 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing IMU-Based Online Handwriting Recognition via Contrastive Learning with Zero Inference Overhead
Feb 04, 2026Online handwriting recognition using inertial measurement units opens up handwriting on paper as input for digital devices. Doing it on edge hardware improves privacy and lowers latency, but entails memory constraints. To address this, we propose Error-enhanced Contrastive Handwriting Recognition (ECHWR), a training framework designed to improve feature representation and recognition accuracy without increasing inference costs. ECHWR utilizes a temporary auxiliary branch that aligns sensor signals with semantic text embeddings during the training phase. This alignment is maintained through a dual contrastive objective: an in-batch contrastive loss for general modality alignment and a novel error-based contrastive loss that distinguishes between correct signals and synthetic hard negatives. The auxiliary branch is discarded after training, which allows the deployed model to keep its original, efficient architecture. Evaluations on the OnHW-Words500 dataset show that ECHWR significantly outperforms state-of-the-art baselines, reducing character error rates by up to 7.4% on the writer-independent split and 10.4% on the writer-dependent split. Finally, although our ablation studies indicate that solving specific challenges require specific architectural and objective configurations, error-based contrastive loss shows its effectiveness for handling unseen writing styles.
Benchmarking Content-Based Puzzle Solvers on Corrupted Jigsaw Puzzles
Jul 10, 2025Content-based puzzle solvers have been extensively studied, demonstrating significant progress in computational techniques. However, their evaluation often lacks realistic challenges crucial for real-world applications, such as the reassembly of fragmented artefacts or shredded documents. In this work, we investigate the robustness of State-Of-The-Art content-based puzzle solvers introducing three types of jigsaw puzzle corruptions: missing pieces, eroded edges, and eroded contents. Evaluating both heuristic and deep learning-based solvers, we analyse their ability to handle these corruptions and identify key limitations. Our results show that solvers developed for standard puzzles have a rapid decline in performance if more pieces are corrupted. However, deep learning models can significantly improve their robustness through fine-tuning with augmented data. Notably, the advanced Positional Diffusion model adapts particularly well, outperforming its competitors in most experiments. Based on our findings, we highlight promising research directions for enhancing the automated reconstruction of real-world artefacts.
How Intermodal Interaction Affects the Performance of Deep Multimodal Fusion for Mixed-Type Time Series
Jun 21, 2024Mixed-type time series (MTTS) is a bimodal data type that is common in many domains, such as healthcare, finance, environmental monitoring, and social media. It consists of regularly sampled continuous time series and irregularly sampled categorical event sequences. The integration of both modalities through multimodal fusion is a promising approach for processing MTTS. However, the question of how to effectively fuse both modalities remains open. In this paper, we present a comprehensive evaluation of several deep multimodal fusion approaches for MTTS forecasting. Our comparison includes three fusion types (early, intermediate, and late) and five fusion methods (concatenation, weighted mean, weighted mean with correlation, gating, and feature sharing). We evaluate these fusion approaches on three distinct datasets, one of which was generated using a novel framework. This framework allows for the control of key data properties, such as the strength and direction of intermodal interactions, modality imbalance, and the degree of randomness in each modality, providing a more controlled environment for testing fusion approaches. Our findings show that the performance of different fusion approaches can be substantially influenced by the direction and strength of intermodal interactions. The study reveals that early and intermediate fusion approaches excel at capturing fine-grained and coarse-grained cross-modal features, respectively. These findings underscore the crucial role of intermodal interactions in determining the most effective fusion strategy for MTTS forecasting.
Large-Scale Dataset Pruning in Adversarial Training through Data Importance Extrapolation
Jun 19, 2024Their vulnerability to small, imperceptible attacks limits the adoption of deep learning models to real-world systems. Adversarial training has proven to be one of the most promising strategies against these attacks, at the expense of a substantial increase in training time. With the ongoing trend of integrating large-scale synthetic data this is only expected to increase even further. Thus, the need for data-centric approaches that reduce the number of training samples while maintaining accuracy and robustness arises. While data pruning and active learning are prominent research topics in deep learning, they are as of now largely unexplored in the adversarial training literature. We address this gap and propose a new data pruning strategy based on extrapolating data importance scores from a small set of data to a larger set. In an empirical evaluation, we demonstrate that extrapolation-based pruning can efficiently reduce dataset size while maintaining robustness.
