 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGumbel-MPNN: Graph Rewiring with Gumbel-Softmax
Aug 24, 2025Graph homophily has been considered an essential property for message-passing neural networks (MPNN) in node classification. Recent findings suggest that performance is more closely tied to the consistency of neighborhood class distributions. We demonstrate that the MPNN performance depends on the number of components of the overall neighborhood distribution within a class. By breaking down the classes into their neighborhood distribution components, we increase measures of neighborhood distribution informativeness but do not observe an improvement in MPNN performance. We propose a Gumbel-Softmax-based rewiring method that reduces deviations in neighborhood distributions. Our results show that our new method enhances neighborhood informativeness, handles long-range dependencies, mitigates oversquashing, and increases the classification performance of the MPNN. The code is available at https://github.com/Bobowner/Gumbel-Softmax-MPNN.
Active Few-Shot Learning for Vertex Classification Starting from an Unlabeled Dataset
Apr 25, 2025Despite the ample availability of graph data, obtaining vertex labels is a tedious and expensive task. Therefore, it is desirable to learn from a few labeled vertices only. Existing few-shot learners assume a class oracle, which provides labeled vertices for a desired class. However, such an oracle is not available in a real-world setting, i.e., when drawing a vertex for labeling it is unknown to which class the vertex belongs. Few-shot learners are often combined with prototypical networks, while classical semi-supervised vertex classification uses discriminative models, e.g., Graph Convolutional Networks (GCN). In this paper, we train our models by iteratively prompting a human annotator with vertices to annotate. We perform three experiments where we continually relax our assumptions. First, we assume a class oracle, i.e., the human annotator is provided with an equal number of vertices to label for each class. We denote this as "Balanced Sampling''. In the subsequent experiment, "Unbalanced Sampling,'' we replace the class oracle with $k$-medoids clustering and draw vertices to label from the clusters. In the last experiment, the "Unknown Number of Classes,'' we no longer assumed we knew the number and distribution of classes. Our results show that prototypical models outperform discriminative models in all experiments when fewer than $20$ samples per class are available. While dropping the assumption of the class oracle for the "Unbalanced Sampling'' experiment reduces the performance of the GCN by $9\%$, the prototypical network loses only $1\%$ on average. For the "Unknown Number of Classes'' experiment, the average performance for both models decreased further by $1\%$. Source code: https://github.com/Ximsa/2023-felix-ma
Edge-Splitting MLP: Node Classification on Homophilic and Heterophilic Graphs without Message Passing
Dec 11, 2024Message Passing Neural Networks (MPNNs) have demonstrated remarkable success in node classification on homophilic graphs. It has been shown that they do not solely rely on homophily but on neighborhood distributions of nodes, i.e., consistency of the neighborhood label distribution within the same class. MLP-based models do not use message passing, \eg Graph-MLP incorporates the neighborhood in a separate loss function. These models are faster and more robust to edge noise. Graph-MLP maps adjacent nodes closer in the embedding space but is unaware of the neighborhood pattern of the labels, i.e., relies solely on homophily. Edge Splitting GNN (ES-GNN) is a model specialized for heterophilic graphs and splits the edges into task-relevant and task-irrelevant, respectively. To mitigate the limitations of Graph-MLP on heterophilic graphs, we propose ES-MLP that combines Graph-MLP with an edge-splitting mechanism from ES-GNN. It incorporates the edge splitting into the loss of Graph-MLP to learn two separate adjacency matrices based on relevant and irrelevant feature pairs. Our experiments on seven datasets with six baselines show that ES-MLP is on par with homophilic and heterophilic models on all datasets without using edges during inference. We show that ES-MLP is robust to multiple types of edge noise during inference and that its inference time is two to five times faster than that of commonly used MPNNs. The source code is available at https://github.com/MatthiasKohn/ES-MLP.
Lifelong Graph Summarization with Neural Networks: 2012, 2022, and a Time Warp
Jul 25, 2024



