 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Robustness against Real-World and Worst-Case Distribution Shifts through Decision Region Quantification
May 19, 2022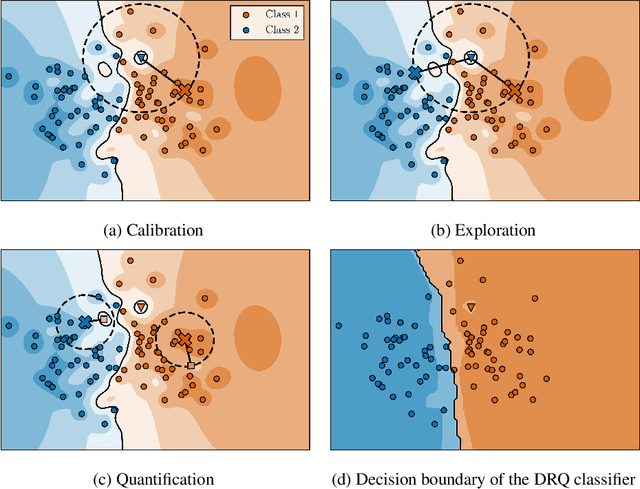
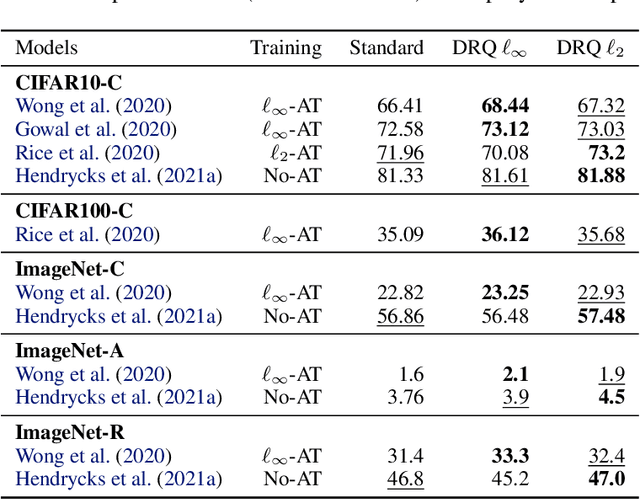

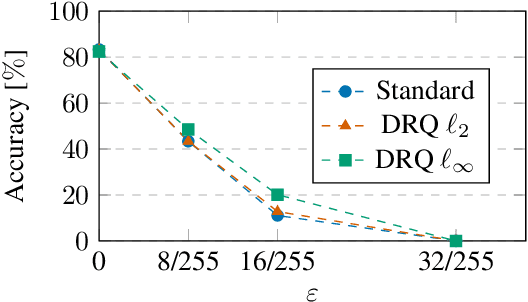
The reliability of neural networks is essential for their use in safety-critical applications. Existing approaches generally aim at improving the robustness of neural networks to either real-world distribution shifts (e.g., common corruptions and perturbations, spatial transformations, and natural adversarial examples) or worst-case distribution shifts (e.g., optimized adversarial examples). In this work, we propose the Decision Region Quantification (DRQ) algorithm to improve the robustness of any differentiable pre-trained model against both real-world and worst-case distribution shifts in the data. DRQ analyzes the robustness of local decision regions in the vicinity of a given data point to make more reliable predictions. We theoretically motivate the DRQ algorithm by showing that it effectively smooths spurious local extrema in the decision surface. Furthermore, we propose an implementation using targeted and untargeted adversarial attacks. An extensive empirical evaluation shows that DRQ increases the robustness of adversarially and non-adversarially trained models against real-world and worst-case distribution shifts on several computer vision benchmark datasets.