Achieving Efficient and Realistic Full-Radar Simulations and Automatic Data Annotation by exploiting Ray Meta Data of a Radar Ray Tracing Simulator
May 23, 2023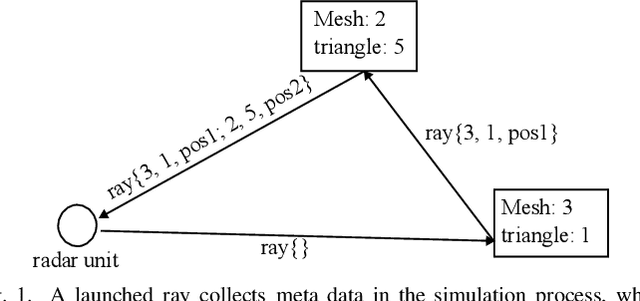
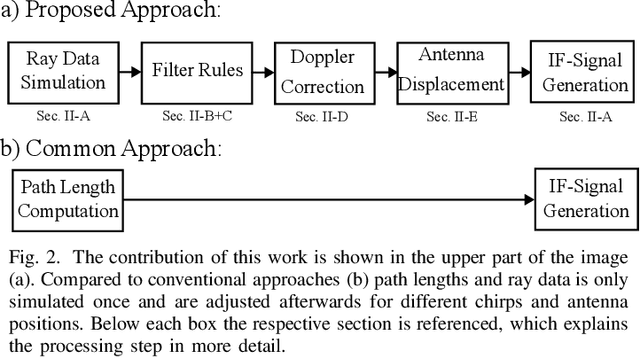
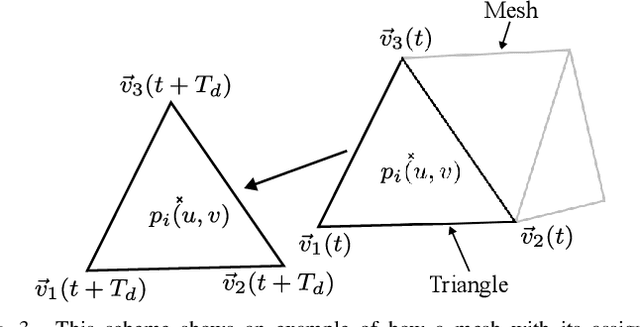
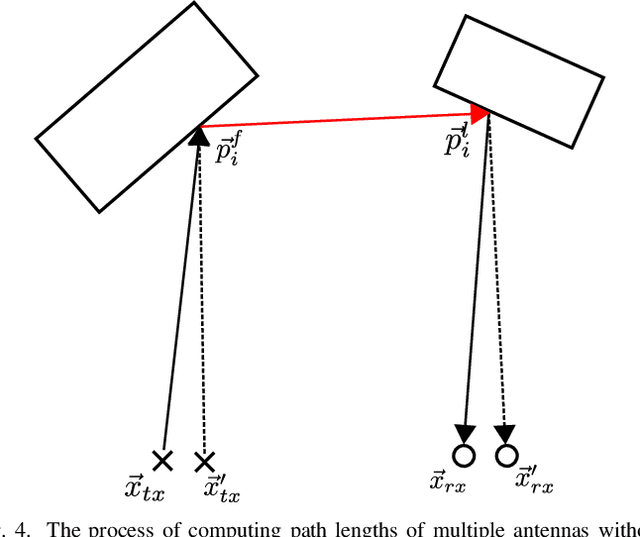
In this work a novel radar simulation concept is introduced that allows to simulate realistic radar data for Range, Doppler, and for arbitrary antenna positions in an efficient way. Further, it makes it possible to automatically annotate the simulated radar signal by allowing to decompose it into different parts. This approach allows not only almost perfect annotations possible, but also allows the annotation of exotic effects, such as multi-path effects or to label signal parts originating from different parts of an object. This is possible by adapting the computation process of a Monte Carlo shooting and bouncing rays (SBR) simulator. By considering the hits of each simulated ray, various meta data can be stored such as hit position, mesh pointer, object IDs, and many more. This collected meta data can then be utilized to predict the change of path lengths introduced by object motion to obtain Doppler information or to apply specific ray filter rules in order obtain radar signals that only fulfil specific conditions, such as multiple bounces or containing specific object IDs. Using this approach, perfect and otherwise almost impossible annotations schemes can be realized.
Raising the Bar for Certified Adversarial Robustness with Diffusion Models
May 17, 2023Certified defenses against adversarial attacks offer formal guarantees on the robustness of a model, making them more reliable than empirical methods such as adversarial training, whose effectiveness is often later reduced by unseen attacks. Still, the limited certified robustness that is currently achievable has been a bottleneck for their practical adoption. Gowal et al. and Wang et al. have shown that generating additional training data using state-of-the-art diffusion models can considerably improve the robustness of adversarial training. In this work, we demonstrate that a similar approach can substantially improve deterministic certified defenses. In addition, we provide a list of recommendations to scale the robustness of certified training approaches. One of our main insights is that the generalization gap, i.e., the difference between the training and test accuracy of the original model, is a good predictor of the magnitude of the robustness improvement when using additional generated data. Our approach achieves state-of-the-art deterministic robustness certificates on CIFAR-10 for the $\ell_2$ ($\epsilon = 36/255$) and $\ell_\infty$ ($\epsilon = 8/255$) threat models, outperforming the previous best results by $+3.95\%$ and $+1.39\%$, respectively. Furthermore, we report similar improvements for CIFAR-100.
