 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Cross-Model Perceptual Invariances Through Ensemble Metamers
Apr 02, 2025Understanding the perceptual invariances of artificial neural networks is essential for improving explainability and aligning models with human vision. Metamers - stimuli that are physically distinct yet produce identical neural activations - serve as a valuable tool for investigating these invariances. We introduce a novel approach to metamer generation by leveraging ensembles of artificial neural networks, capturing shared representational subspaces across diverse architectures, including convolutional neural networks and vision transformers. To characterize the properties of the generated metamers, we employ a suite of image-based metrics that assess factors such as semantic fidelity and naturalness. Our findings show that convolutional neural networks generate more recognizable and human-like metamers, while vision transformers produce realistic but less transferable metamers, highlighting the impact of architectural biases on representational invariances.
Predicting potentially unfair clauses in Chilean terms of services with natural language processing
Feb 02, 2025This study addresses the growing concern of information asymmetry in consumer contracts, exacerbated by the proliferation of online services with complex Terms of Service that are rarely even read. Even though research on automatic analysis methods is conducted, the problem is aggravated by the general focus on English-language Machine Learning approaches and on major jurisdictions, such as the European Union. We introduce a new methodology and a substantial dataset addressing this gap. We propose a novel annotation scheme with four categories and a total of 20 classes, and apply it on 50 online Terms of Service used in Chile. Our evaluation of transformer-based models highlights how factors like language- and/or domain-specific pre-training, few-shot sample size, and model architecture affect the detection and classification of potentially abusive clauses. Results show a large variability in performance for the different tasks and models, with the highest macro-F1 scores for the detection task ranging from 79% to 89% and micro-F1 scores up to 96%, while macro-F1 scores for the classification task range from 60% to 70% and micro-F1 scores from 64% to 80%. Notably, this is the first Spanish-language multi-label classification dataset for legal clauses, applying Chilean law and offering a comprehensive evaluation of Spanish-language models in the legal domain. Our work lays the ground for future research in method development for rarely considered legal analysis and potentially leads to practical applications to support consumers in Chile and Latin America as a whole.
Active Learning of Ordinal Embeddings: A User Study on Football Data
Jul 26, 2022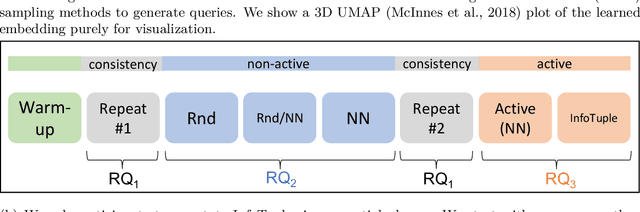
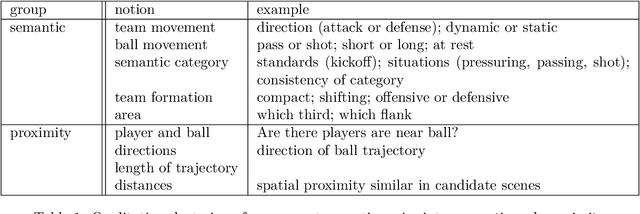
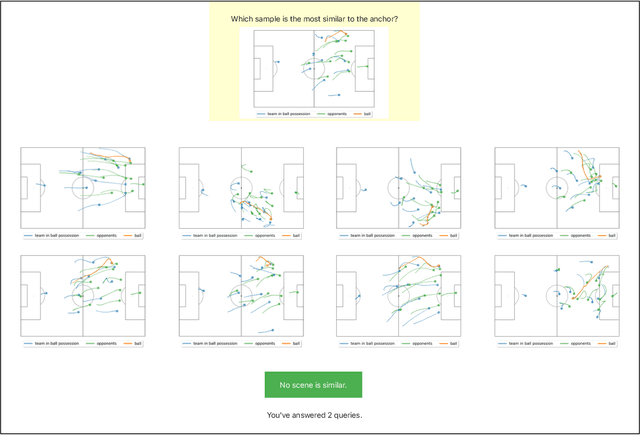
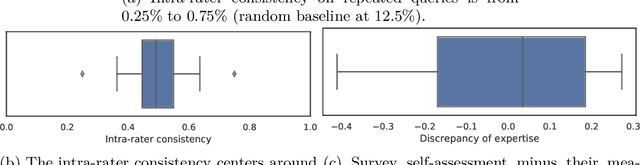
Humans innately measure distance between instances in an unlabeled dataset using an unknown similarity function. Distance metrics can only serve as proxy for similarity in information retrieval of similar instances. Learning a good similarity function from human annotations improves the quality of retrievals. This work uses deep metric learning to learn these user-defined similarity functions from few annotations for a large football trajectory dataset. We adapt an entropy-based active learning method with recent work from triplet mining to collect easy-to-answer but still informative annotations from human participants and use them to train a deep convolutional network that generalizes to unseen samples. Our user study shows that our approach improves the quality of the information retrieval compared to a previous deep metric learning approach that relies on a Siamese network. Specifically, we shed light on the strengths and weaknesses of passive sampling heuristics and active learners alike by analyzing the participants' response efficacy. To this end, we collect accuracy, algorithmic time complexity, the participants' fatigue and time-to-response, qualitative self-assessment and statements, as well as the effects of mixed-expertise annotators and their consistency on model performance and transfer-learning.
