 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Training and Evaluation Resources for Vision-Language Models
Apr 20, 2026Vision Language Models (VLMs) achieved rapid progress in the recent years. However, despite their growth, VLMs development is heavily grounded on English, leading to two main limitations: (i) the lack of multilingual and multimodal datasets for training, and (ii) the scarcity of comprehensive evaluation benchmarks across languages. In this work, we address these gaps by introducing a new comprehensive suite of resources for VLMs training and evaluation spanning five European languages (English, French, German, Italian, and Spanish). We adopt a regeneration-translation paradigm that produces high-quality cross-lingual resources by combining curated synthetic generation and manual annotation. Specifically, we build Multi-PixMo, a training corpus obtained regenerating examples from Pixmo pre-existing datasets with permissively licensed models: PixMo-Cap, PixMo-AskModelAnything, and CoSyn-400k. On the evaluation side, we construct a set of multilingual benchmarks derived translating widely used English datasets (MMbench, ScienceQA, MME, POPE, AI2D). We assess the quality of these resources through qualitative and quantitative human analyses, measuring inter-annotator agreement. Additionally, we perform ablation studies to demonstrate the impact of multilingual data, with respect to English only, in VLMs training. Experiments, comprising 3 different models show that using multilingual, multimodal examples for training VLMs aids is consistently beneficial on non-English benchmarks, with positive transfer to English as well.
Protoknowledge Shapes Behaviour of LLMs in Downstream Tasks: Memorization and Generalization with Knowledge Graphs
May 21, 2025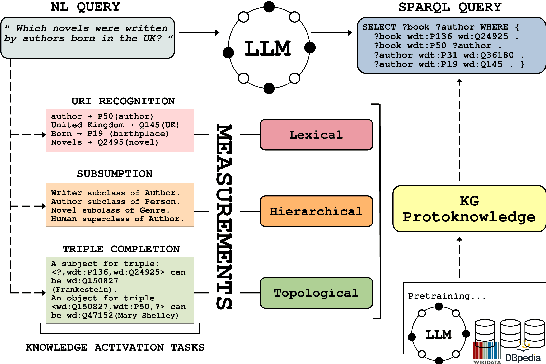



We introduce the concept of protoknowledge to formalize and measure how sequences of tokens encoding Knowledge Graphs are internalized during pretraining and utilized at inference time by Large Language Models (LLMs). Indeed, LLMs have demonstrated the ability to memorize vast amounts of token sequences during pretraining, and a central open question is how they leverage this memorization as reusable knowledge through generalization. We then categorize protoknowledge into lexical, hierarchical, and topological forms, varying on the type of knowledge that needs to be activated. We measure protoknowledge through Knowledge Activation Tasks (KATs), analyzing its general properties such as semantic bias. We then investigate the impact of protoknowledge on Text-to-SPARQL performance by varying prompting strategies depending on input conditions. To this end, we adopt a novel analysis framework that assesses whether model predictions align with the successful activation of the relevant protoknowledge for each query. This methodology provides a practical tool to explore Semantic-Level Data Contamination and serves as an effective strategy for Closed-Pretraining models.
MSTS: A Multimodal Safety Test Suite for Vision-Language Models
Jan 17, 2025Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.
SLIMER-IT: Zero-Shot NER on Italian Language
Sep 24, 2024
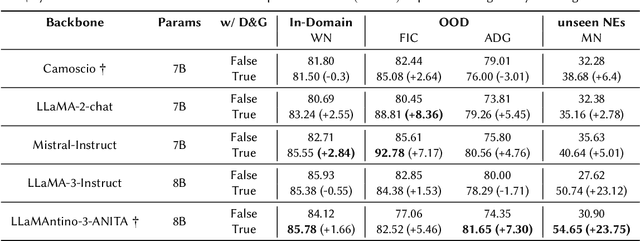
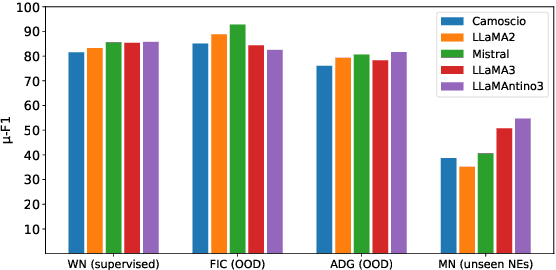
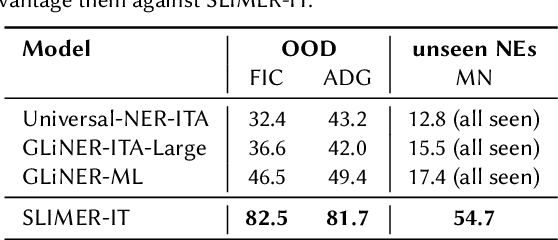
Traditional approaches to Named Entity Recognition (NER) frame the task into a BIO sequence labeling problem. Although these systems often excel in the downstream task at hand, they require extensive annotated data and struggle to generalize to out-of-distribution input domains and unseen entity types. On the contrary, Large Language Models (LLMs) have demonstrated strong zero-shot capabilities. While several works address Zero-Shot NER in English, little has been done in other languages. In this paper, we define an evaluation framework for Zero-Shot NER, applying it to the Italian language. Furthermore, we introduce SLIMER-IT, the Italian version of SLIMER, an instruction-tuning approach for zero-shot NER leveraging prompts enriched with definition and guidelines. Comparisons with other state-of-the-art models, demonstrate the superiority of SLIMER-IT on never-seen-before entity tags.
Caption-Driven Explorations: Aligning Image and Text Embeddings through Human-Inspired Foveated Vision
Aug 19, 2024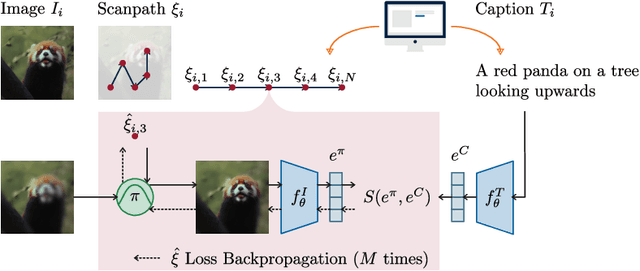

