 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Arabic Text to Puzzles: LLM-Driven Development of Arabic Educational Crosswords
Jan 19, 2025We present an Arabic crossword puzzle generator from a given text that utilizes advanced language models such as GPT-4-Turbo, GPT-3.5-Turbo and Llama3-8B-Instruct, specifically developed for educational purposes, this innovative generator leverages a meticulously compiled dataset named Arabic-Clue-Instruct with over 50,000 entries encompassing text, answers, clues, and categories. This dataset is intricately designed to aid in the generation of pertinent clues linked to specific texts and keywords within defined categories. This project addresses the scarcity of advanced educational tools tailored for the Arabic language, promoting enhanced language learning and cognitive development. By providing a culturally and linguistically relevant tool, our objective is to make learning more engaging and effective through gamification and interactivity. Integrating state-of-the-art artificial intelligence with contemporary learning methodologies, this tool can generate crossword puzzles from any given educational text, thereby facilitating an interactive and enjoyable learning experience. This tool not only advances educational paradigms but also sets a new standard in interactive and cognitive learning technologies. The model and dataset are publicly available.
Advancing Student Writing Through Automated Syntax Feedback
Jan 13, 2025
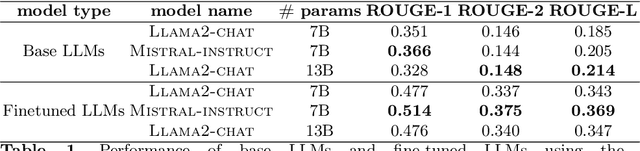

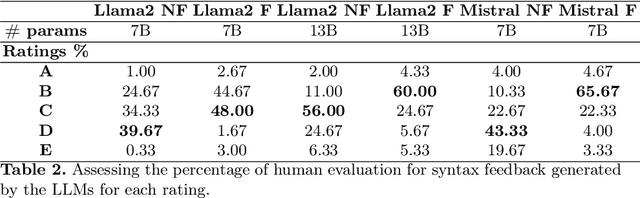
This study underscores the pivotal role of syntax feedback in augmenting the syntactic proficiency of students. Recognizing the challenges faced by learners in mastering syntactic nuances, we introduce a specialized dataset named Essay-Syntax-Instruct designed to enhance the understanding and application of English syntax among these students. Leveraging the capabilities of Large Language Models (LLMs) such as GPT3.5-Turbo, Llama-2-7b-chat-hf, Llama-2-13b-chat-hf, and Mistral-7B-Instruct-v0.2, this work embarks on a comprehensive fine-tuning process tailored to the syntax improvement task. Through meticulous evaluation, we demonstrate that the fine-tuned LLMs exhibit a marked improvement in addressing syntax-related challenges, thereby serving as a potent tool for students to identify and rectify their syntactic errors. The findings not only highlight the effectiveness of the proposed dataset in elevating the performance of LLMs for syntax enhancement but also illuminate a promising path for utilizing advanced language models to support language acquisition efforts. This research contributes to the broader field of language learning technology by showcasing the potential of LLMs in facilitating the linguistic development of Students.
Harnessing LLMs for Educational Content-Driven Italian Crossword Generation
Nov 25, 2024In this work, we unveil a novel tool for generating Italian crossword puzzles from text, utilizing advanced language models such as GPT-4o, Mistral-7B-Instruct-v0.3, and Llama3-8b-Instruct. Crafted specifically for educational applications, this cutting-edge generator makes use of the comprehensive Italian-Clue-Instruct dataset, which comprises over 30,000 entries including diverse text, solutions, and types of clues. This carefully assembled dataset is designed to facilitate the creation of contextually relevant clues in various styles associated with specific texts and keywords. The study delves into four distinctive styles of crossword clues: those without format constraints, those formed as definite determiner phrases, copular sentences, and bare noun phrases. Each style introduces unique linguistic structures to diversify clue presentation. Given the lack of sophisticated educational tools tailored to the Italian language, this project seeks to enhance learning experiences and cognitive development through an engaging, interactive platform. By meshing state-of-the-art AI with contemporary educational strategies, our tool can dynamically generate crossword puzzles from Italian educational materials, thereby providing an enjoyable and interactive learning environment. This technological advancement not only redefines educational paradigms but also sets a new benchmark for interactive and cognitive language learning solutions.