Don't Get Me Wrong: How to apply Deep Visual Interpretations to Time Series
Mar 14, 2022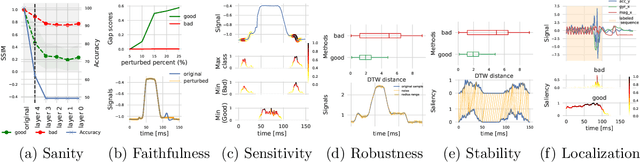
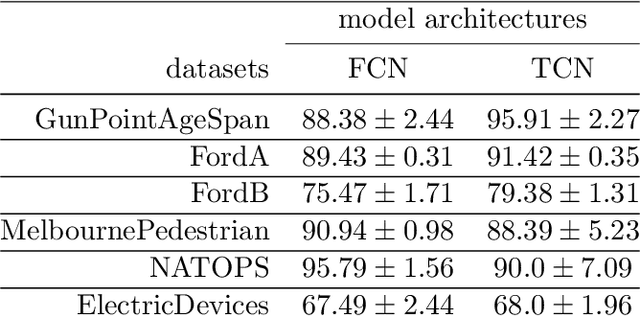
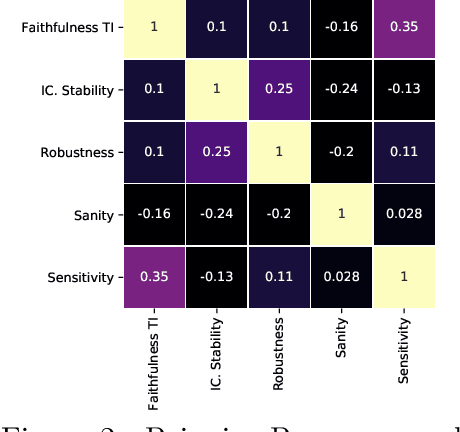
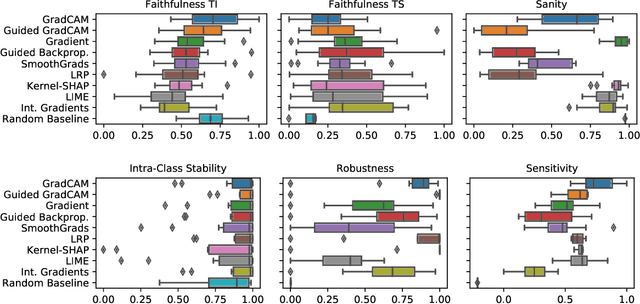
The correct interpretation and understanding of deep learning models is essential in many applications. Explanatory visual interpretation approaches for image and natural language processing allow domain experts to validate and understand almost any deep learning model. However, they fall short when generalizing to arbitrary time series data that is less intuitive and more diverse. Whether a visualization explains the true reasoning or captures the real features is difficult to judge. Hence, instead of blind trust we need an objective evaluation to obtain reliable quality metrics. We propose a framework of six orthogonal metrics for gradient- or perturbation-based post-hoc visual interpretation methods designed for time series classification and segmentation tasks. An experimental study includes popular neural network architectures for time series and nine visual interpretation methods. We evaluate the visual interpretation methods with diverse datasets from the UCR repository and a complex real-world dataset, and study the influence of common regularization techniques during training. We show that none of the methods consistently outperforms any of the others on all metrics while some are ahead at times. Our insights and recommendations allow experts to make informed choices of suitable visualization techniques for the model and task at hand.