 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Human-Like Are Large Language Models? A Register-Aware Linguistic Evaluation Framework
May 26, 2026While factual correctness and task-performance have been in focus of Large Language Model (LLM) research for a long time, the fundamental question of how human-like generated texts are on a linguistic level has been underexplored. From a corpus-linguistic perspective, language production is inherently context-dependent, with distinct communicative contexts giving rise to differences in frequencies and co-occurrence patterns of linguistic features. A text failing to adhere to these patterns can be content-wise correct, but still be unfavorable to human readers. In this work, we propose a context-aware evaluation framework in which human-likeness is assessed using a two-sample problem between the linguistic feature distribution of a human reference corpus for a given register and a corresponding LLM-generated corpus. We implement this framework using the Maximum Mean Discrepancy (MMD) and the 67 lexico-grammatical features introduced by Biber, which are commonly applied in corpus linguistics. In our experiments, we compare seven instruction-tuned, open-source models across five English-language datasets spanning distinct registers against a human baseline. While across all tested setups, LLMs deviate from the human baseline, which models are closest to human language depends on the register and is not dictated by model size.
Understanding Cross-Model Perceptual Invariances Through Ensemble Metamers
Apr 02, 2025Understanding the perceptual invariances of artificial neural networks is essential for improving explainability and aligning models with human vision. Metamers - stimuli that are physically distinct yet produce identical neural activations - serve as a valuable tool for investigating these invariances. We introduce a novel approach to metamer generation by leveraging ensembles of artificial neural networks, capturing shared representational subspaces across diverse architectures, including convolutional neural networks and vision transformers. To characterize the properties of the generated metamers, we employ a suite of image-based metrics that assess factors such as semantic fidelity and naturalness. Our findings show that convolutional neural networks generate more recognizable and human-like metamers, while vision transformers produce realistic but less transferable metamers, highlighting the impact of architectural biases on representational invariances.
Robust and Efficient Writer-Independent IMU-Based Handwriting Recognization
Feb 28, 2025Online handwriting recognition (HWR) using data from inertial measurement units (IMUs) remains challenging due to variations in writing styles and the limited availability of high-quality annotated datasets. Traditional models often struggle to recognize handwriting from unseen writers, making writer-independent (WI) recognition a crucial but difficult problem. This paper presents an HWR model with an encoder-decoder structure for IMU data, featuring a CNN-based encoder for feature extraction and a BiLSTM decoder for sequence modeling, which supports inputs of varying lengths. Our approach demonstrates strong robustness and data efficiency, outperforming existing methods on WI datasets, including the WI split of the OnHW dataset and our own dataset. Extensive evaluations show that our model maintains high accuracy across different age groups and writing conditions while effectively learning from limited data. Through comprehensive ablation studies, we analyze key design choices, achieving a balance between accuracy and efficiency. These findings contribute to the development of more adaptable and scalable HWR systems for real-world applications.
Caption-Driven Explorations: Aligning Image and Text Embeddings through Human-Inspired Foveated Vision
Aug 19, 2024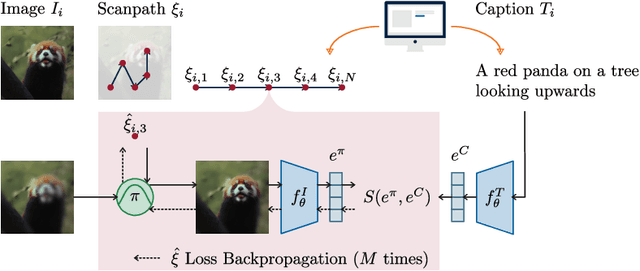

Understanding human attention is crucial for vision science and AI. While many models exist for free-viewing, less is known about task-driven image exploration. To address this, we introduce CapMIT1003, a dataset with captions and click-contingent image explorations, to study human attention during the captioning task. We also present NevaClip, a zero-shot method for predicting visual scanpaths by combining CLIP models with NeVA algorithms. NevaClip generates fixations to align the representations of foveated visual stimuli and captions. The simulated scanpaths outperform existing human attention models in plausibility for captioning and free-viewing tasks. This research enhances the understanding of human attention and advances scanpath prediction models.