Understanding human attention is crucial for vision science and AI. While many models exist for free-viewing, less is known about task-driven image exploration. To address this, we introduce CapMIT1003, a dataset with captions and click-contingent image explorations, to study human attention during the captioning task. We also present NevaClip, a zero-shot method for predicting visual scanpaths by combining CLIP models with NeVA algorithms. NevaClip generates fixations to align the representations of foveated visual stimuli and captions. The simulated scanpaths outperform existing human attention models in plausibility for captioning and free-viewing tasks. This research enhances the understanding of human attention and advances scanpath prediction models.
Show Less, Instruct More: Enriching Prompts with Definitions and Guidelines for Zero-Shot NER
Jul 02, 2024Recently, several specialized instruction-tuned Large Language Models (LLMs) for Named Entity Recognition (NER) have emerged. Compared to traditional NER approaches, these models have strong generalization capabilities. Existing LLMs mainly focus on zero-shot NER in out-of-domain distributions, being fine-tuned on an extensive number of entity classes that often highly or completely overlap with test sets. In this work instead, we propose SLIMER, an approach designed to tackle never-seen-before named entity tags by instructing the model on fewer examples, and by leveraging a prompt enriched with definition and guidelines. Experiments demonstrate that definition and guidelines yield better performance, faster and more robust learning, particularly when labelling unseen Named Entities. Furthermore, SLIMER performs comparably to state-of-the-art approaches in out-of-domain zero-shot NER, while being trained on a reduced tag set.
Dynamic Few-Shot Learning for Knowledge Graph Question Answering
Jul 01, 2024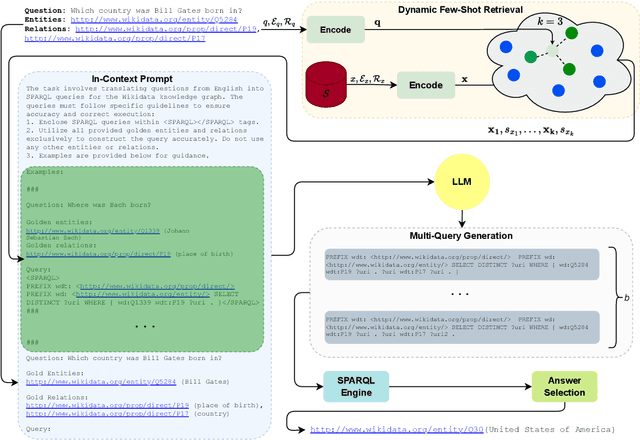


