 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Writer Identification Using Convolutional Neural Network Activation Features
Feb 26, 2024Convolutional neural networks (CNNs) have recently become the state-of-the-art tool for large-scale image classification. In this work we propose the use of activation features from CNNs as local descriptors for writer identification. A global descriptor is then formed by means of GMM supervector encoding, which is further improved by normalization with the KL-Kernel. We evaluate our method on two publicly available datasets: the ICDAR 2013 benchmark database and the CVL dataset. While we perform comparably to the state of the art on CVL, our proposed method yields about 0.21 absolute improvement in terms of mAP on the challenging bilingual ICDAR dataset.
* fixed tab 1b
The Random Forest Classifier in WEKA: Discussion and New Developments for Imbalanced Data
Jan 04, 2019
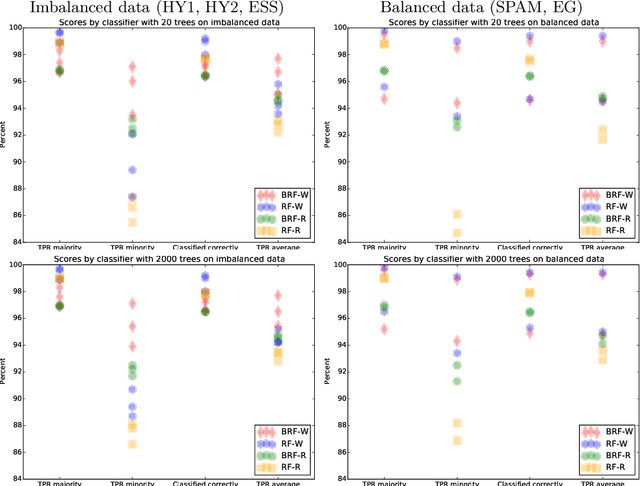
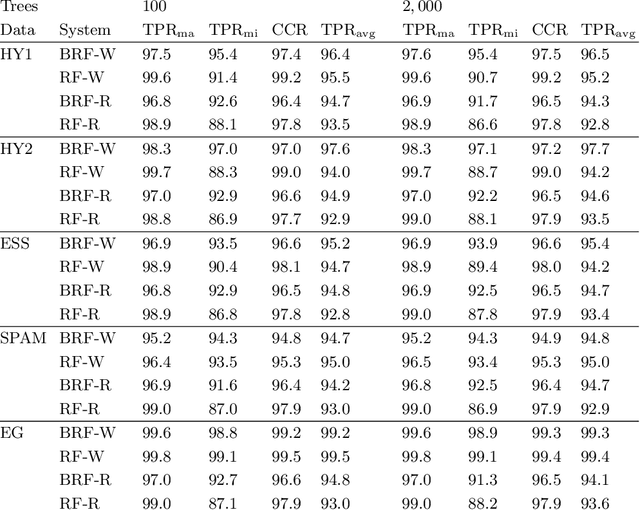
Data analysis and machine learning have become an integrative part of the modern scientific methodology, providing automated techniques to predict further information based on observations. One of these classification and regression techniques is the random forest approach. Those decision tree based predictors are best known for their good computational performance and scalability. However, in case of severely imbalanced training data, as often seen in medical studies' data with large control groups, the training algorithm or the sampling process has to be altered in order to improve the prediction quality for minority classes. In this work, a balanced random forest approach for WEKA is proposed. Furthermore, the prediction quality of the unmodified random forest implementation and the new balanced random forest version for WEKA are evaluated against reference implementations in R. Two-class problems on balanced data sets and imbalanced medical studies' data are investigated. A superior prediction quality using the proposed method for imbalanced data is shown compared to the other three techniques.
