 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaking the Next Step with Generative Artificial Intelligence: The Transformative Role of Multimodal Large Language Models in Science Education
Jan 01, 2024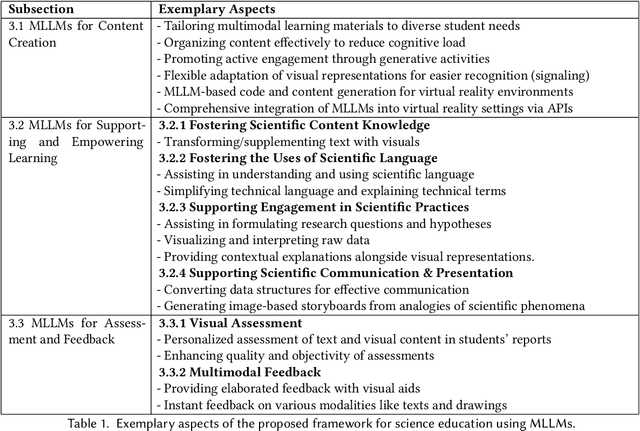
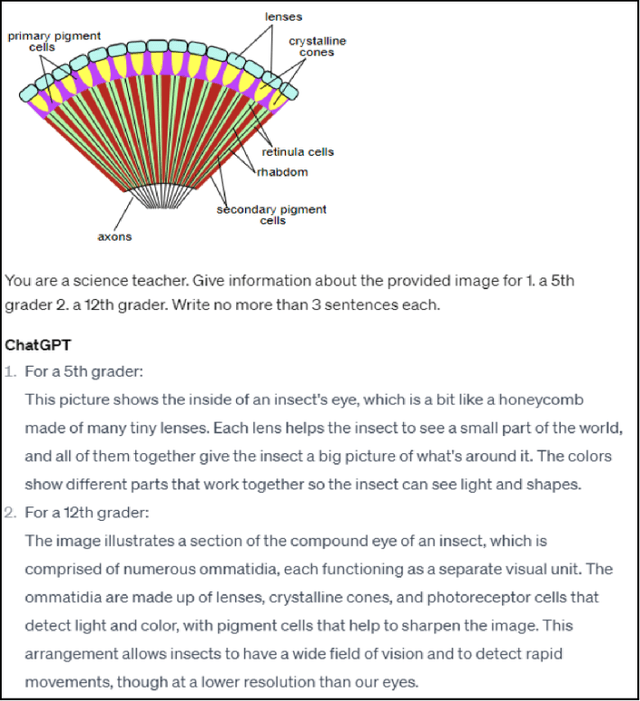
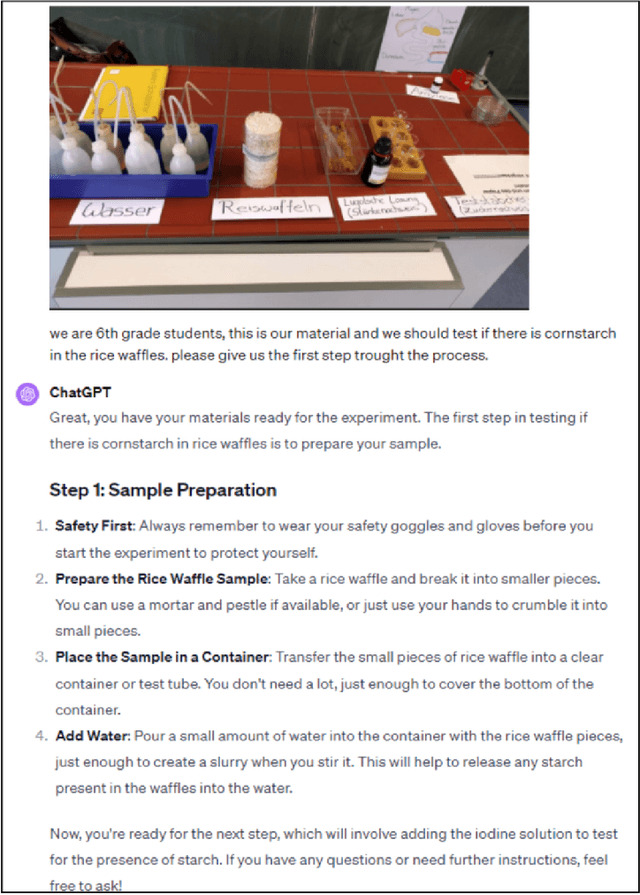
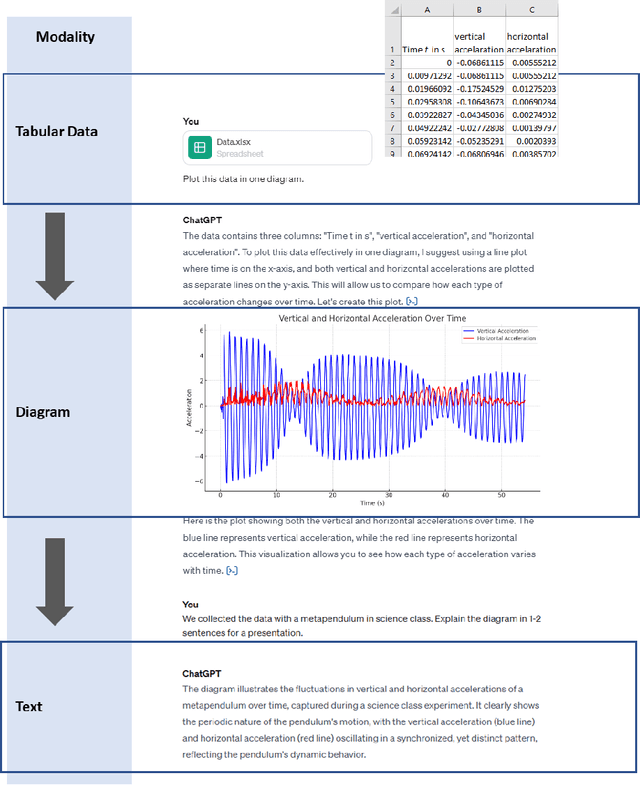
The integration of Artificial Intelligence (AI), particularly Large Language Model (LLM)-based systems, in education has shown promise in enhancing teaching and learning experiences. However, the advent of Multimodal Large Language Models (MLLMs) like GPT-4 with vision (GPT-4V), capable of processing multimodal data including text, sound, and visual inputs, opens a new era of enriched, personalized, and interactive learning landscapes in education. Grounded in theory of multimedia learning, this paper explores the transformative role of MLLMs in central aspects of science education by presenting exemplary innovative learning scenarios. Possible applications for MLLMs could range from content creation to tailored support for learning, fostering competencies in scientific practices, and providing assessment and feedback. These scenarios are not limited to text-based and uni-modal formats but can be multimodal, increasing thus personalization, accessibility, and potential learning effectiveness. Besides many opportunities, challenges such as data protection and ethical considerations become more salient, calling for robust frameworks to ensure responsible integration. This paper underscores the necessity for a balanced approach in implementing MLLMs, where the technology complements rather than supplants the educator's role, ensuring thus an effective and ethical use of AI in science education. It calls for further research to explore the nuanced implications of MLLMs on the evolving role of