Summarizing web graphs is challenging due to the heterogeneity of the modeled information and its changes over time. We investigate the use of neural networks for lifelong graph summarization. Assuming we observe the web graph at a certain time, we train the networks to summarize graph vertices. We apply this trained network to summarize the vertices of the changed graph at the next point in time. Subsequently, we continue training and evaluating the network to perform lifelong graph summarization. We use the GNNs Graph-MLP and GraphSAINT, as well as an MLP baseline, to summarize the temporal graphs. We compare $1$-hop and $2$-hop summaries. We investigate the impact of reusing parameters from a previous snapshot by measuring the backward and forward transfer and the forgetting rate of the neural networks. Our extensive experiments on ten weekly snapshots of a web graph with over $100$M edges, sampled in 2012 and 2022, show that all networks predominantly use $1$-hop information to determine the summary, even when performing $2$-hop summarization. Due to the heterogeneity of web graphs, in some snapshots, the $2$-hop summary produces over ten times more vertex summaries than the $1$-hop summary. When using the network trained on the last snapshot from 2012 and applying it to the first snapshot of 2022, we observe a strong drop in accuracy. We attribute this drop over the ten-year time warp to the strongly increased heterogeneity of the web graph in 2022.
POWN: Prototypical Open-World Node Classification
Jun 14, 2024



We consider the problem of \textit{true} open-world semi-supervised node classification, in which nodes in a graph either belong to known or new classes, with the latter not present during training. Existing methods detect and reject new classes but fail to distinguish between different new classes. We adapt existing methods and show they do not solve the problem sufficiently. We introduce a novel end-to-end approach for classification into known classes and new classes based on class prototypes, which we call Prototypical Open-World Learning for Node Classification (POWN). Our method combines graph semi-supervised learning, self-supervised learning, and pseudo-labeling to learn prototype representations of new classes in a zero-shot way. In contrast to existing solutions from the vision domain, POWN does not require data augmentation techniques for node classification. Experiments on benchmark datasets demonstrate the effectiveness of POWN, where it outperforms baselines by up to $20\%$ accuracy on the small and up to $30\%$ on the large datasets. Source code is available at https://github.com/Bobowner/POWN.
Radar-Based Recognition of Static Hand Gestures in American Sign Language
Feb 20, 2024



In the fast-paced field of human-computer interaction (HCI) and virtual reality (VR), automatic gesture recognition has become increasingly essential. This is particularly true for the recognition of hand signs, providing an intuitive way to effortlessly navigate and control VR and HCI applications. Considering increased privacy requirements, radar sensors emerge as a compelling alternative to cameras. They operate effectively in low-light conditions without capturing identifiable human details, thanks to their lower resolution and distinct wavelength compared to visible light. While previous works predominantly deploy radar sensors for dynamic hand gesture recognition based on Doppler information, our approach prioritizes classification using an imaging radar that operates on spatial information, e.g. image-like data. However, generating large training datasets required for neural networks (NN) is a time-consuming and challenging process, often falling short of covering all potential scenarios. Acknowledging these challenges, this study explores the efficacy of synthetic data generated by an advanced radar ray-tracing simulator. This simulator employs an intuitive material model that can be adjusted to introduce data diversity. Despite exclusively training the NN on synthetic data, it demonstrates promising performance when put to the test with real measurement data. This emphasizes the practicality of our methodology in overcoming data scarcity challenges and advancing the field of automatic gesture recognition in VR and HCI applications.
Open-World Lifelong Graph Learning
Oct 19, 2023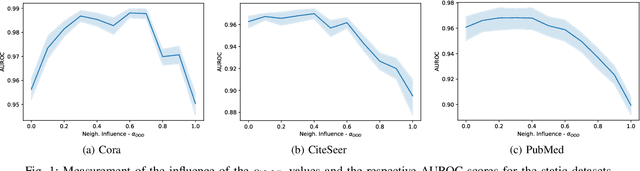
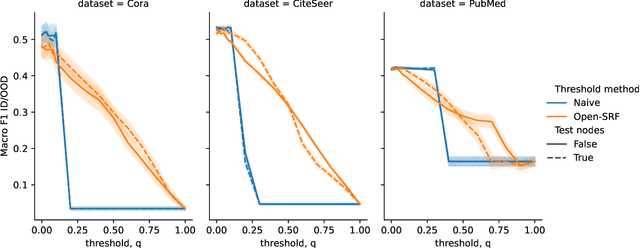
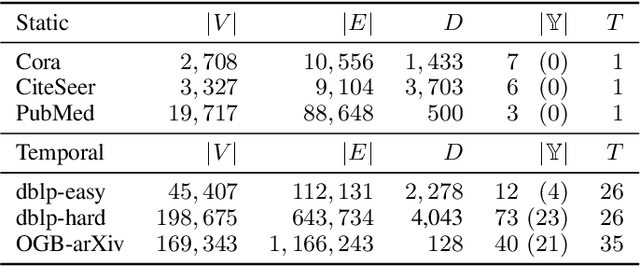
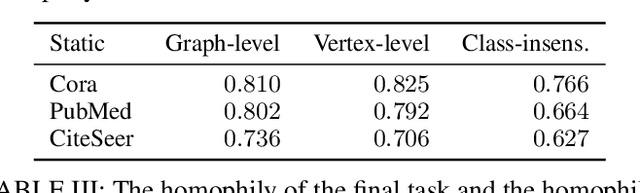
We study the problem of lifelong graph learning in an open-world scenario, where a model needs to deal with new tasks and potentially unknown classes. We utilize Out-of-Distribution (OOD) detection methods to recognize new classes and adapt existing non-graph OOD detection methods to graph data. Crucially, we suggest performing new class detection by combining OOD detection methods with information aggregated from the graph neighborhood. Most OOD detection methods avoid determining a crisp threshold for deciding whether a vertex is OOD. To tackle this problem, we propose a Weakly-supervised Relevance Feedback (Open-WRF) method, which decreases the sensitivity to thresholds in OOD detection. We evaluate our approach on six benchmark datasets. Our results show that the proposed neighborhood aggregation method for OOD scores outperforms existing methods independent of the underlying graph neural network. Furthermore, we demonstrate that our Open-WRF method is more robust to threshold selection and analyze the influence of graph neighborhood on OOD detection. The aggregation and threshold methods are compatible with arbitrary graph neural networks and OOD detection methods, making our approach versatile and applicable to many real-world applications.
Concept for an Automatic Annotation of Automotive Radar Data Using AI-segmented Aerial Camera Images
Sep 01, 2023