Exploring Misclassifications of Robust Neural Networks to Enhance Adversarial Attacks
May 25, 2021

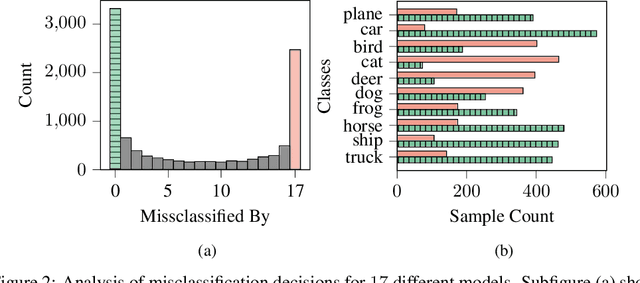
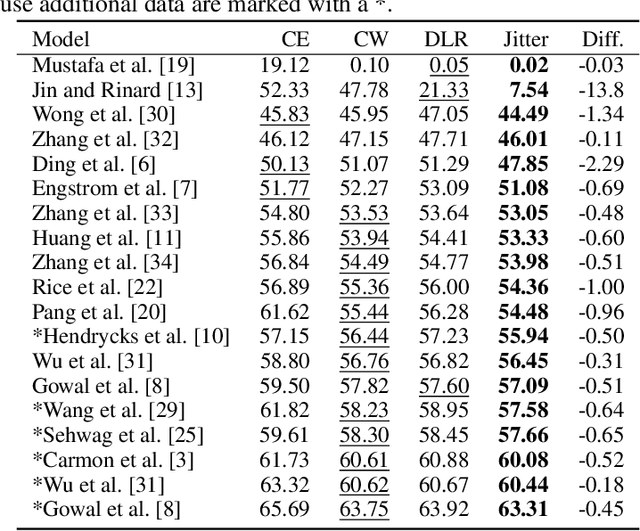
Progress in making neural networks more robust against adversarial attacks is mostly marginal, despite the great efforts of the research community. Moreover, the robustness evaluation is often imprecise, making it difficult to identify promising approaches. We analyze the classification decisions of 19 different state-of-the-art neural networks trained to be robust against adversarial attacks. Our findings suggest that current untargeted adversarial attacks induce misclassification towards only a limited amount of different classes. Additionally, we observe that both over- and under-confidence in model predictions result in an inaccurate assessment of model robustness. Based on these observations, we propose a novel loss function for adversarial attacks that consistently improves attack success rate compared to prior loss functions for 19 out of 19 analyzed models.
CLIP: Cheap Lipschitz Training of Neural Networks
Mar 23, 2021
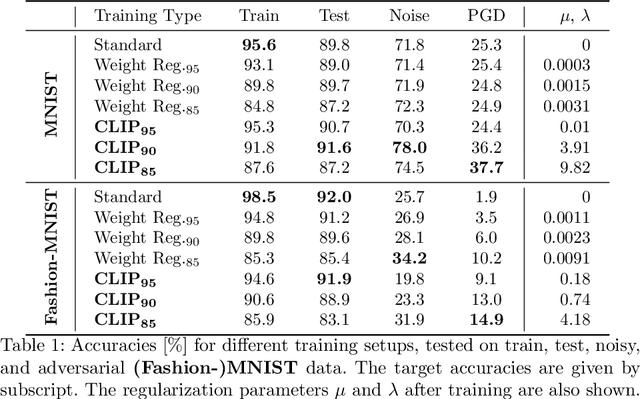
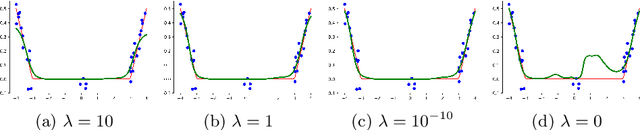
Despite the large success of deep neural networks (DNN) in recent years, most neural networks still lack mathematical guarantees in terms of stability. For instance, DNNs are vulnerable to small or even imperceptible input perturbations, so called adversarial examples, that can cause false predictions. This instability can have severe consequences in applications which influence the health and safety of humans, e.g., biomedical imaging or autonomous driving. While bounding the Lipschitz constant of a neural network improves stability, most methods rely on restricting the Lipschitz constants of each layer which gives a poor bound for the actual Lipschitz constant. In this paper we investigate a variational regularization method named CLIP for controlling the Lipschitz constant of a neural network, which can easily be integrated into the training procedure. We mathematically analyze the proposed model, in particular discussing the impact of the chosen regularization parameter on the output of the network. Finally, we numerically evaluate our method on both a nonlinear regression problem and the MNIST and Fashion-MNIST classification databases, and compare our results with a weight regularization approach.
