 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLIMER-IT: Zero-Shot NER on Italian Language
Sep 24, 2024
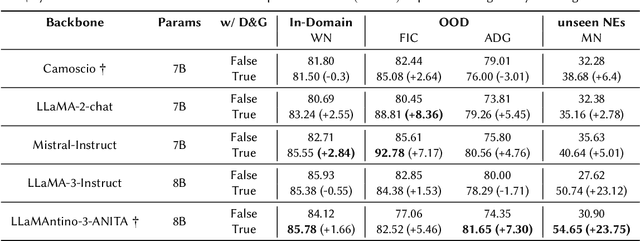
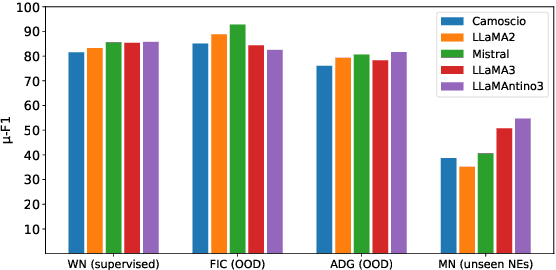
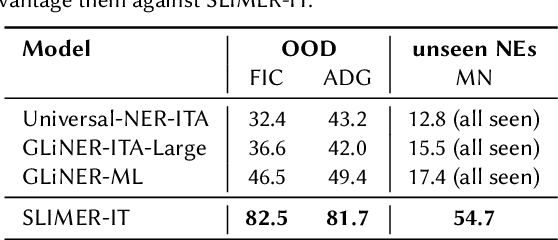
Traditional approaches to Named Entity Recognition (NER) frame the task into a BIO sequence labeling problem. Although these systems often excel in the downstream task at hand, they require extensive annotated data and struggle to generalize to out-of-distribution input domains and unseen entity types. On the contrary, Large Language Models (LLMs) have demonstrated strong zero-shot capabilities. While several works address Zero-Shot NER in English, little has been done in other languages. In this paper, we define an evaluation framework for Zero-Shot NER, applying it to the Italian language. Furthermore, we introduce SLIMER-IT, the Italian version of SLIMER, an instruction-tuning approach for zero-shot NER leveraging prompts enriched with definition and guidelines. Comparisons with other state-of-the-art models, demonstrate the superiority of SLIMER-IT on never-seen-before entity tags.
Show Less, Instruct More: Enriching Prompts with Definitions and Guidelines for Zero-Shot NER
Jul 02, 2024Recently, several specialized instruction-tuned Large Language Models (LLMs) for Named Entity Recognition (NER) have emerged. Compared to traditional NER approaches, these models have strong generalization capabilities. Existing LLMs mainly focus on zero-shot NER in out-of-domain distributions, being fine-tuned on an extensive number of entity classes that often highly or completely overlap with test sets. In this work instead, we propose SLIMER, an approach designed to tackle never-seen-before named entity tags by instructing the model on fewer examples, and by leveraging a prompt enriched with definition and guidelines. Experiments demonstrate that definition and guidelines yield better performance, faster and more robust learning, particularly when labelling unseen Named Entities. Furthermore, SLIMER performs comparably to state-of-the-art approaches in out-of-domain zero-shot NER, while being trained on a reduced tag set.
A Turkish Educational Crossword Puzzle Generator
May 15, 2024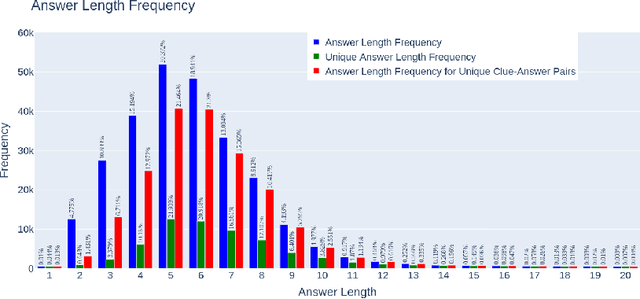



