 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampled Nonlocal Gradients for Stronger Adversarial Attacks
Paper and Code
Nov 05, 2020

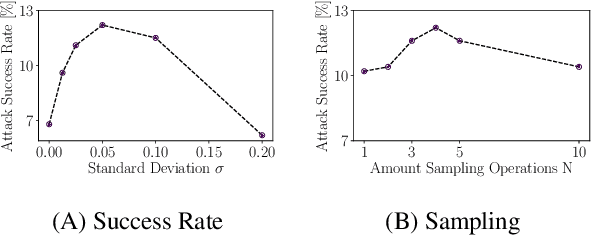

The vulnerability of deep neural networks to small and even imperceptible perturbations has become a central topic in deep learning research. The evaluation of new defense mechanisms for these so-called adversarial attacks has proven to be challenging. Although several sophisticated defense mechanisms were introduced, most of them were later shown to be ineffective. However, a reliable evaluation of model robustness is mandatory for deployment in safety-critical real-world scenarios. We propose a simple yet effective modification to the gradient calculation of state-of-the-art first-order adversarial attacks, which increases their success rate and thus leads to more accurate robustness estimates. Normally, the gradient update of an attack is directly calculated for the given data point. In general, this approach is sensitive to noise and small local optima of the loss function. Inspired by gradient sampling techniques from non-convex optimization, we propose to calculate the gradient direction of the adversarial attack as the weighted average over multiple points in the local vicinity. We empirically show that by incorporating this additional gradient information, we are able to give a more accurate estimation of the global descent direction on noisy and non-convex loss surfaces. Additionally, we show that the proposed method achieves higher success rates than a variety of state-of-the-art attacks on the benchmark datasets MNIST, Fashion-MNIST, and CIFAR10.