FastAMI -- a Monte Carlo Approach to the Adjustment for Chance in Clustering Comparison Metrics
May 03, 2023Clustering is at the very core of machine learning, and its applications proliferate with the increasing availability of data. However, as datasets grow, comparing clusterings with an adjustment for chance becomes computationally difficult, preventing unbiased ground-truth comparisons and solution selection. We propose FastAMI, a Monte Carlo-based method to efficiently approximate the Adjusted Mutual Information (AMI) and extend it to the Standardized Mutual Information (SMI). The approach is compared with the exact calculation and a recently developed variant of the AMI based on pairwise permutations, using both synthetic and real data. In contrast to the exact calculation our method is fast enough to enable these adjusted information-theoretic comparisons for large datasets while maintaining considerably more accurate results than the pairwise approach.
Just a Matter of Scale? Reevaluating Scale Equivariance in Convolutional Neural Networks
Nov 18, 2022The widespread success of convolutional neural networks may largely be attributed to their intrinsic property of translation equivariance. However, convolutions are not equivariant to variations in scale and fail to generalize to objects of different sizes. Despite recent advances in this field, it remains unclear how well current methods generalize to unobserved scales on real-world data and to what extent scale equivariance plays a role. To address this, we propose the novel Scaled and Translated Image Recognition (STIR) benchmark based on four different domains. Additionally, we introduce a new family of models that applies many re-scaled kernels with shared weights in parallel and then selects the most appropriate one. Our experimental results on STIR show that both the existing and proposed approaches can improve generalization across scales compared to standard convolutions. We also demonstrate that our family of models is able to generalize well towards larger scales and improve scale equivariance. Moreover, due to their unique design we can validate that kernel selection is consistent with input scale. Even so, none of the evaluated models maintain their performance for large differences in scale, demonstrating that a general understanding of how scale equivariance can improve generalization and robustness is still lacking.
Improving Robustness against Real-World and Worst-Case Distribution Shifts through Decision Region Quantification
May 19, 2022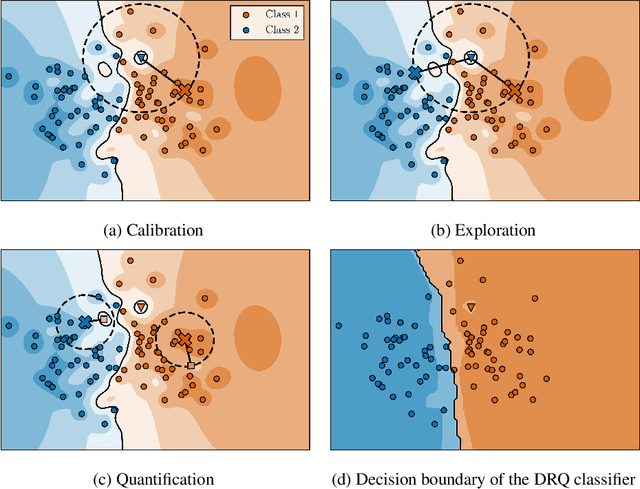
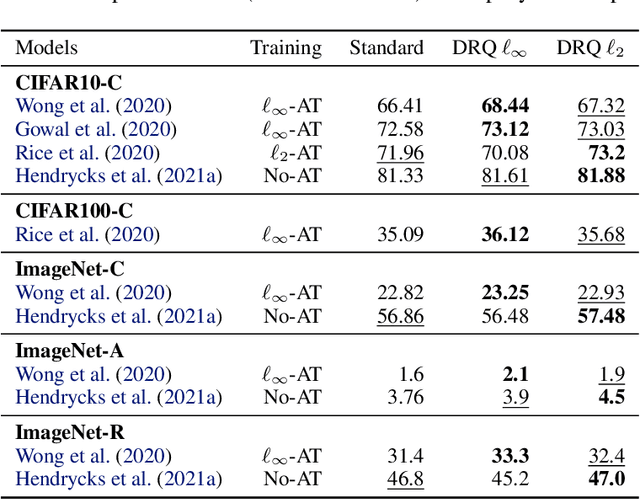

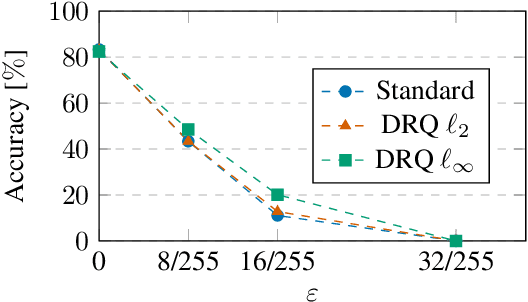
The reliability of neural networks is essential for their use in safety-critical applications. Existing approaches generally aim at improving the robustness of neural networks to either real-world distribution shifts (e.g., common corruptions and perturbations, spatial transformations, and natural adversarial examples) or worst-case distribution shifts (e.g., optimized adversarial examples). In this work, we propose the Decision Region Quantification (DRQ) algorithm to improve the robustness of any differentiable pre-trained model against both real-world and worst-case distribution shifts in the data. DRQ analyzes the robustness of local decision regions in the vicinity of a given data point to make more reliable predictions. We theoretically motivate the DRQ algorithm by showing that it effectively smooths spurious local extrema in the decision surface. Furthermore, we propose an implementation using targeted and untargeted adversarial attacks. An extensive empirical evaluation shows that DRQ increases the robustness of adversarially and non-adversarially trained models against real-world and worst-case distribution shifts on several computer vision benchmark datasets.
