 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkov Chain-based Optimization Time Analysis of Bivalent Ant Colony Optimization for Sorting and LeadingOnes
May 06, 2024So far, only few bounds on the runtime behavior of Ant Colony Optimization (ACO) have been reported. To alleviate this situation, we investigate the ACO variant we call Bivalent ACO (BACO) that uses exactly two pheromone values. We provide and successfully apply a new Markov chain-based approach to calculate the expected optimization time, i. e., the expected number of iterations until the algorithm terminates. This approach allows to derive exact formulae for the expected optimization time for the problems Sorting and LeadingOnes. It turns out that the ratio of the two pheromone values significantly governs the runtime behavior of BACO. To the best of our knowledge, for the first time, we can present tight bounds for Sorting ($\Theta(n^3)$) with a specifically chosen objective function and prove the missing lower bound $\Omega(n^2)$ for LeadingOnes which, thus, is tightly bounded by $\Theta(n^2)$. We show that despite we have a drastically simplified ant algorithm with respect to the influence of the pheromones on the solving process, known bounds on the expected optimization time for the problems OneMax ($O(n\log n)$) and LeadingOnes ($O(n^2)$) can be re-produced as a by-product of our approach. Experiments validate our theoretical findings.
Artificial Intelligence for Molecular Communication
Aug 05, 2023


Molecular communication is a novel approach for data transmission between miniaturized devices, especially in contexts where electrical signals are to be avoided. The communication is based on sending molecules (or other particles) at nano scale through channel instead sending electrons over a wire. Molecular communication devices have a large potential in medical applications as they offer an alternative to antenna-based transmission systems that may not be applicable due to size, temperature, or radiation constraints. The communication is achieved by transforming a digital signal into concentrations of molecules. These molecules are then detected at the other end of the communication channel and transformed back into a digital signal. Accurately modeling the transmission channel is often not possible which may be due to a lack of data or time-varying parameters of the channel (e. g., the movements of a person wearing a medical device). This makes demodulation of the signal very difficult. Many approaches for demodulation have been discussed with one particular approach having tremendous success: artificial neural networks. These networks imitate the decision process in the human brain and are capable of reliably classifying noisy input data. Training such a network relies on a large set of training data. As molecular communication as a technology is still in its early development phase, this data is not always readily available. We discuss neural network-based demodulation approaches relying on synthetic data based on theoretical channel models as well as works using actual measurements produced by a prototype test bed. In this work, we give a general overview over the field molecular communication, discuss the challenges in the demodulations process of transmitted signals, and present approaches to these challenges that are based on artificial neural networks.
To Spike or Not to Spike? A Quantitative Comparison of SNN and CNN FPGA Implementations
Jun 22, 2023Convolutional Neural Networks (CNNs) are widely employed to solve various problems, e.g., image classification. Due to their compute- and data-intensive nature, CNN accelerators have been developed as ASICs or on FPGAs. Increasing complexity of applications has caused resource costs and energy requirements of these accelerators to grow. Spiking Neural Networks (SNNs) are an emerging alternative to CNN implementations, promising higher resource and energy efficiency. The main research question addressed in this paper is whether SNN accelerators truly meet these expectations of reduced energy requirements compared to their CNN equivalents. For this purpose, we analyze multiple SNN hardware accelerators for FPGAs regarding performance and energy efficiency. We present a novel encoding scheme of spike event queues and a novel memory organization technique to improve SNN energy efficiency further. Both techniques have been integrated into a state-of-the-art SNN architecture and evaluated for MNIST, SVHN, and CIFAR-10 datasets and corresponding network architectures on two differently sized modern FPGA platforms. For small-scale benchmarks such as MNIST, SNN designs provide rather no or little latency and energy efficiency advantages over corresponding CNN implementations. For more complex benchmarks such as SVHN and CIFAR-10, the trend reverses.
Efficient Hardware Acceleration of Sparsely Active Convolutional Spiking Neural Networks
Mar 23, 2022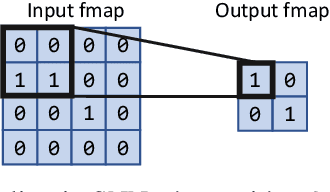
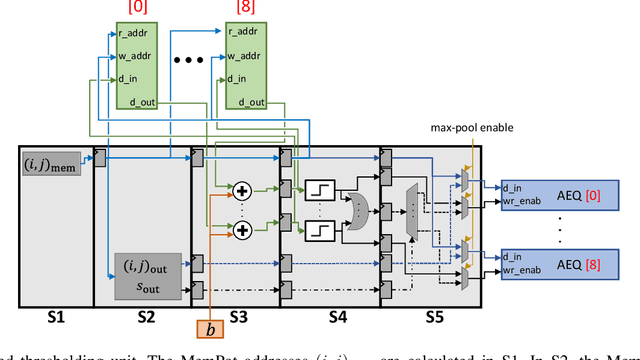
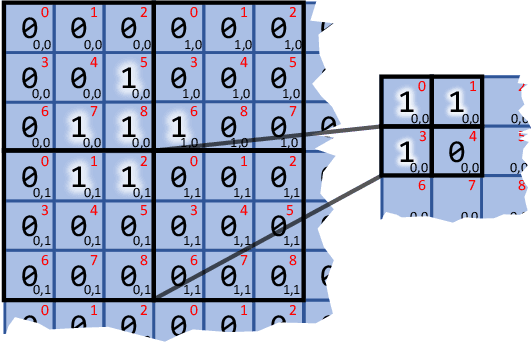
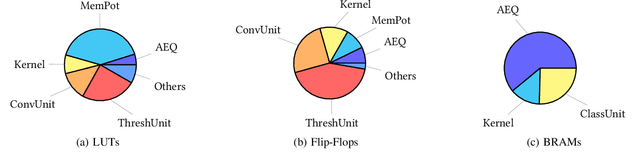
Spiking Neural Networks (SNNs) compute in an event-based matter to achieve a more efficient computation than standard Neural Networks. In SNNs, neuronal outputs (i.e. activations) are not encoded with real-valued activations but with sequences of binary spikes. The motivation of using SNNs over conventional neural networks is rooted in the special computational aspects of SNNs, especially the very high degree of sparsity of neural output activations. Well established architectures for conventional Convolutional Neural Networks (CNNs) feature large spatial arrays of Processing Elements (PEs) that remain highly underutilized in the face of activation sparsity. We propose a novel architecture that is optimized for the processing of Convolutional SNNs (CSNNs) that feature a high degree of activation sparsity. In our architecture, the main strategy is to use less but highly utilized PEs. The PE array used to perform the convolution is only as large as the kernel size, allowing all PEs to be active as long as there are spikes to process. This constant flow of spikes is ensured by compressing the feature maps (i.e. the activations) into queues that can then be processed spike by spike. This compression is performed in run-time using dedicated circuitry, leading to a self-timed scheduling. This allows the processing time to scale directly with the number of spikes. A novel memory organization scheme called memory interlacing is used to efficiently store and retrieve the membrane potentials of the individual neurons using multiple small parallel on-chip RAMs. Each RAM is hardwired to its PE, reducing switching circuitry and allowing RAMs to be located in close proximity to the respective PE. We implemented the proposed architecture on an FPGA and achieved a significant speedup compared to other implementations while needing less hardware resources and maintaining a lower energy consumption.