Identifying Untrustworthy Predictions in Neural Networks by Geometric Gradient Analysis
Feb 24, 2021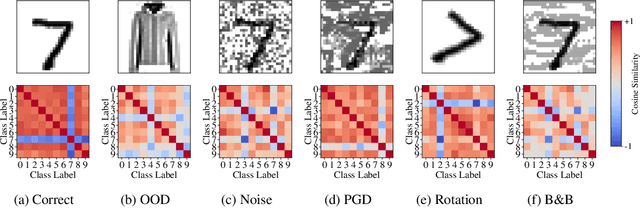
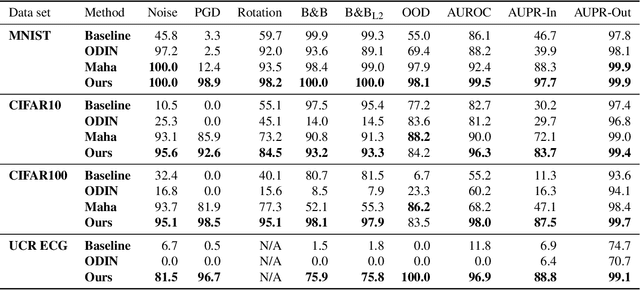
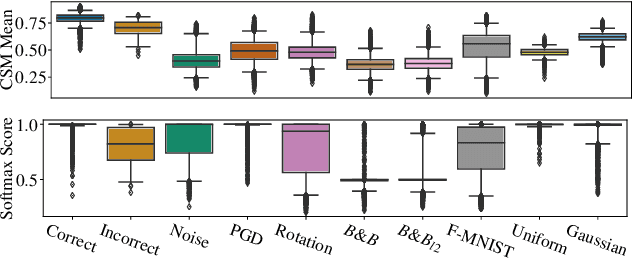
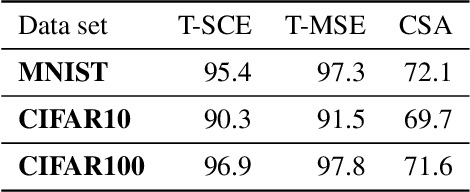
The susceptibility of deep neural networks to untrustworthy predictions, including out-of-distribution (OOD) data and adversarial examples, still prevent their widespread use in safety-critical applications. Most existing methods either require a re-training of a given model to achieve robust identification of adversarial attacks or are limited to out-of-distribution sample detection only. In this work, we propose a geometric gradient analysis (GGA) to improve the identification of untrustworthy predictions without retraining of a given model. GGA analyzes the geometry of the loss landscape of neural networks based on the saliency maps of their respective input. To motivate the proposed approach, we provide theoretical connections between gradients' geometrical properties and local minima of the loss function. Furthermore, we demonstrate that the proposed method outperforms prior approaches in detecting OOD data and adversarial attacks, including state-of-the-art and adaptive attacks.
