 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Misclassifications of Robust Neural Networks to Enhance Adversarial Attacks
Paper and Code


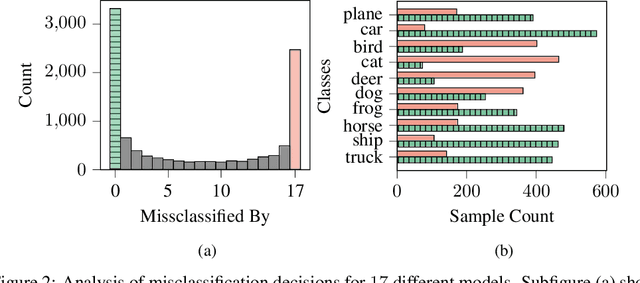
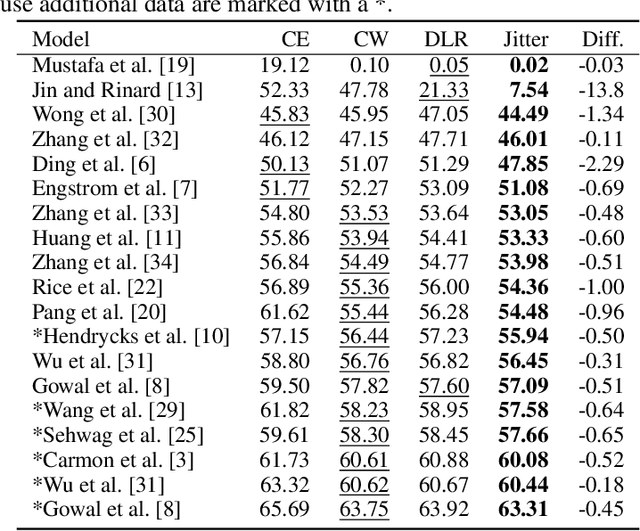
Progress in making neural networks more robust against adversarial attacks is mostly marginal, despite the great efforts of the research community. Moreover, the robustness evaluation is often imprecise, making it difficult to identify promising approaches. We analyze the classification decisions of 19 different state-of-the-art neural networks trained to be robust against adversarial attacks. Our findings suggest that current untargeted adversarial attacks induce misclassification towards only a limited amount of different classes. Additionally, we observe that both over- and under-confidence in model predictions result in an inaccurate assessment of model robustness. Based on these observations, we propose a novel loss function for adversarial attacks that consistently improves attack success rate compared to prior loss functions for 19 out of 19 analyzed models.