An Evaluation of Popular Copy-Move Forgery Detection Approaches
Nov 26, 2012
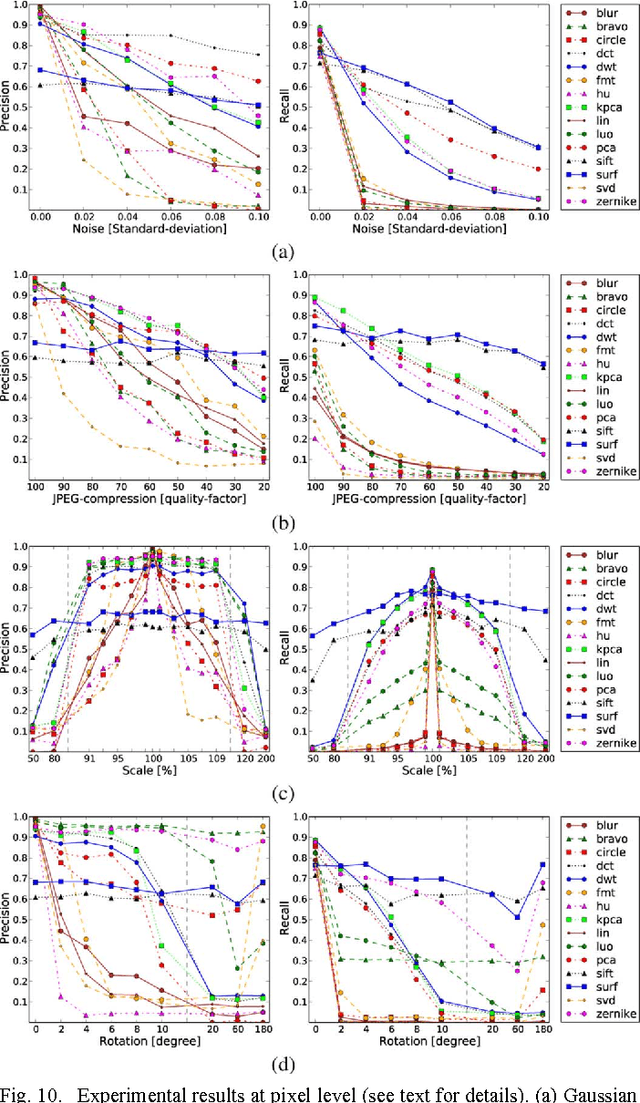
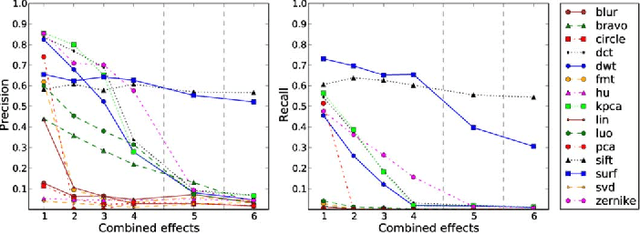
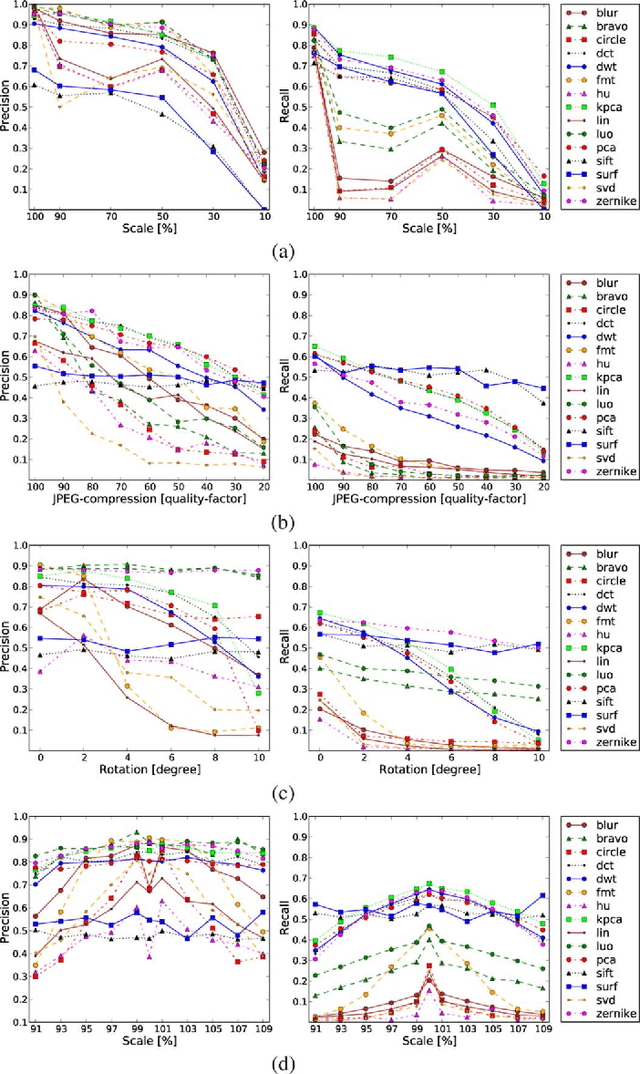
A copy-move forgery is created by copying and pasting content within the same image, and potentially post-processing it. In recent years, the detection of copy-move forgeries has become one of the most actively researched topics in blind image forensics. A considerable number of different algorithms have been proposed focusing on different types of postprocessed copies. In this paper, we aim to answer which copy-move forgery detection algorithms and processing steps (e.g., matching, filtering, outlier detection, affine transformation estimation) perform best in various postprocessing scenarios. The focus of our analysis is to evaluate the performance of previously proposed feature sets. We achieve this by casting existing algorithms in a common pipeline. In this paper, we examined the 15 most prominent feature sets. We analyzed the detection performance on a per-image basis and on a per-pixel basis. We created a challenging real-world copy-move dataset, and a software framework for systematic image manipulation. Experiments show, that the keypoint-based features SIFT and SURF, as well as the block-based DCT, DWT, KPCA, PCA and Zernike features perform very well. These feature sets exhibit the best robustness against various noise sources and downsampling, while reliably identifying the copied regions.
* Main paper: 14 pages, supplemental material: 12 pages, main paper appeared in IEEE Transaction on Information Forensics and Security