Sampled Nonlocal Gradients for Stronger Adversarial Attacks
Nov 05, 2020

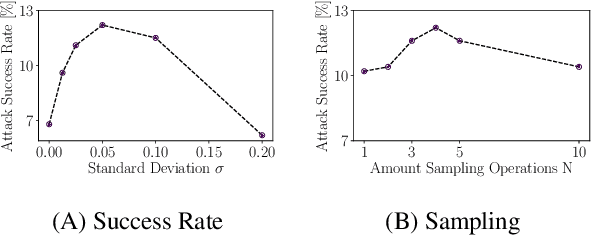

The vulnerability of deep neural networks to small and even imperceptible perturbations has become a central topic in deep learning research. The evaluation of new defense mechanisms for these so-called adversarial attacks has proven to be challenging. Although several sophisticated defense mechanisms were introduced, most of them were later shown to be ineffective. However, a reliable evaluation of model robustness is mandatory for deployment in safety-critical real-world scenarios. We propose a simple yet effective modification to the gradient calculation of state-of-the-art first-order adversarial attacks, which increases their success rate and thus leads to more accurate robustness estimates. Normally, the gradient update of an attack is directly calculated for the given data point. In general, this approach is sensitive to noise and small local optima of the loss function. Inspired by gradient sampling techniques from non-convex optimization, we propose to calculate the gradient direction of the adversarial attack as the weighted average over multiple points in the local vicinity. We empirically show that by incorporating this additional gradient information, we are able to give a more accurate estimation of the global descent direction on noisy and non-convex loss surfaces. Additionally, we show that the proposed method achieves higher success rates than a variety of state-of-the-art attacks on the benchmark datasets MNIST, Fashion-MNIST, and CIFAR10.
Towards Rapid and Robust Adversarial Training with One-Step Attacks
Mar 17, 2020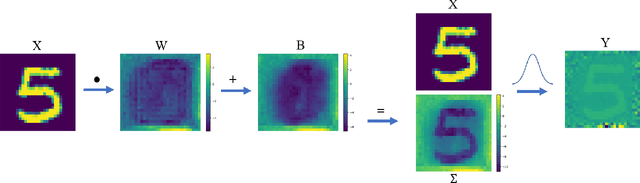
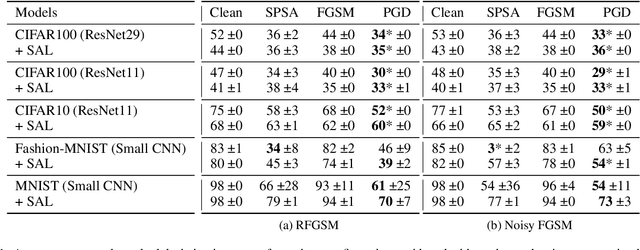
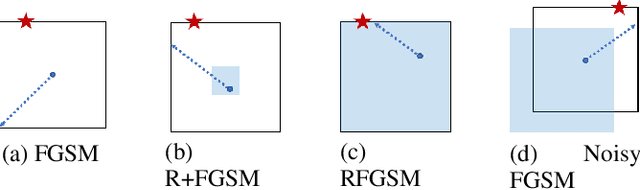
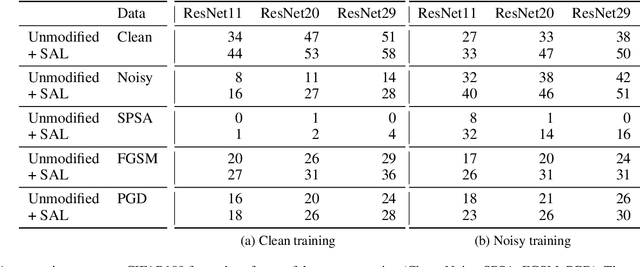
Adversarial training is the most successful empirical method for increasing the robustness of neural networks against adversarial attacks. However, the most effective approaches, like training with Projected Gradient Descent (PGD) are accompanied by high computational complexity. In this paper, we present two ideas that, in combination, enable adversarial training with the computationally less expensive Fast Gradient Sign Method (FGSM). First, we add uniform noise to the initial data point of the FGSM attack, which creates a wider variety of adversaries, thus prohibiting overfitting to one particular perturbation bound. Further, we add a learnable regularization step prior to the neural network, which we call Pixelwise Noise Injection Layer (PNIL). Inputs propagated trough the PNIL are resampled from a learned Gaussian distribution. The regularization induced by the PNIL prevents the model form learning to obfuscate its gradients, a factor that hindered prior approaches from successfully applying one-step methods for adversarial training. We show that noise injection in conjunction with FGSM-based adversarial training achieves comparable results to adversarial training with PGD while being considerably faster. Moreover, we outperform PGD-based adversarial training by combining noise injection and PNIL.