Behind the Machine's Gaze: Biologically Constrained Neural Networks Exhibit Human-like Visual Attention
Apr 19, 2022
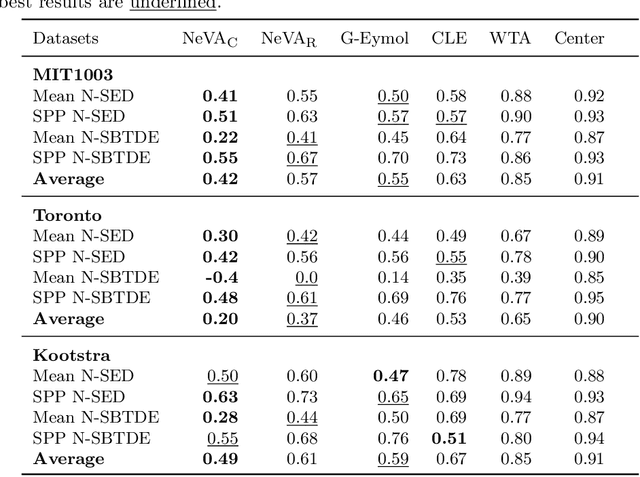
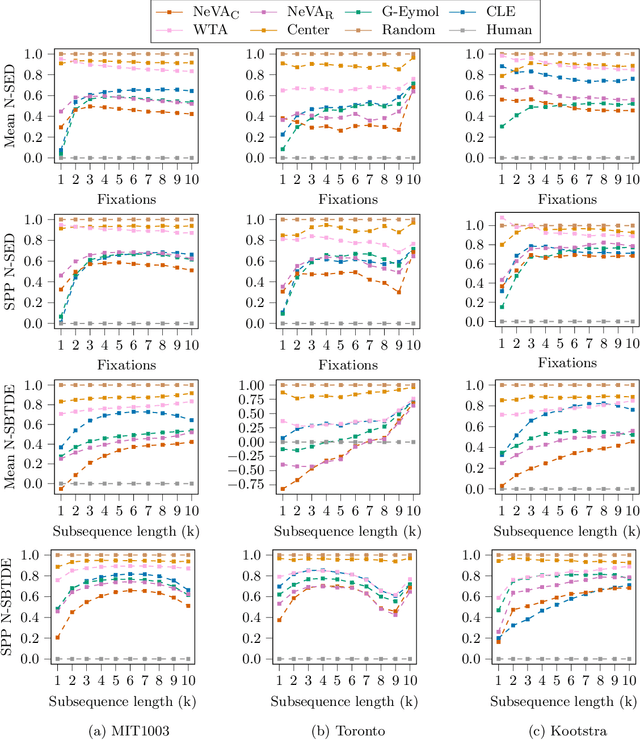

By and large, existing computational models of visual attention tacitly assume perfect vision and full access to the stimulus and thereby deviate from foveated biological vision. Moreover, modelling top-down attention is generally reduced to the integration of semantic features without incorporating the signal of a high-level visual tasks that have shown to partially guide human attention. We propose the Neural Visual Attention (NeVA) algorithm to generate visual scanpaths in a top-down manner. With our method, we explore the ability of neural networks on which we impose the biological constraints of foveated vision to generate human-like scanpaths. Thereby, the scanpaths are generated to maximize the performance with respect to the underlying visual task (i.e., classification or reconstruction). Extensive experiments show that the proposed method outperforms state-of-the-art unsupervised human attention models in terms of similarity to human scanpaths. Additionally, the flexibility of the framework allows to quantitatively investigate the role of different tasks in the generated visual behaviours. Finally, we demonstrate the superiority of the approach in a novel experiment that investigates the utility of scanpaths in real-world applications, where imperfect viewing conditions are given.