 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLIMER-IT: Zero-Shot NER on Italian Language
Paper and Code

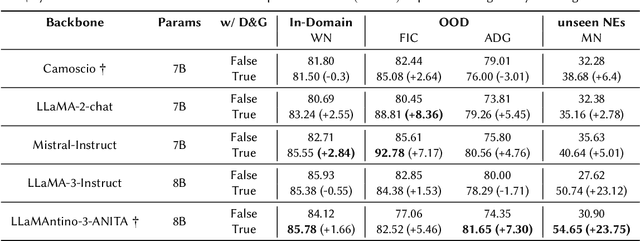
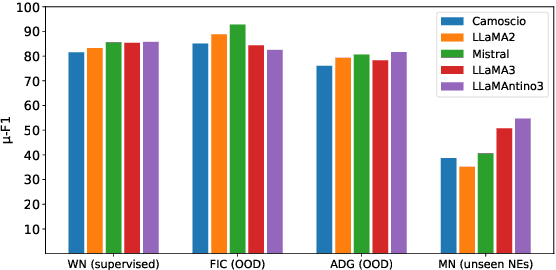
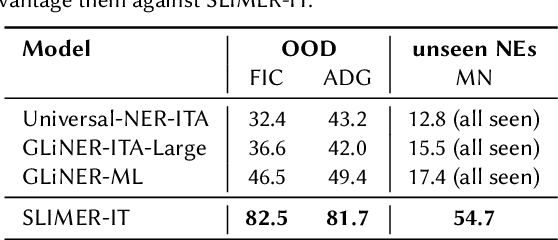
Traditional approaches to Named Entity Recognition (NER) frame the task into a BIO sequence labeling problem. Although these systems often excel in the downstream task at hand, they require extensive annotated data and struggle to generalize to out-of-distribution input domains and unseen entity types. On the contrary, Large Language Models (LLMs) have demonstrated strong zero-shot capabilities. While several works address Zero-Shot NER in English, little has been done in other languages. In this paper, we define an evaluation framework for Zero-Shot NER, applying it to the Italian language. Furthermore, we introduce SLIMER-IT, the Italian version of SLIMER, an instruction-tuning approach for zero-shot NER leveraging prompts enriched with definition and guidelines. Comparisons with other state-of-the-art models, demonstrate the superiority of SLIMER-IT on never-seen-before entity tags.