 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Random Forest Classifier in WEKA: Discussion and New Developments for Imbalanced Data
Paper and Code
Jan 04, 2019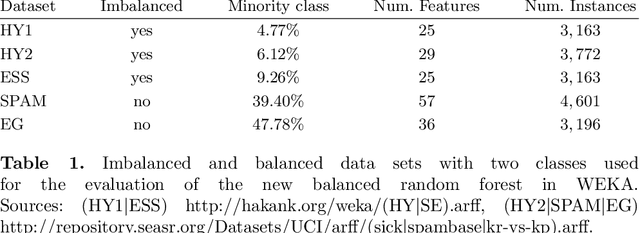
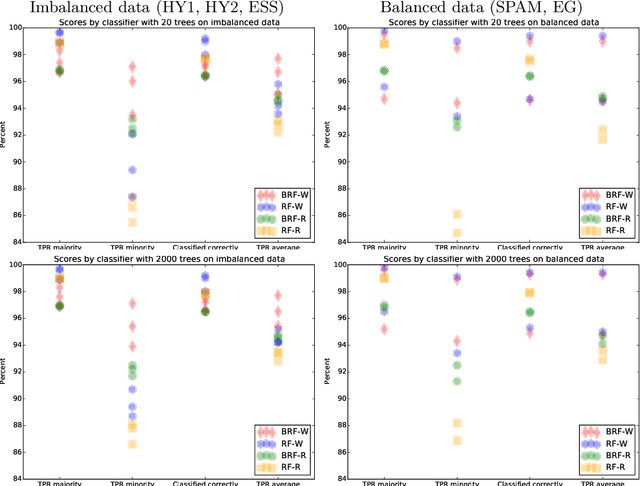
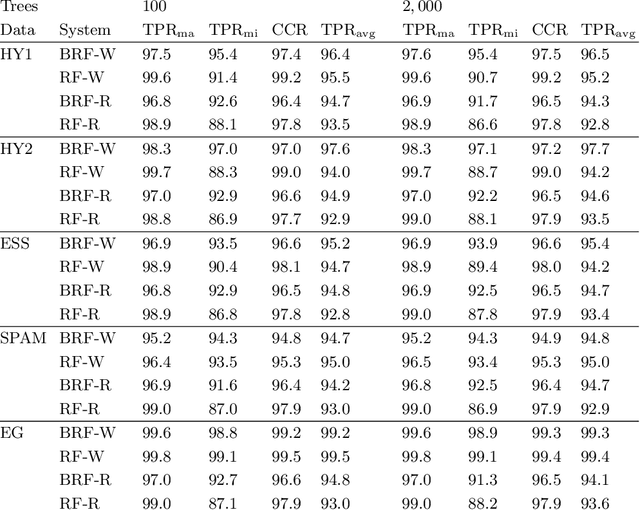
Data analysis and machine learning have become an integrative part of the modern scientific methodology, providing automated techniques to predict further information based on observations. One of these classification and regression techniques is the random forest approach. Those decision tree based predictors are best known for their good computational performance and scalability. However, in case of severely imbalanced training data, as often seen in medical studies' data with large control groups, the training algorithm or the sampling process has to be altered in order to improve the prediction quality for minority classes. In this work, a balanced random forest approach for WEKA is proposed. Furthermore, the prediction quality of the unmodified random forest implementation and the new balanced random forest version for WEKA are evaluated against reference implementations in R. Two-class problems on balanced data sets and imbalanced medical studies' data are investigated. A superior prediction quality using the proposed method for imbalanced data is shown compared to the other three techniques.