Contrastive Language-Image Pretrained Models are Zero-Shot Human Scanpath Predictors
May 23, 2023
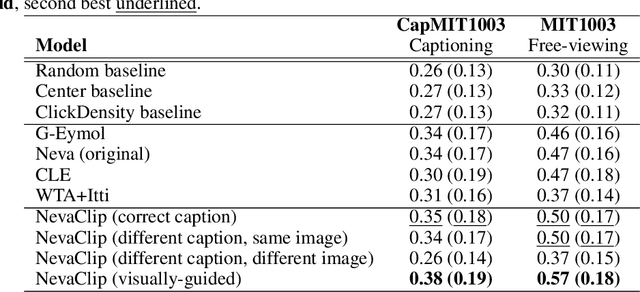

Understanding the mechanisms underlying human attention is a fundamental challenge for both vision science and artificial intelligence. While numerous computational models of free-viewing have been proposed, less is known about the mechanisms underlying task-driven image exploration. To address this gap, we present CapMIT1003, a database of captions and click-contingent image explorations collected during captioning tasks. CapMIT1003 is based on the same stimuli from the well-known MIT1003 benchmark, for which eye-tracking data under free-viewing conditions is available, which offers a promising opportunity to concurrently study human attention under both tasks. We make this dataset publicly available to facilitate future research in this field. In addition, we introduce NevaClip, a novel zero-shot method for predicting visual scanpaths that combines contrastive language-image pretrained (CLIP) models with biologically-inspired neural visual attention (NeVA) algorithms. NevaClip simulates human scanpaths by aligning the representation of the foveated visual stimulus and the representation of the associated caption, employing gradient-driven visual exploration to generate scanpaths. Our experimental results demonstrate that NevaClip outperforms existing unsupervised computational models of human visual attention in terms of scanpath plausibility, for both captioning and free-viewing tasks. Furthermore, we show that conditioning NevaClip with incorrect or misleading captions leads to random behavior, highlighting the significant impact of caption guidance in the decision-making process. These findings contribute to a better understanding of mechanisms that guide human attention and pave the way for more sophisticated computational approaches to scanpath prediction that can integrate direct top-down guidance of downstream tasks.
From Patches to Objects: Exploiting Spatial Reasoning for Better Visual Representations
May 21, 2023



As the field of deep learning steadily transitions from the realm of academic research to practical application, the significance of self-supervised pretraining methods has become increasingly prominent. These methods, particularly in the image domain, offer a compelling strategy to effectively utilize the abundance of unlabeled image data, thereby enhancing downstream tasks' performance. In this paper, we propose a novel auxiliary pretraining method that is based on spatial reasoning. Our proposed method takes advantage of a more flexible formulation of contrastive learning by introducing spatial reasoning as an auxiliary task for discriminative self-supervised methods. Spatial Reasoning works by having the network predict the relative distances between sampled non-overlapping patches. We argue that this forces the network to learn more detailed and intricate internal representations of the objects and the relationships between their constituting parts. Our experiments demonstrate substantial improvement in downstream performance in linear evaluation compared to similar work and provide directions for further research into spatial reasoning.
Simulating Human Gaze with Neural Visual Attention
Nov 22, 2022


Existing models of human visual attention are generally unable to incorporate direct task guidance and therefore cannot model an intent or goal when exploring a scene. To integrate guidance of any downstream visual task into attention modeling, we propose the Neural Visual Attention (NeVA) algorithm. To this end, we impose to neural networks the biological constraint of foveated vision and train an attention mechanism to generate visual explorations that maximize the performance with respect to the downstream task. We observe that biologically constrained neural networks generate human-like scanpaths without being trained for this objective. Extensive experiments on three common benchmark datasets show that our method outperforms state-of-the-art unsupervised human attention models in generating human-like scanpaths.