This paper presents an approach to automatically annotate automotive radar data with AI-segmented aerial camera images. For this, the images of an unmanned aerial vehicle (UAV) above a radar vehicle are panoptically segmented and mapped in the ground plane onto the radar images. The detected instances and segments in the camera image can then be applied directly as labels for the radar data. Owing to the advantageous bird's eye position, the UAV camera does not suffer from optical occlusion and is capable of creating annotations within the complete field of view of the radar. The effectiveness and scalability are demonstrated in measurements, where 589 pedestrians in the radar data were automatically labeled within 2 minutes.
Super-Resolution Radar Imaging with Sparse Arrays Using a Deep Neural Network Trained with Enhanced Virtual Data
Jun 16, 2023



This paper introduces a method based on a deep neural network (DNN) that is perfectly capable of processing radar data from extremely thinned radar apertures. The proposed DNN processing can provide both aliasing-free radar imaging and super-resolution. The results are validated by measuring the detection performance on realistic simulation data and by evaluating the Point-Spread-function (PSF) and the target-separation performance on measured point-like targets. Also, a qualitative evaluation of a typical automotive scene is conducted. It is shown that this approach can outperform state-of-the-art subspace algorithms and also other existing machine learning solutions. The presented results suggest that machine learning approaches trained with sufficiently sophisticated virtual input data are a very promising alternative to compressed sensing and subspace approaches in radar signal processing. The key to this performance is that the DNN is trained using realistic simulation data that perfectly mimic a given sparse antenna radar array hardware as the input. As ground truth, ultra-high resolution data from an enhanced virtual radar are simulated. Contrary to other work, the DNN utilizes the complete radar cube and not only the antenna channel information at certain range-Doppler detections. After training, the proposed DNN is capable of sidelobe- and ambiguity-free imaging. It simultaneously delivers nearly the same resolution and image quality as would be achieved with a fully occupied array.
Implementation of Real-Time Automotive SAR Imaging
Jun 16, 2023



This paper presents measures to reduce the computation time of automotive synthetic aperture radar (SAR) imaging to achieve real-time capability. For this, the image formation, which is based on the Back-Projection algorithm, was thoroughly analyzed. Various optimizations were individually tested and analyzed on graphics processing units (GPU). Apart from the time reduction gained from these measures, the data size needed for processing was also drastically decreased. With a combination of all measures, a high-resolution SAR image of 30 m by 30 m that combines 8192 chirps can be reconstructed in less than 30 ms using a standard GPU. It is thus demonstrated that a real-time implementation of automotive SAR is possible.