This paper introduces the first Turkish crossword puzzle generator designed to leverage the capabilities of large language models (LLMs) for educational purposes. In this work, we introduced two specially created datasets: one with over 180,000 unique answer-clue pairs for generating relevant clues from the given answer, and another with over 35,000 samples containing text, answer, category, and clue data, aimed at producing clues for specific texts and keywords within certain categories. Beyond entertainment, this generator emerges as an interactive educational tool that enhances memory, vocabulary, and problem-solving skills. It's a notable step in AI-enhanced education, merging game-like engagement with learning for Turkish and setting new standards for interactive, intelligent learning tools in Turkish.
Clue-Instruct: Text-Based Clue Generation for Educational Crossword Puzzles
Apr 09, 2024Crossword puzzles are popular linguistic games often used as tools to engage students in learning. Educational crosswords are characterized by less cryptic and more factual clues that distinguish them from traditional crossword puzzles. Despite there exist several publicly available clue-answer pair databases for traditional crosswords, educational clue-answer pairs datasets are missing. In this article, we propose a methodology to build educational clue generation datasets that can be used to instruct Large Language Models (LLMs). By gathering from Wikipedia pages informative content associated with relevant keywords, we use Large Language Models to automatically generate pedagogical clues related to the given input keyword and its context. With such an approach, we created clue-instruct, a dataset containing 44,075 unique examples with text-keyword pairs associated with three distinct crossword clues. We used clue-instruct to instruct different LLMs to generate educational clues from a given input content and keyword. Both human and automatic evaluations confirmed the quality of the generated clues, thus validating the effectiveness of our approach.
Enhancing Modern Supervised Word Sense Disambiguation Models by Semantic Lexical Resources
Feb 20, 2024



Supervised models for Word Sense Disambiguation (WSD) currently yield to state-of-the-art results in the most popular benchmarks. Despite the recent introduction of Word Embeddings and Recurrent Neural Networks to design powerful context-related features, the interest in improving WSD models using Semantic Lexical Resources (SLRs) is mostly restricted to knowledge-based approaches. In this paper, we enhance "modern" supervised WSD models exploiting two popular SLRs: WordNet and WordNet Domains. We propose an effective way to introduce semantic features into the classifiers, and we consider using the SLR structure to augment the training data. We study the effect of different types of semantic features, investigating their interaction with local contexts encoded by means of mixtures of Word Embeddings or Recurrent Neural Networks, and we extend the proposed model into a novel multi-layer architecture for WSD. A detailed experimental comparison in the recent Unified Evaluation Framework (Raganato et al., 2017) shows that the proposed approach leads to supervised models that compare favourably with the state-of-the art.
* The 11th International Conference on Language Resources and Evaluation (LREC 2018)
A novel integrated industrial approach with cobots in the age of industry 4.0 through conversational interaction and computer vision
Feb 16, 2024From robots that replace workers to robots that serve as helpful colleagues, the field of robotic automation is experiencing a new trend that represents a huge challenge for component manufacturers. The contribution starts from an innovative vision that sees an ever closer collaboration between Cobot, able to do a specific physical job with precision, the AI world, able to analyze information and support the decision-making process, and the man able to have a strategic vision of the future.
Neural paraphrasing by automatically crawled and aligned sentence pairs
Feb 16, 2024

Paraphrasing is the task of re-writing an input text using other words, without altering the meaning of the original content. Conversational systems can exploit automatic paraphrasing to make the conversation more natural, e.g., talking about a certain topic using different paraphrases in different time instants. Recently, the task of automatically generating paraphrases has been approached in the context of Natural Language Generation (NLG). While many existing systems simply consist in rule-based models, the recent success of the Deep Neural Networks in several NLG tasks naturally suggests the possibility of exploiting such networks for generating paraphrases. However, the main obstacle toward neural-network-based paraphrasing is the lack of large datasets with aligned pairs of sentences and paraphrases, that are needed to efficiently train the neural models. In this paper we present a method for the automatic generation of large aligned corpora, that is based on the assumption that news and blog websites talk about the same events using different narrative styles. We propose a similarity search procedure with linguistic constraints that, given a reference sentence, is able to locate the most similar candidate paraphrases out from millions of indexed sentences. The data generation process is evaluated in the case of the Italian language, performing experiments using pointer-based deep neural architectures.
* The 6th International Conference on Social Networks Analysis, Management and Security (SNAMS 2019)
Multitask Kernel-based Learning with Logic Constraints
Feb 16, 2024