Active Learning of Ordinal Embeddings: A User Study on Football Data
Jul 26, 2022
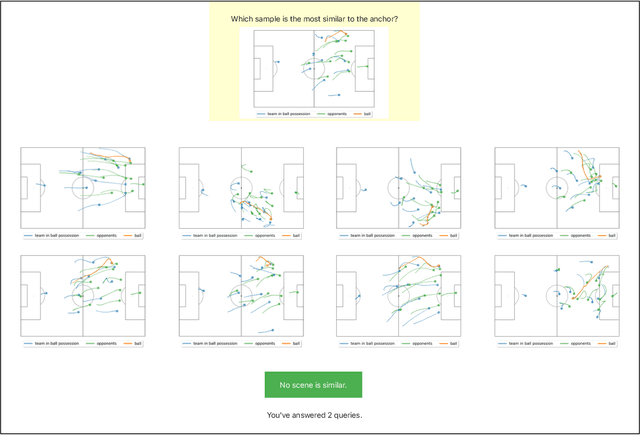
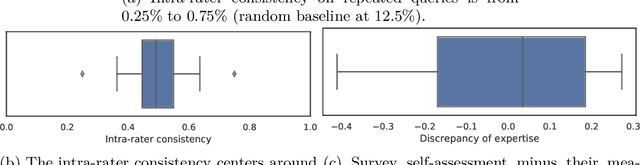
Humans innately measure distance between instances in an unlabeled dataset using an unknown similarity function. Distance metrics can only serve as proxy for similarity in information retrieval of similar instances. Learning a good similarity function from human annotations improves the quality of retrievals. This work uses deep metric learning to learn these user-defined similarity functions from few annotations for a large football trajectory dataset. We adapt an entropy-based active learning method with recent work from triplet mining to collect easy-to-answer but still informative annotations from human participants and use them to train a deep convolutional network that generalizes to unseen samples. Our user study shows that our approach improves the quality of the information retrieval compared to a previous deep metric learning approach that relies on a Siamese network. Specifically, we shed light on the strengths and weaknesses of passive sampling heuristics and active learners alike by analyzing the participants' response efficacy. To this end, we collect accuracy, algorithmic time complexity, the participants' fatigue and time-to-response, qualitative self-assessment and statements, as well as the effects of mixed-expertise annotators and their consistency on model performance and transfer-learning.
Don't Get Me Wrong: How to apply Deep Visual Interpretations to Time Series
Mar 14, 2022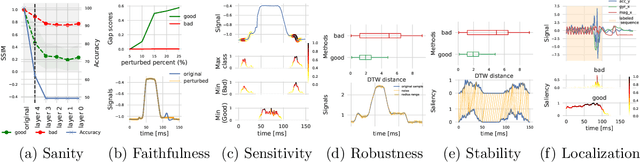
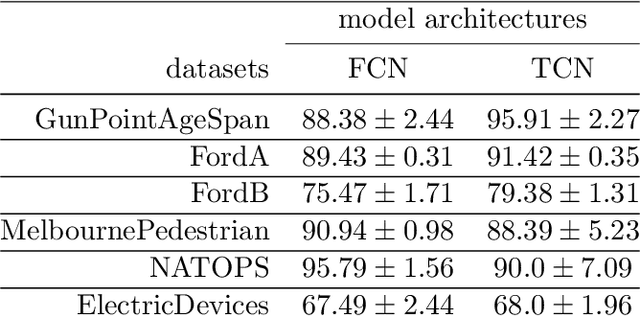
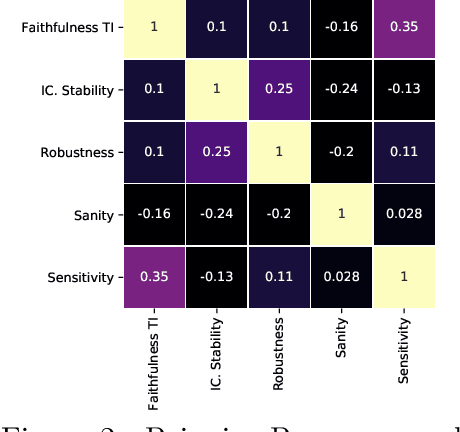
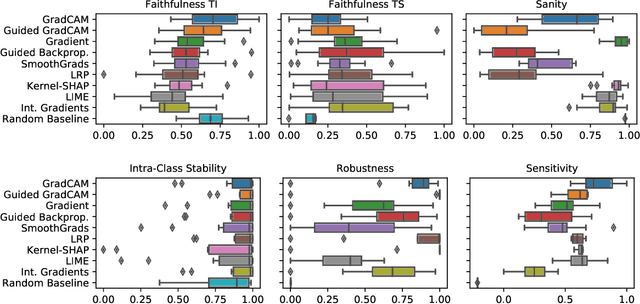
The correct interpretation and understanding of deep learning models is essential in many applications. Explanatory visual interpretation approaches for image and natural language processing allow domain experts to validate and understand almost any deep learning model. However, they fall short when generalizing to arbitrary time series data that is less intuitive and more diverse. Whether a visualization explains the true reasoning or captures the real features is