 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable Diagnostic Framework for Neurodegenerative Dementias via Reinforcement-Optimized LLM Reasoning
May 26, 2025The differential diagnosis of neurodegenerative dementias is a challenging clinical task, mainly because of the overlap in symptom presentation and the similarity of patterns observed in structural neuroimaging. To improve diagnostic efficiency and accuracy, deep learning-based methods such as Convolutional Neural Networks and Vision Transformers have been proposed for the automatic classification of brain MRIs. However, despite their strong predictive performance, these models find limited clinical utility due to their opaque decision making. In this work, we propose a framework that integrates two core components to enhance diagnostic transparency. First, we introduce a modular pipeline for converting 3D T1-weighted brain MRIs into textual radiology reports. Second, we explore the potential of modern Large Language Models (LLMs) to assist clinicians in the differential diagnosis between Frontotemporal dementia subtypes, Alzheimer's disease, and normal aging based on the generated reports. To bridge the gap between predictive accuracy and explainability, we employ reinforcement learning to incentivize diagnostic reasoning in LLMs. Without requiring supervised reasoning traces or distillation from larger models, our approach enables the emergence of structured diagnostic rationales grounded in neuroimaging findings. Unlike post-hoc explainability methods that retrospectively justify model decisions, our framework generates diagnostic rationales as part of the inference process-producing causally grounded explanations that inform and guide the model's decision-making process. In doing so, our framework matches the diagnostic performance of existing deep learning methods while offering rationales that support its diagnostic conclusions.
SLIMER-IT: Zero-Shot NER on Italian Language
Sep 24, 2024
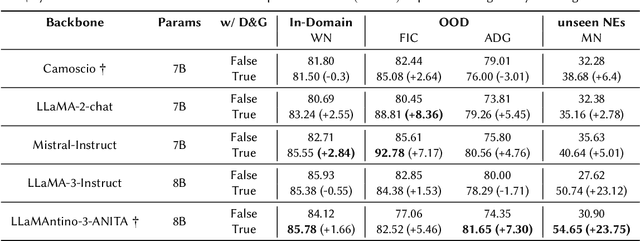
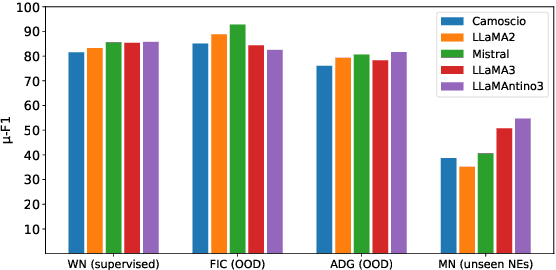
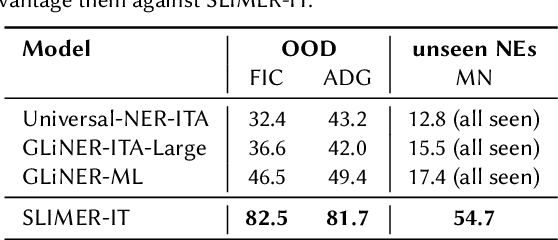
Traditional approaches to Named Entity Recognition (NER) frame the task into a BIO sequence labeling problem. Although these systems often excel in the downstream task at hand, they require extensive annotated data and struggle to generalize to out-of-distribution input domains and unseen entity types. On the contrary, Large Language Models (LLMs) have demonstrated strong zero-shot capabilities. While several works address Zero-Shot NER in English, little has been done in other languages. In this paper, we define an evaluation framework for Zero-Shot NER, applying it to the Italian language. Furthermore, we introduce SLIMER-IT, the Italian version of SLIMER, an instruction-tuning approach for zero-shot NER leveraging prompts enriched with definition and guidelines. Comparisons with other state-of-the-art models, demonstrate the superiority of SLIMER-IT on never-seen-before entity tags.
Show Less, Instruct More: Enriching Prompts with Definitions and Guidelines for Zero-Shot NER
Jul 02, 2024Recently, several specialized instruction-tuned Large Language Models (LLMs) for Named Entity Recognition (NER) have emerged. Compared to traditional NER approaches, these models have strong generalization capabilities. Existing LLMs mainly focus on zero-shot NER in out-of-domain distributions, being fine-tuned on an extensive number of entity classes that often highly or completely overlap with test sets. In this work instead, we propose SLIMER, an approach designed to tackle never-seen-before named entity tags by instructing the model on fewer examples, and by leveraging a prompt enriched with definition and guidelines. Experiments demonstrate that definition and guidelines yield better performance, faster and more robust learning, particularly when labelling unseen Named Entities. Furthermore, SLIMER performs comparably to state-of-the-art approaches in out-of-domain zero-shot NER, while being trained on a reduced tag set.
BUSTER: a "BUSiness Transaction Entity Recognition" dataset
Feb 15, 2024Albeit Natural Language Processing has seen major breakthroughs in the last few years, transferring such advances into real-world business cases can be challenging. One of the reasons resides in the displacement between popular benchmarks and actual data. Lack of supervision, unbalanced classes, noisy data and long documents often affect real problems in vertical domains such as finance, law and health. To support industry-oriented research, we present BUSTER, a BUSiness Transaction Entity Recognition dataset. The dataset consists of 3779 manually annotated documents on financial transactions. We establish several baselines exploiting both general-purpose and domain-specific language models. The best performing model is also used to automatically annotate 6196 documents, which we release as an additional silver corpus to BUSTER.