 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow Less, Instruct More: Enriching Prompts with Definitions and Guidelines for Zero-Shot NER
Jul 02, 2024Recently, several specialized instruction-tuned Large Language Models (LLMs) for Named Entity Recognition (NER) have emerged. Compared to traditional NER approaches, these models have strong generalization capabilities. Existing LLMs mainly focus on zero-shot NER in out-of-domain distributions, being fine-tuned on an extensive number of entity classes that often highly or completely overlap with test sets. In this work instead, we propose SLIMER, an approach designed to tackle never-seen-before named entity tags by instructing the model on fewer examples, and by leveraging a prompt enriched with definition and guidelines. Experiments demonstrate that definition and guidelines yield better performance, faster and more robust learning, particularly when labelling unseen Named Entities. Furthermore, SLIMER performs comparably to state-of-the-art approaches in out-of-domain zero-shot NER, while being trained on a reduced tag set.
BUSTER: a "BUSiness Transaction Entity Recognition" dataset
Feb 15, 2024Albeit Natural Language Processing has seen major breakthroughs in the last few years, transferring such advances into real-world business cases can be challenging. One of the reasons resides in the displacement between popular benchmarks and actual data. Lack of supervision, unbalanced classes, noisy data and long documents often affect real problems in vertical domains such as finance, law and health. To support industry-oriented research, we present BUSTER, a BUSiness Transaction Entity Recognition dataset. The dataset consists of 3779 manually annotated documents on financial transactions. We establish several baselines exploiting both general-purpose and domain-specific language models. The best performing model is also used to automatically annotate 6196 documents, which we release as an additional silver corpus to BUSTER.
Multi-Word Tokenization for Sequence Compression
Feb 15, 2024
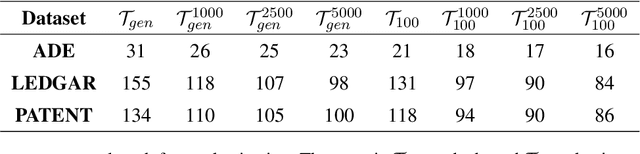
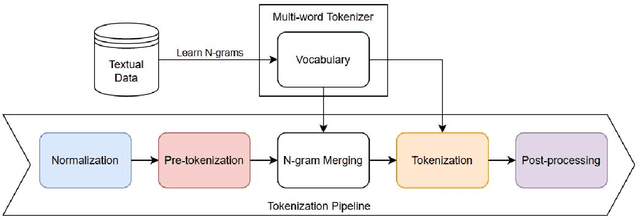
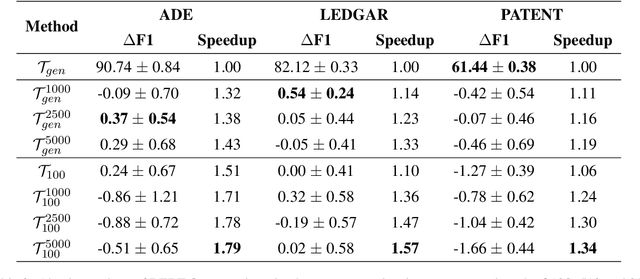
Large Language Models have proven highly successful at modelling a variety of tasks. However, this comes at a steep computational cost that hinders wider industrial uptake. In this pa005 per, we present MWT: a Multi-Word Tokenizer that goes beyond word boundaries by representing frequent multi-word expressions as single tokens. MWTs produce a more compact and efficient tokenization that yields two benefits: (1) Increase in performance due to a greater coverage of input data given a fixed sequence length and budget; (2) Faster and lighter inference due to the ability to reduce the sequence length with negligible drops in performance. Our results show that MWT is more robust across shorter sequence lengths, thus allowing for major speedups via early sequence truncation.
* The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023)
The WebCrow French Crossword Solver
Nov 27, 2023Crossword puzzles are one of the most popular word games, played in different languages all across the world, where riddle style can vary significantly from one country to another. Automated crossword resolution is challenging, and typical solvers rely on large databases of previously solved crosswords. In this work, we extend WebCrow 2.0, an automatic crossword solver, to French, making it the first program for crossword solving in the French language. To cope with the lack of a large repository of clue-answer crossword data, WebCrow 2.0 exploits multiple modules, called experts, that retrieve candidate answers from heterogeneous resources, such as the web, knowledge graphs, and linguistic rules. We compared WebCrow's performance against humans in two different challenges. Despite the limited amount of past crosswords, French WebCrow was competitive, actually outperforming humans in terms of speed and accuracy, thus proving its capabilities to generalize to new languages.
An energy-based comparative analysis of common approaches to text classification in the Legal domain
Nov 02, 2023



Most Machine Learning research evaluates the best solutions in terms of performance. However, in the race for the best performing model, many important aspects are often overlooked when, on the contrary, they should be carefully considered. In fact, sometimes the gaps in performance between different approaches are neglectable, whereas factors such as production costs, energy consumption, and carbon footprint must take into consideration. Large Language Models (LLMs) are extensively adopted to address NLP problems in academia and industry. In this work, we present a detailed quantitative comparison of LLM and traditional approaches (e.g. SVM) on the LexGLUE benchmark, which takes into account both performance (standard indices) and alternative metrics such as timing, power consumption and cost, in a word: the carbon-footprint. In our analysis, we considered the prototyping phase (model selection by training-validation-test iterations) and in-production phases separately, since they follow different implementation procedures and also require different resources. The results indicate that very often, the simplest algorithms achieve performance very close to that of large LLMs but with very low power consumption and lower resource demands. The results obtained could suggest companies to include additional evaluations in the choice of Machine Learning (ML) solutions.