Design Proteins Using Large Language Models: Enhancements and Comparative Analyses
Aug 12, 2024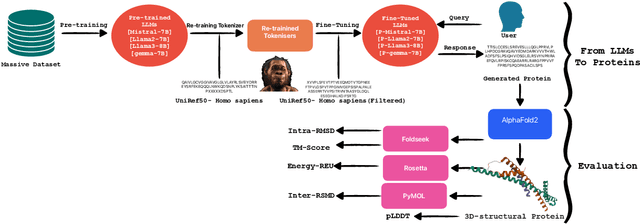
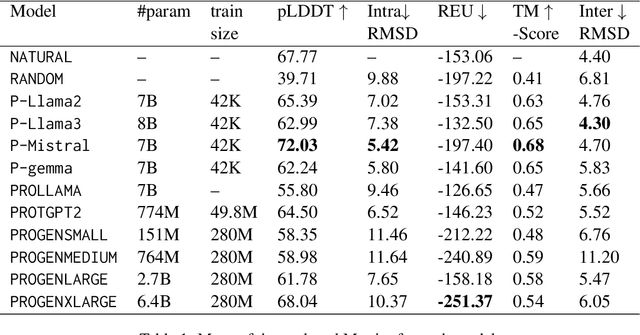
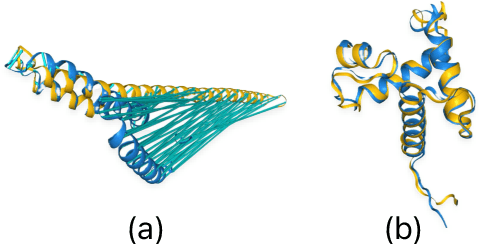
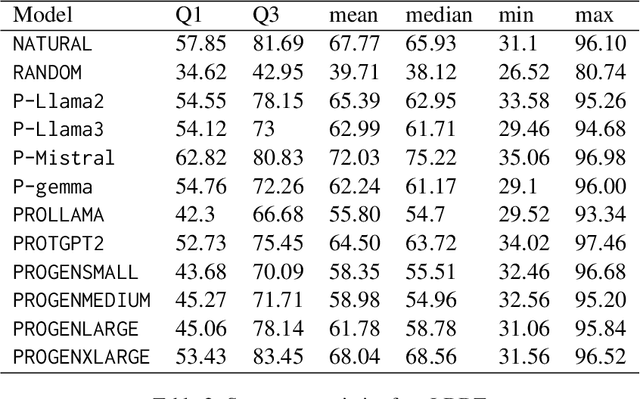
Pre-trained LLMs have demonstrated substantial capabilities across a range of conventional natural language processing (NLP) tasks, such as summarization and entity recognition. In this paper, we explore the application of LLMs in the generation of high-quality protein sequences. Specifically, we adopt a suite of pre-trained LLMs, including Mistral-7B1, Llama-2-7B2, Llama-3-8B3, and gemma-7B4, to produce valid protein sequences. All of these models are publicly available.5 Unlike previous work in this field, our approach utilizes a relatively small dataset comprising 42,000 distinct human protein sequences. We retrain these models to process protein-related data, ensuring the generation of biologically feasible protein structures. Our findings demonstrate that even with limited data, the adapted models exhibit efficiency comparable to established protein-focused models such as ProGen varieties, ProtGPT2, and ProLLaMA, which were trained on millions of protein sequences. To validate and quantify the performance of our models, we conduct comparative analyses employing standard metrics such as pLDDT, RMSD, TM-score, and REU. Furthermore, we commit to making the trained versions of all four models publicly available, fostering greater transparency and collaboration in the field of computational biology.
Automating Turkish Educational Quiz Generation Using Large Language Models
Jun 05, 2024Crafting quizzes from educational content is a pivotal activity that benefits both teachers and students by reinforcing learning and evaluating understanding. In this study, we introduce a novel approach to generate quizzes from Turkish educational texts, marking a pioneering endeavor in educational technology specifically tailored to the Turkish educational context. We present a specialized dataset, named the Turkish-Quiz-Instruct, comprising an extensive collection of Turkish educational texts accompanied by multiple-choice and short-answer quizzes. This research leverages the capabilities of Large Language Models (LLMs), including GPT-4-Turbo, GPT-3.5-Turbo, Llama-2-7b-chat-hf, and Llama-2-13b-chat-hf, to automatically generate quiz questions and answers from the Turkish educational content. Our work delineates the methodology for employing these LLMs in the context of Turkish educational material, thereby opening new avenues for automated Turkish quiz generation. The study not only demonstrates the efficacy of using such models for generating coherent and relevant quiz content but also sets a precedent for future research in the domain of automated educational content creation for languages other than English. The Turkish-Quiz-Instruct dataset is introduced as a valuable resource for researchers and practitioners aiming to explore the boundaries of educational technology and language-specific applications of LLMs in Turkish. By addressing the challenges of quiz generation in a non-English context specifically Turkish, this study contributes significantly to the field of Turkish educational technology, providing insights into the potential of leveraging LLMs for educational purposes across diverse linguistic landscapes.
A Turkish Educational Crossword Puzzle Generator
May 15, 2024



This paper introduces the first Turkish crossword puzzle generator designed to leverage the capabilities of large language models (LLMs) for educational purposes. In this work, we introduced two specially created datasets: one with over 180,000 unique answer-clue pairs for generating relevant clues from the given answer, and another with over 35,000 samples containing text, answer, category, and clue data, aimed at producing clues for specific texts and keywords within certain categories. Beyond entertainment, this generator emerges as an interactive educational tool that enhances memory, vocabulary, and problem-solving skills. It's a notable step in AI-enhanced education, merging game-like engagement with learning for Turkish and setting new standards for interactive, intelligent learning tools in Turkish.
