 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Efficient Writer-Independent IMU-Based Handwriting Recognization
Feb 28, 2025Online handwriting recognition (HWR) using data from inertial measurement units (IMUs) remains challenging due to variations in writing styles and the limited availability of high-quality annotated datasets. Traditional models often struggle to recognize handwriting from unseen writers, making writer-independent (WI) recognition a crucial but difficult problem. This paper presents an HWR model with an encoder-decoder structure for IMU data, featuring a CNN-based encoder for feature extraction and a BiLSTM decoder for sequence modeling, which supports inputs of varying lengths. Our approach demonstrates strong robustness and data efficiency, outperforming existing methods on WI datasets, including the WI split of the OnHW dataset and our own dataset. Extensive evaluations show that our model maintains high accuracy across different age groups and writing conditions while effectively learning from limited data. Through comprehensive ablation studies, we analyze key design choices, achieving a balance between accuracy and efficiency. These findings contribute to the development of more adaptable and scalable HWR systems for real-world applications.
Towards an IMU-based Pen Online Handwriting Recognizer
May 26, 2021
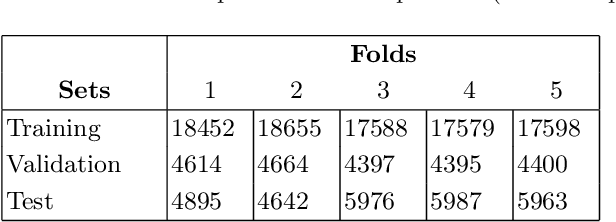


Most online handwriting recognition systems require the use of specific writing surfaces to extract positional data. In this paper we present a online handwriting recognition system for word recognition which is based on inertial measurement units (IMUs) for digitizing text written on paper. This is obtained by means of a sensor-equipped pen that provides acceleration, angular velocity, and magnetic forces streamed via Bluetooth. Our model combines convolutional and bidirectional LSTM networks, and is trained with the Connectionist Temporal Classification loss that allows the interpretation of raw sensor data into words without the need of sequence segmentation. We use a dataset of words collected using multiple sensor-enhanced pens and evaluate our model on distinct test sets of seen and unseen words achieving a character error rate of 17.97% and 17.08%, respectively, without the use of a dictionary or language model