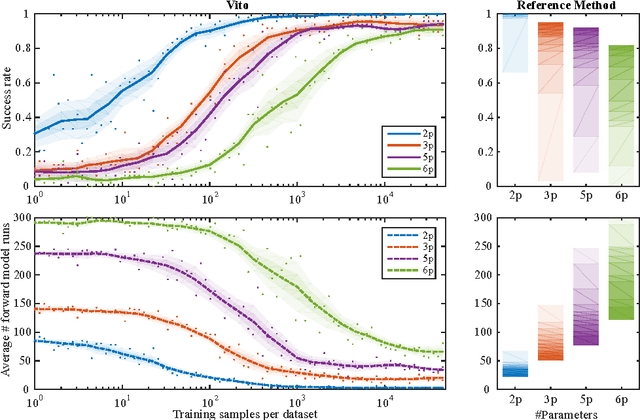

Personalization is the process of fitting a model to patient data, a critical step towards application of multi-physics computational models in clinical practice. Designing robust personalization algorithms is often a tedious, time-consuming, model- and data-specific process. We propose to use artificial intelligence concepts to learn this task, inspired by how human experts manually perform it. The problem is reformulated in terms of reinforcement learning. In an off-line phase, Vito, our self-taught artificial agent, learns a representative decision process model through exploration of the computational model: it learns how the model behaves under change of parameters. The agent then automatically learns an optimal strategy for on-line personalization. The algorithm is model-independent; applying it to a new model requires only adjusting few hyper-parameters of the agent and defining the observations to match. The full knowledge of the model itself is not required. Vito was tested in a synthetic scenario, showing that it could learn how to optimize cost functions generically. Then Vito was applied to the inverse problem of cardiac electrophysiology and the personalization of a whole-body circulation model. The obtained results suggested that Vito could achieve equivalent, if not better goodness of fit than standard methods, while being more robust (up to 11% higher success rates) and with faster (up to seven times) convergence rate. Our artificial intelligence approach could thus make personalization algorithms generalizable and self-adaptable to any patient and any model.