Clue-Instruct: Text-Based Clue Generation for Educational Crossword Puzzles
Apr 09, 2024Crossword puzzles are popular linguistic games often used as tools to engage students in learning. Educational crosswords are characterized by less cryptic and more factual clues that distinguish them from traditional crossword puzzles. Despite there exist several publicly available clue-answer pair databases for traditional crosswords, educational clue-answer pairs datasets are missing. In this article, we propose a methodology to build educational clue generation datasets that can be used to instruct Large Language Models (LLMs). By gathering from Wikipedia pages informative content associated with relevant keywords, we use Large Language Models to automatically generate pedagogical clues related to the given input keyword and its context. With such an approach, we created clue-instruct, a dataset containing 44,075 unique examples with text-keyword pairs associated with three distinct crossword clues. We used clue-instruct to instruct different LLMs to generate educational clues from a given input content and keyword. Both human and automatic evaluations confirmed the quality of the generated clues, thus validating the effectiveness of our approach.
AI-Powered Arabic Crossword Puzzle Generation for Educational Applications
Dec 03, 2023


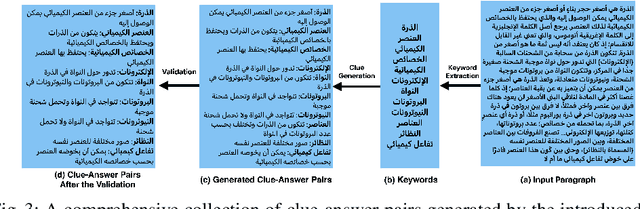
This paper presents the first Arabic crossword puzzle generator driven by advanced AI technology. Leveraging cutting-edge large language models including GPT4, GPT3-Davinci, GPT3-Curie, GPT3-Babbage, GPT3-Ada, and BERT, the system generates distinctive and challenging clues. Based on a dataset comprising over 50,000 clue-answer pairs, the generator employs fine-tuning, few/zero-shot learning strategies, and rigorous quality-checking protocols to enforce the generation of high-quality clue-answer pairs. Importantly, educational crosswords contribute to enhancing memory, expanding vocabulary, and promoting problem-solving skills, thereby augmenting the learning experience through a fun and engaging approach, reshaping the landscape of traditional learning methods. The overall system can be exploited as a powerful educational tool that amalgamates AI and innovative learning techniques, heralding a transformative era for Arabic crossword puzzles and the intersection of technology and education.
Italian Crossword Generator: Enhancing Education through Interactive Word Puzzles
Nov 27, 2023Educational crosswords offer numerous benefits for students, including increased engagement, improved understanding, critical thinking, and memory retention. Creating high-quality educational crosswords can be challenging, but recent advances in natural language processing and machine learning have made it possible to use language models to generate nice wordplays. The exploitation of cutting-edge language models like GPT3-DaVinci, GPT3-Curie, GPT3-Babbage, GPT3-Ada, and BERT-uncased has led to the development of a comprehensive system for generating and verifying crossword clues. A large dataset of clue-answer pairs was compiled to fine-tune the models in a supervised manner to generate original and challenging clues from a given keyword. On the other hand, for generating crossword clues from a given text, Zero/Few-shot learning techniques were used to extract clues from the input text, adding variety and creativity to the puzzles. We employed the fine-tuned model to generate data and labeled the acceptability of clue-answer parts with human supervision. To ensure quality, we developed a classifier by fine-tuning existing language models on the labeled dataset. Conversely, to assess the quality of clues generated from the given text using zero/few-shot learning, we employed a zero-shot learning approach to check the quality of generated clues. The results of the evaluation have been very promising, demonstrating the effectiveness of the approach in creating high-standard educational crosswords that offer students engaging and rewarding learning experiences.
The WebCrow French Crossword Solver
Nov 27, 2023Crossword puzzles are one of the most popular word games, played in different languages all across the world, where riddle style can vary significantly from one country to another. Automated crossword resolution is challenging, and typical solvers rely on large databases of previously solved crosswords. In this work, we extend WebCrow 2.0, an automatic crossword solver, to French, making it the first program for crossword solving in the French language. To cope with the lack of a large repository of clue-answer crossword data, WebCrow 2.0 exploits multiple modules, called experts, that retrieve candidate answers from heterogeneous resources, such as the web, knowledge graphs, and linguistic rules. We compared WebCrow's performance against humans in two different challenges. Despite the limited amount of past crosswords, French WebCrow was competitive, actually outperforming humans in terms of speed and accuracy, thus proving its capabilities to generalize to new languages.