This paper presents a general framework to integrate prior knowledge in the form of logic constraints among a set of task functions into kernel machines. The logic propositions provide a partial representation of the environment, in which the learner operates, that is exploited by the learning algorithm together with the information available in the supervised examples. In particular, we consider a multi-task learning scheme, where multiple unary predicates on the feature space are to be learned by kernel machines and a higher level abstract representation consists of logic clauses on these predicates, known to hold for any input. A general approach is presented to convert the logic clauses into a continuous implementation, that processes the outputs computed by the kernel-based predicates. The learning task is formulated as a primal optimization problem of a loss function that combines a term measuring the fitting of the supervised examples, a regularization term, and a penalty term that enforces the constraints on both supervised and unsupervised examples. The proposed semi-supervised learning framework is particularly suited for learning in high dimensionality feature spaces, where the supervised training examples tend to be sparse and generalization difficult. Unlike for standard kernel machines, the cost function to optimize is not generally guaranteed to be convex. However, the experimental results show that it is still possible to find good solutions using a two stage learning schema, in which first the supervised examples are learned until convergence and then the logic constraints are forced. Some promising experimental results on artificial multi-task learning tasks are reported, showing how the classification accuracy can be effectively improved by exploiting the a priori rules and the unsupervised examples.
* The 19th European Conference on Artificial Intelligence (ECAI 2010)
BUSTER: a "BUSiness Transaction Entity Recognition" dataset
Feb 15, 2024Albeit Natural Language Processing has seen major breakthroughs in the last few years, transferring such advances into real-world business cases can be challenging. One of the reasons resides in the displacement between popular benchmarks and actual data. Lack of supervision, unbalanced classes, noisy data and long documents often affect real problems in vertical domains such as finance, law and health. To support industry-oriented research, we present BUSTER, a BUSiness Transaction Entity Recognition dataset. The dataset consists of 3779 manually annotated documents on financial transactions. We establish several baselines exploiting both general-purpose and domain-specific language models. The best performing model is also used to automatically annotate 6196 documents, which we release as an additional silver corpus to BUSTER.
Fast Vocabulary Transfer for Language Model Compression
Feb 15, 2024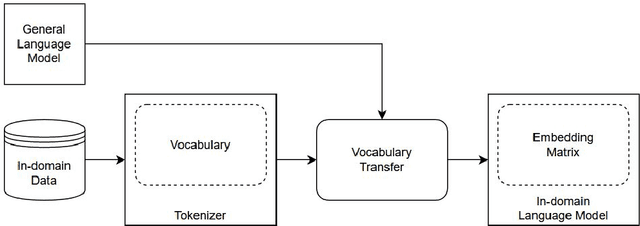
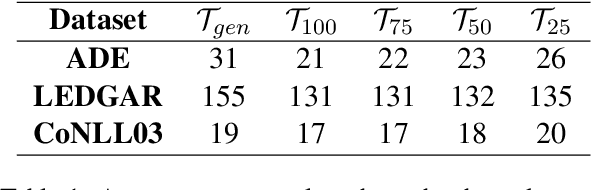

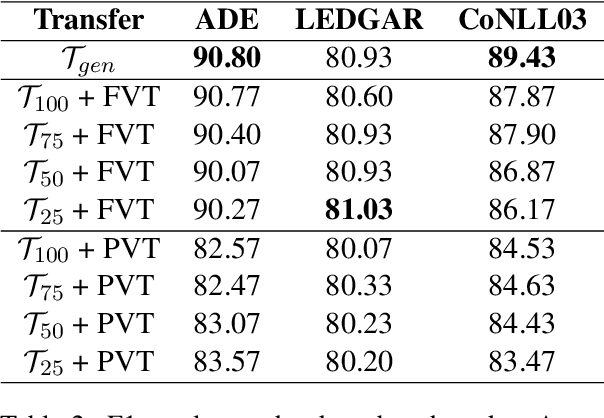
Real-world business applications require a trade-off between language model performance and size. We propose a new method for model compression that relies on vocabulary transfer. We evaluate the method on various vertical domains and downstream tasks. Our results indicate that vocabulary transfer can be effectively used in combination with other compression techniques, yielding a significant reduction in model size and inference time while marginally compromising on performance.
* The 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022)