 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Online Inference of Vision Transformers by Training-Free Tokenization
Nov 23, 2024



The cost of deploying vision transformers increasingly represents a barrier to wider industrial adoption. Existing compression requires additional end-to-end fine-tuning or incurs a significant drawback to runtime, thus making them ill-suited for online inference. We introduce the $\textbf{Visual Word Tokenizer}$ (VWT), a training-free method for reducing energy costs while retaining performance and runtime. The VWT groups patches (visual subwords) that are frequently used into visual words while infrequent ones remain intact. To do so, intra-image or inter-image statistics are leveraged to identify similar visual concepts for compression. Experimentally, we demonstrate a reduction in wattage of up to 19% with only a 20% increase in runtime at most. Comparative approaches of 8-bit quantization and token merging achieve a lower or similar energy efficiency but exact a higher toll on runtime (up to $2\times$ or more). Our results indicate that VWTs are well-suited for efficient online inference with a marginal compromise on performance.
Code-Optimise: Self-Generated Preference Data for Correctness and Efficiency
Jun 18, 2024Code Language Models have been trained to generate accurate solutions, typically with no regard for runtime. On the other hand, previous works that explored execution optimisation have observed corresponding drops in functional correctness. To that end, we introduce Code-Optimise, a framework that incorporates both correctness (passed, failed) and runtime (quick, slow) as learning signals via self-generated preference data. Our framework is both lightweight and robust as it dynamically selects solutions to reduce overfitting while avoiding a reliance on larger models for learning signals. Code-Optimise achieves significant improvements in pass@k while decreasing the competitive baseline runtimes by an additional 6% for in-domain data and up to 3% for out-of-domain data. As a byproduct, the average length of the generated solutions is reduced by up to 48% on MBPP and 23% on HumanEval, resulting in faster and cheaper inference. The generated data and codebase will be open-sourced at www.open-source.link.
Are Compressed Language Models Less Subgroup Robust?
Mar 26, 2024
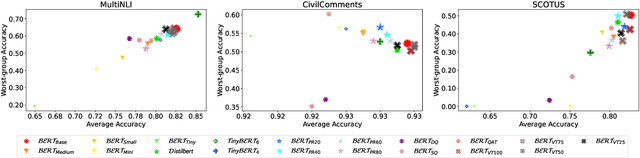
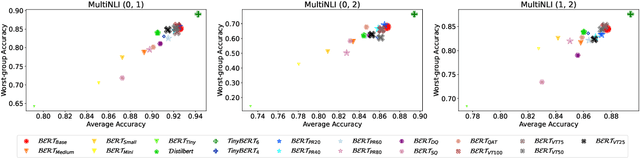

To reduce the inference cost of large language models, model compression is increasingly used to create smaller scalable models. However, little is known about their robustness to minority subgroups defined by the labels and attributes of a dataset. In this paper, we investigate the effects of 18 different compression methods and settings on the subgroup robustness of BERT language models. We show that worst-group performance does not depend on model size alone, but also on the compression method used. Additionally, we find that model compression does not always worsen the performance on minority subgroups. Altogether, our analysis serves to further research into the subgroup robustness of model compression.
* The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023)
Fast Vocabulary Transfer for Language Model Compression
Feb 15, 2024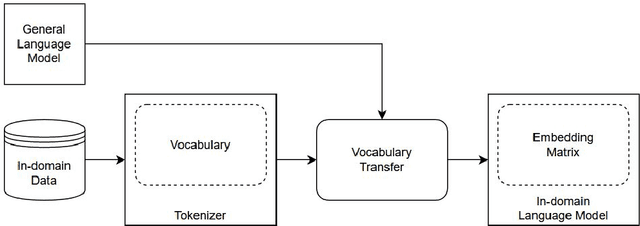

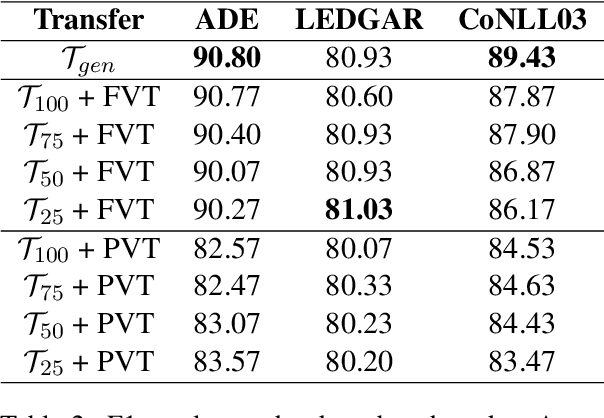
Real-world business applications require a trade-off between language model performance and size. We propose a new method for model compression that relies on vocabulary transfer. We evaluate the method on various vertical domains and downstream tasks. Our results indicate that vocabulary transfer can be effectively used in combination with other compression techniques, yielding a significant reduction in model size and inference time while marginally compromising on performance.
* The 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP 2022)
Multi-Word Tokenization for Sequence Compression
Feb 15, 2024
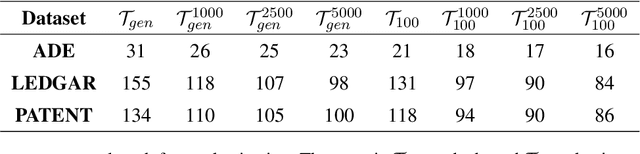
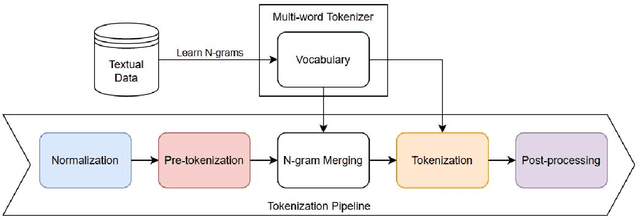
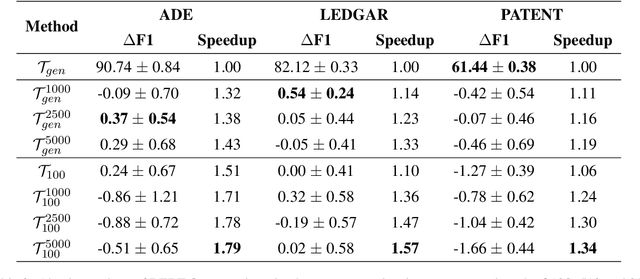
Large Language Models have proven highly successful at modelling a variety of tasks. However, this comes at a steep computational cost that hinders wider industrial uptake. In this pa005 per, we present MWT: a Multi-Word Tokenizer that goes beyond word boundaries by representing frequent multi-word expressions as single tokens. MWTs produce a more compact and efficient tokenization that yields two benefits: (1) Increase in performance due to a greater coverage of input data given a fixed sequence length and budget; (2) Faster and lighter inference due to the ability to reduce the sequence length with negligible drops in performance. Our results show that MWT is more robust across shorter sequence lengths, thus allowing for major speedups via early sequence truncation.
* The 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023)