 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Hardware Acceleration of Sparsely Active Convolutional Spiking Neural Networks
Mar 23, 2022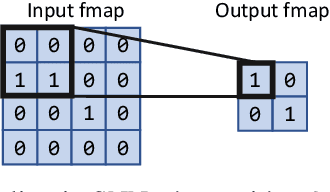
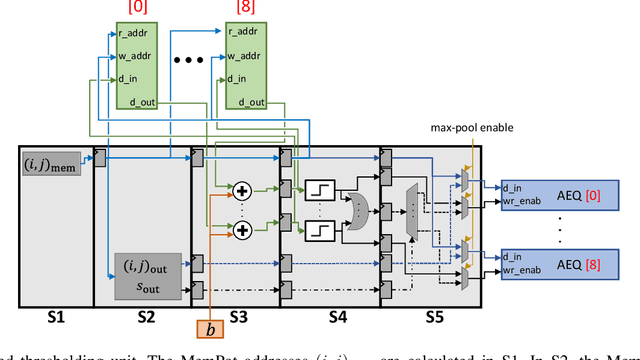
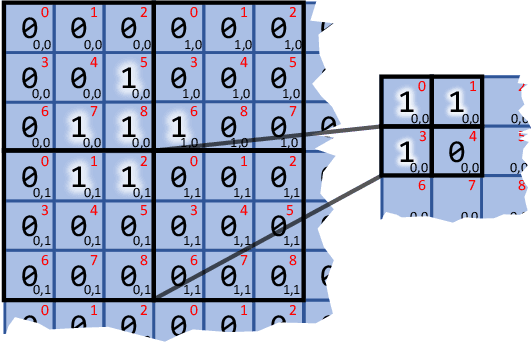
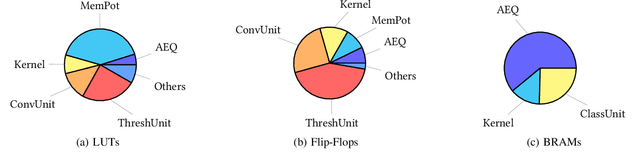
Spiking Neural Networks (SNNs) compute in an event-based matter to achieve a more efficient computation than standard Neural Networks. In SNNs, neuronal outputs (i.e. activations) are not encoded with real-valued activations but with sequences of binary spikes. The motivation of using SNNs over conventional neural networks is rooted in the special computational aspects of SNNs, especially the very high degree of sparsity of neural output activations. Well established architectures for conventional Convolutional Neural Networks (CNNs) feature large spatial arrays of Processing Elements (PEs) that remain highly underutilized in the face of activation sparsity. We propose a novel architecture that is optimized for the processing of Convolutional SNNs (CSNNs) that feature a high degree of activation sparsity. In our architecture, the main strategy is to use less but highly utilized PEs. The PE array used to perform the convolution is only as large as the kernel size, allowing all PEs to be active as long as there are spikes to process. This constant flow of spikes is ensured by compressing the feature maps (i.e. the activations) into queues that can then be processed spike by spike. This compression is performed in run-time using dedicated circuitry, leading to a self-timed scheduling. This allows the processing time to scale directly with the number of spikes. A novel memory organization scheme called memory interlacing is used to efficiently store and retrieve the membrane potentials of the individual neurons using multiple small parallel on-chip RAMs. Each RAM is hardwired to its PE, reducing switching circuitry and allowing RAMs to be located in close proximity to the respective PE. We implemented the proposed architecture on an FPGA and achieved a significant speedup compared to other implementations while needing less hardware resources and maintaining a lower energy consumption.