 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifelong Graph Summarization with Neural Networks: 2012, 2022, and a Time Warp
Jul 25, 2024



Summarizing web graphs is challenging due to the heterogeneity of the modeled information and its changes over time. We investigate the use of neural networks for lifelong graph summarization. Assuming we observe the web graph at a certain time, we train the networks to summarize graph vertices. We apply this trained network to summarize the vertices of the changed graph at the next point in time. Subsequently, we continue training and evaluating the network to perform lifelong graph summarization. We use the GNNs Graph-MLP and GraphSAINT, as well as an MLP baseline, to summarize the temporal graphs. We compare $1$-hop and $2$-hop summaries. We investigate the impact of reusing parameters from a previous snapshot by measuring the backward and forward transfer and the forgetting rate of the neural networks. Our extensive experiments on ten weekly snapshots of a web graph with over $100$M edges, sampled in 2012 and 2022, show that all networks predominantly use $1$-hop information to determine the summary, even when performing $2$-hop summarization. Due to the heterogeneity of web graphs, in some snapshots, the $2$-hop summary produces over ten times more vertex summaries than the $1$-hop summary. When using the network trained on the last snapshot from 2012 and applying it to the first snapshot of 2022, we observe a strong drop in accuracy. We attribute this drop over the ten-year time warp to the strongly increased heterogeneity of the web graph in 2022.
Graph Summarization with Graph Neural Networks
Mar 11, 2022

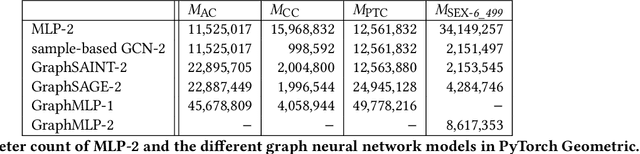

The goal of graph summarization is to represent large graphs in a structured and compact way. A graph summary based on equivalence classes preserves pre-defined features of a graph's vertex within a $k$-hop neighborhood such as the vertex labels and edge labels. Based on these neighborhood characteristics, the vertex is assigned to an equivalence class. The calculation of the assigned equivalence class must be a permutation invariant operation on the pre-defined features. This is achieved by sorting on the feature values, e. g., the edge labels, which is computationally expensive, and subsequently hashing the result. Graph Neural Networks (GNN) fulfill the permutation invariance requirement. We formulate the problem of graph summarization as a subgraph classification task on the root vertex of the $k$-hop neighborhood. We adapt different GNN architectures, both based on the popular message-passing protocol and alternative approaches, to perform the structural graph summarization task. We compare different GNNs with a standard multi-layer perceptron (MLP) and Bloom filter as non-neural method. For our experiments, we consider four popular graph summary models on a large web graph. This resembles challenging multi-class vertex classification tasks with the numbers of classes ranging from $576$ to multiple hundreds of thousands. Our results show that the performance of GNNs are close to each other. In three out of four experiments, the non-message-passing GraphMLP model outperforms the other GNNs. The performance of the standard MLP is extraordinary good, especially in the presence of many classes. Finally, the Bloom filter outperforms all neural architectures by a large margin, except for the dataset with the fewest number of $576$ classes.