educators and to extend the discourse beyond science education to other disciplines. Through the exploration of potentials, challenges, and future implications, we aim to contribute to a preliminary understanding of the transformative trajectory of MLLMs in science education and beyond.
A Holistic Approach for Modeling and Synthesis of Image Processing Applications for Heterogeneous Computing Architectures
Feb 26, 2015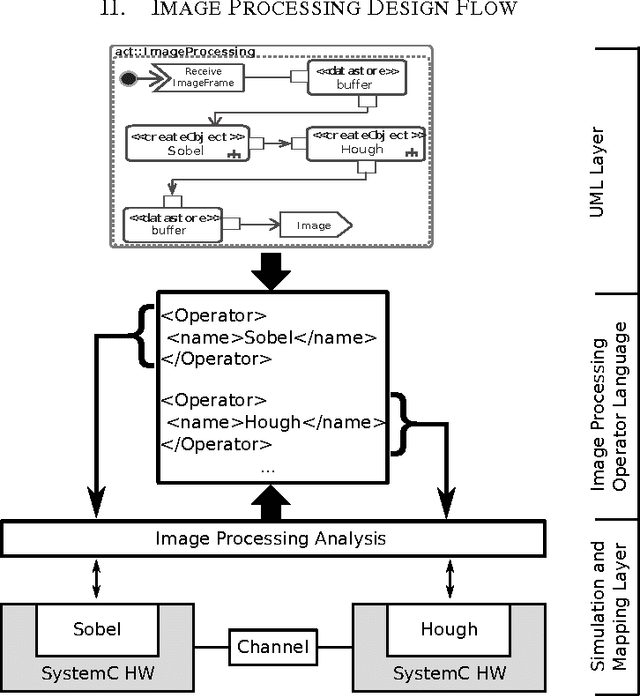
Image processing applications are common in every field of our daily life. However, most of them are very complex and contain several tasks with different complexities which result in varying requirements for computing architectures. Nevertheless, a general processing scheme in every image processing application has a similar structure, called image processing pipeline: (1) capturing an image, (2) pre-processing using local operators, (3) processing with global operators and (4) post-processing using complex operations. Therefore, application-specialized hardware solutions based on heterogeneous architectures are used for image processing. Unfortunately the development of applications for heterogeneous hardware architectures is challenging due to the distribution of computational tasks among processors and programmable logic units. Nowadays, image processing systems are started from scratch which is time-consuming, error-prone and inflexible. A new methodology for modeling and implementing is needed in order to reduce the development time of heterogenous image processing systems. This paper introduces a new holistic top down approach for image processing systems. Two challenges have to be investigated. First, designers ought to be able to model their complete image processing pipeline on an abstract layer using UML. Second, we want to close the gap between the abstract system and the system architecture.