 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHipaccVX: Wedding of OpenVX and DSL-based Code Generation
Aug 26, 2020
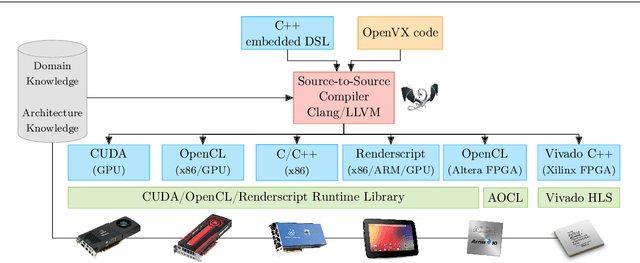


Writing programs for heterogeneous platforms optimized for high performance is hard since this requires the code to be tuned at a low level with architecture-specific optimizations that are most times based on fundamentally differing programming paradigms and languages. OpenVX promises to solve this issue for computer vision applications with a royalty-free industry standard that is based on a graph-execution model. Yet, the OpenVX' algorithm space is constrained to a small set of vision functions. This hinders accelerating computations that are not included in the standard. In this paper, we analyze OpenVX vision functions to find an orthogonal set of computational abstractions. Based on these abstractions, we couple an existing Domain-Specific Language (DSL) back end to the OpenVX environment and provide language constructs to the programmer for the definition of user-defined nodes. In this way, we enable optimizations that are not possible to detect with OpenVX graph implementations using the standard computer vision functions. These optimizations can double the throughput on an Nvidia GTX GPU and decrease the resource usage of a Xilinx Zynq FPGA by 50% for our benchmarks. Finally, we show that our proposed compiler framework, called HipaccVX, can achieve better results than the state-of-the-art approaches Nvidia VisionWorks and Halide-HLS.