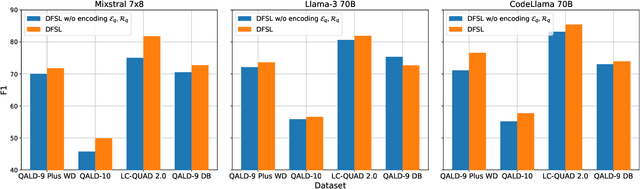
Large language models present opportunities for innovative Question Answering over Knowledge Graphs (KGQA). However, they are not inherently designed for query generation. To bridge this gap, solutions have been proposed that rely on fine-tuning or ad-hoc architectures, achieving good results but limited out-of-domain distribution generalization. In this study, we introduce a novel approach called Dynamic Few-Shot Learning (DFSL). DFSL integrates the efficiency of in-context learning and semantic similarity and provides a generally applicable solution for KGQA with state-of-the-art performance. We run an extensive evaluation across multiple benchmark datasets and architecture configurations.
Clue-Instruct: Text-Based Clue Generation for Educational Crossword Puzzles
Apr 09, 2024Crossword puzzles are popular linguistic games often used as tools to engage students in learning. Educational crosswords are characterized by less cryptic and more factual clues that distinguish them from traditional crossword puzzles. Despite there exist several publicly available clue-answer pair databases for traditional crosswords, educational clue-answer pairs datasets are missing. In this article, we propose a methodology to build educational clue generation datasets that can be used to instruct Large Language Models (LLMs). By gathering from Wikipedia pages informative content associated with relevant keywords, we use Large Language Models to automatically generate pedagogical clues related to the given input keyword and its context. With such an approach, we created clue-instruct, a dataset containing 44,075 unique examples with text-keyword pairs associated with three distinct crossword clues. We used clue-instruct to instruct different LLMs to generate educational clues from a given input content and keyword. Both human and automatic evaluations confirmed the quality of the generated clues, thus validating the effectiveness of our approach.
Are Compressed Language Models Less Subgroup Robust?
Mar 26, 2024
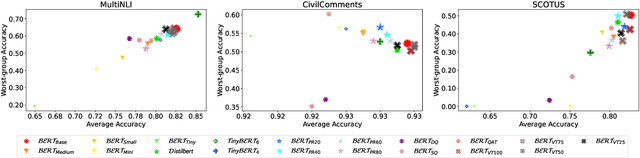
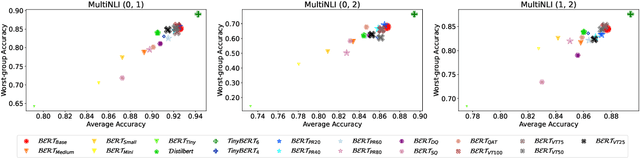

To reduce the inference cost of large language models, model compression is increasingly used to create smaller scalable models. However, little is known about their robustness to minority subgroups defined by the labels and attributes of a dataset. In this paper, we investigate the effects of 18 different compression methods and settings on the subgroup robustness of BERT language models. We show that worst-group performance does not depend on model size alone, but also on the compression method used. Additionally, we find that model compression does not always worsen the performance on minority subgroups. Altogether, our analysis serves to further research into the subgroup robustness of model compression.
* The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023)
Neural paraphrasing by automatically crawled and aligned sentence pairs
Feb 16, 2024

Paraphrasing is the task of re-writing an input text using other words, without altering the meaning of the original content. Conversational systems can exploit automatic paraphrasing to make the conversation more natural, e.g., talking about a certain topic using different paraphrases in different time instants. Recently, the task of automatically generating paraphrases has been approached in the context of Natural Language Generation (NLG). While many existing systems simply consist in rule-based models, the recent success of the Deep Neural Networks in several NLG tasks naturally suggests the possibility of exploiting such networks for generating paraphrases. However, the main obstacle toward neural-network-based paraphrasing is the lack of large datasets with aligned pairs of sentences and paraphrases, that are needed to efficiently train the neural models. In this paper we present a method for the automatic generation of large aligned corpora, that is based on the assumption that news and blog websites talk about the same events using different narrative styles. We propose a similarity search procedure with linguistic constraints that, given a reference sentence, is able to locate the most similar candidate paraphrases out from millions of indexed sentences. The data generation process is evaluated in the case of the Italian language, performing experiments using pointer-based deep neural architectures.
* The 6th International Conference on Social Networks Analysis, Management and Security (SNAMS 2019)