difficult to judge. Hence, instead of blind trust we need an objective evaluation to obtain reliable quality metrics. We propose a framework of six orthogonal metrics for gradient- or perturbation-based post-hoc visual interpretation methods designed for time series classification and segmentation tasks. An experimental study includes popular neural network architectures for time series and nine visual interpretation methods. We evaluate the visual interpretation methods with diverse datasets from the UCR repository and a complex real-world dataset, and study the influence of common regularization techniques during training. We show that none of the methods consistently outperforms any of the others on all metrics while some are ahead at times. Our insights and recommendations allow experts to make informed choices of suitable visualization techniques for the model and task at hand.
Digitizing Handwriting with a Sensor Pen: A Writer-Independent Recognizer
Jul 08, 2021
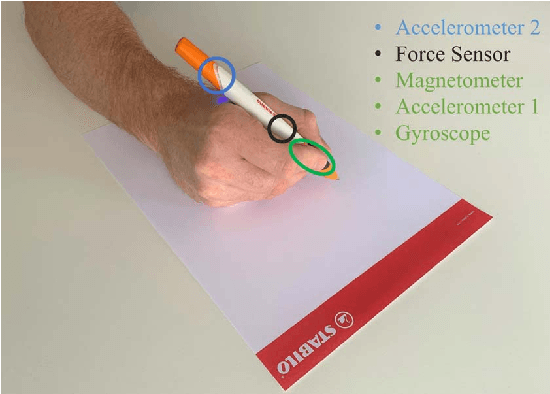

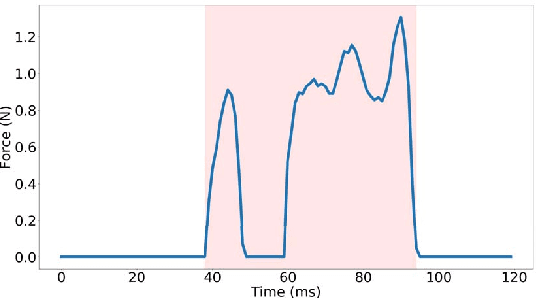
Online handwriting recognition has been studied for a long time with only few practicable results when writing on normal paper. Previous approaches using sensor-based devices encountered problems that limited the usage of the developed systems in real-world applications. This paper presents a writer-independent system that recognizes characters written on plain paper with the use of a sensor-equipped pen. This system is applicable in real-world applications and requires no user-specific training for recognition. The pen provides linear acceleration, angular velocity, magnetic field, and force applied by the user, and acts as a digitizer that transforms the analogue signals of the sensors into timeseries data while writing on regular paper. The dataset we collected with this pen consists of Latin lower-case and upper-case alphabets. We present the results of a convolutional neural network model for letter classification and show that this approach is practical and achieves promising results for writer-independent character recognition. This work aims at providing a realtime handwriting recognition system to be used for writing on normal paper.