 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI for Autonomous Driving: A Review
May 21, 2025Generative AI (GenAI) is rapidly advancing the field of Autonomous Driving (AD), extending beyond traditional applications in text, image, and video generation. We explore how generative models can enhance automotive tasks, such as static map creation, dynamic scenario generation, trajectory forecasting, and vehicle motion planning. By examining multiple generative approaches ranging from Variational Autoencoder (VAEs) over Generative Adversarial Networks (GANs) and Invertible Neural Networks (INNs) to Generative Transformers (GTs) and Diffusion Models (DMs), we highlight and compare their capabilities and limitations for AD-specific applications. Additionally, we discuss hybrid methods integrating conventional techniques with generative approaches, and emphasize their improved adaptability and robustness. We also identify relevant datasets and outline open research questions to guide future developments in GenAI. Finally, we discuss three core challenges: safety, interpretability, and realtime capabilities, and present recommendations for image generation, dynamic scenario generation, and planning.
Inspect, Understand, Overcome: A Survey of Practical Methods for AI Safety
Apr 29, 2021The use of deep neural networks (DNNs) in safety-critical applications like mobile health and autonomous driving is challenging due to numerous model-inherent shortcomings. These shortcomings are diverse and range from a lack of generalization over insufficient interpretability to problems with malicious inputs. Cyber-physical systems employing DNNs are therefore likely to suffer from safety concerns. In recent years, a zoo of state-of-the-art techniques aiming to address these safety concerns has emerged. This work provides a structured and broad overview of them. We first identify categories of insufficiencies to then describe research activities aiming at their detection, quantification, or mitigation. Our paper addresses both machine learning experts and safety engineers: The former ones might profit from the broad range of machine learning topics covered and discussions on limitations of recent methods. The latter ones might gain insights into the specifics of modern ML methods. We moreover hope that our contribution fuels discussions on desiderata for ML systems and strategies on how to propel existing approaches accordingly.
The Random Forest Classifier in WEKA: Discussion and New Developments for Imbalanced Data
Jan 04, 2019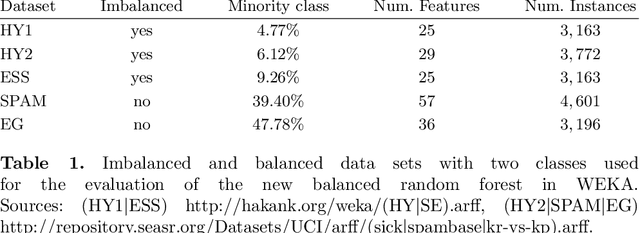
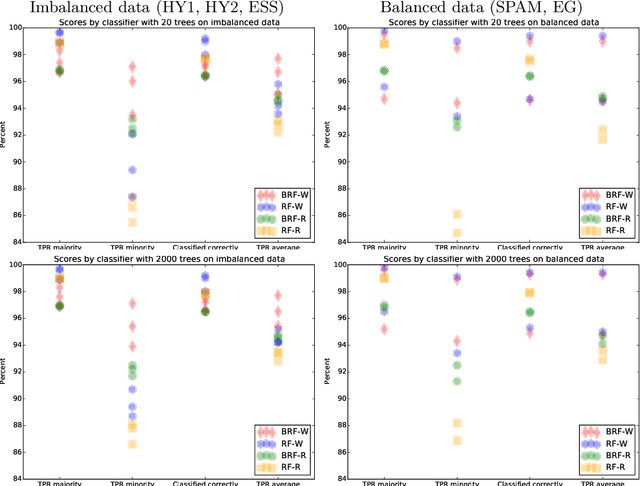
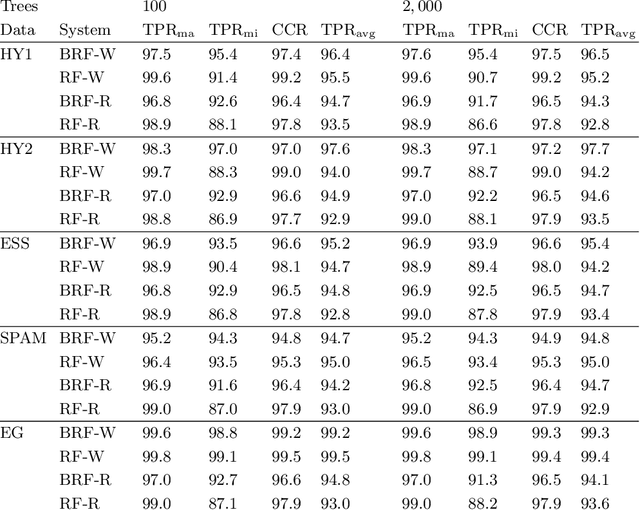
Data analysis and machine learning have become an integrative part of the modern scientific methodology, providing automated techniques to predict further information based on observations. One of these classification and regression techniques is the random forest approach. Those decision tree based predictors are best known for their good computational performance and scalability. However, in case of severely imbalanced training data, as often seen in medical studies' data with large control groups, the training algorithm or the sampling process has to be altered in order to improve the prediction quality for minority classes. In this work, a balanced random forest approach for WEKA is proposed. Furthermore, the prediction quality of the unmodified random forest implementation and the new balanced random forest version for WEKA are evaluated against reference implementations in R. Two-class problems on balanced data sets and imbalanced medical studies' data are investigated. A superior prediction quality using the proposed method for imbalanced data is shown compared to the other three techniques.