 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian Geometric-based Meta Learning
Mar 14, 2025


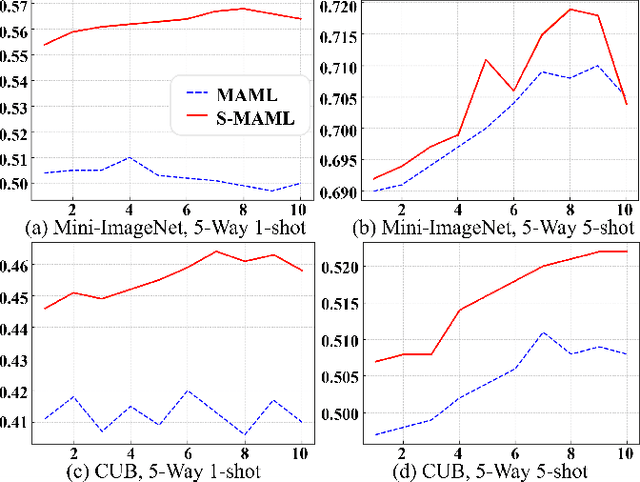
Meta-learning, or "learning to learn," aims to enable models to quickly adapt to new tasks with minimal data. While traditional methods like Model-Agnostic Meta-Learning (MAML) optimize parameters in Euclidean space, they often struggle to capture complex learning dynamics, particularly in few-shot learning scenarios. To address this limitation, we propose Stiefel-MAML, which integrates Riemannian geometry by optimizing within the Stiefel manifold, a space that naturally enforces orthogonality constraints. By leveraging the geometric structure of the Stiefel manifold, we improve parameter expressiveness and enable more efficient optimization through Riemannian gradient calculations and retraction operations. We also introduce a novel kernel-based loss function defined on the Stiefel manifold, further enhancing the model's ability to explore the parameter space. Experimental results on benchmark datasets--including Omniglot, Mini-ImageNet, FC-100, and CUB--demonstrate that Stiefel-MAML consistently outperforms traditional MAML, achieving superior performance across various few-shot learning tasks. Our findings highlight the potential of Riemannian geometry to enhance meta-learning, paving the way for future research on optimizing over different geometric structures.
Fast Adaptation with Kernel and Gradient based Meta Leaning
Nov 01, 2024Model Agnostic Meta Learning or MAML has become the standard for few-shot learning as a meta-learning problem. MAML is simple and can be applied to any model, as its name suggests. However, it often suffers from instability and computational inefficiency during both training and inference times. In this paper, we propose two algorithms to improve both the inner and outer loops of MAML, then pose an important question about what 'meta' learning truly is. Our first algorithm redefines the optimization problem in the function space to update the model using closed-form solutions instead of optimizing parameters through multiple gradient steps in the inner loop. In the outer loop, the second algorithm adjusts the learning of the meta-learner by assigning weights to the losses from each task of the inner loop. This method optimizes convergence during both the training and inference stages of MAML. In conclusion, our algorithms offer a new perspective on meta-learning and make significant discoveries in both theory and experiments. This research suggests a more efficient approach to few-shot learning and fast task adaptation compared to existing methods. Furthermore, it lays the foundation for establishing a new paradigm in meta-learning.