 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Adaptive Feedback with AI: Comparing the Feedback Quality of LLMs and Teachers on Experimentation Protocols
Feb 18, 2025



Effective feedback is essential for fostering students' success in scientific inquiry. With advancements in artificial intelligence, large language models (LLMs) offer new possibilities for delivering instant and adaptive feedback. However, this feedback often lacks the pedagogical validation provided by real-world practitioners. To address this limitation, our study evaluates and compares the feedback quality of LLM agents with that of human teachers and science education experts on student-written experimentation protocols. Four blinded raters, all professionals in scientific inquiry and science education, evaluated the feedback texts generated by 1) the LLM agent, 2) the teachers and 3) the science education experts using a five-point Likert scale based on six criteria of effective feedback: Feed Up, Feed Back, Feed Forward, Constructive Tone, Linguistic Clarity, and Technical Terminology. Our results indicate that LLM-generated feedback shows no significant difference to that of teachers and experts in overall quality. However, the LLM agent's performance lags in the Feed Back dimension, which involves identifying and explaining errors within the student's work context. Qualitative analysis highlighted the LLM agent's limitations in contextual understanding and in the clear communication of specific errors. Our findings suggest that combining LLM-generated feedback with human expertise can enhance educational practices by leveraging the efficiency of LLMs and the nuanced understanding of educators.
Taking the Next Step with Generative Artificial Intelligence: The Transformative Role of Multimodal Large Language Models in Science Education
Jan 01, 2024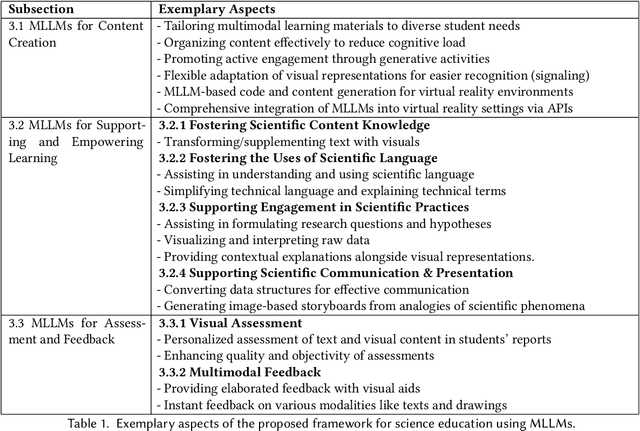
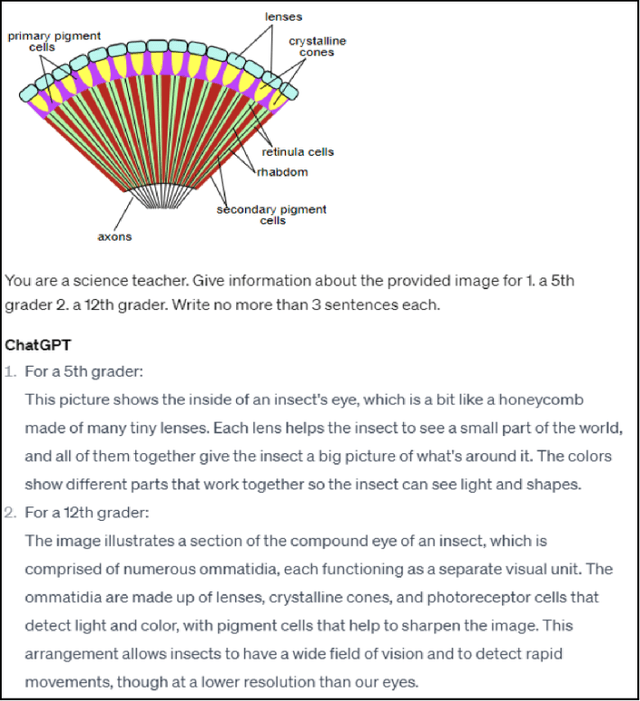
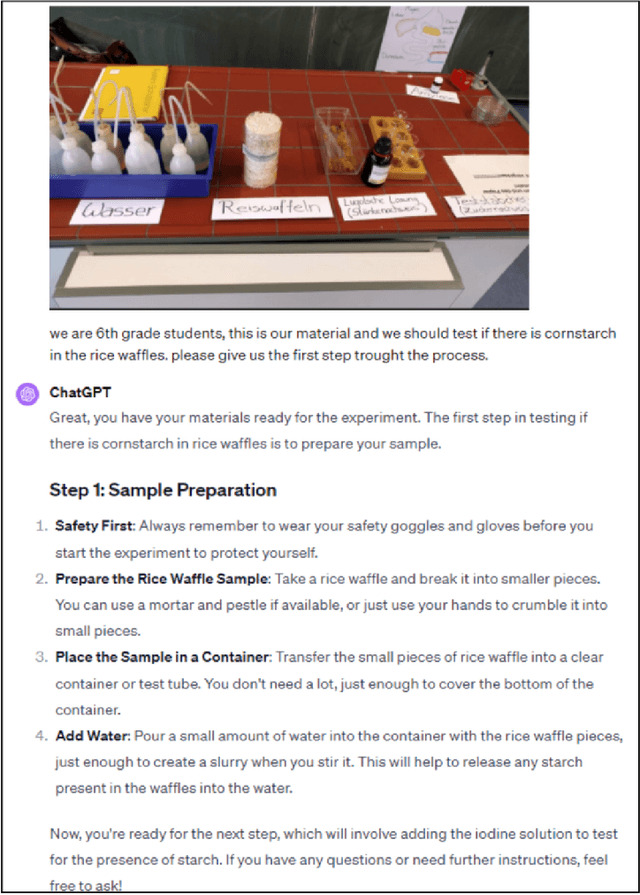
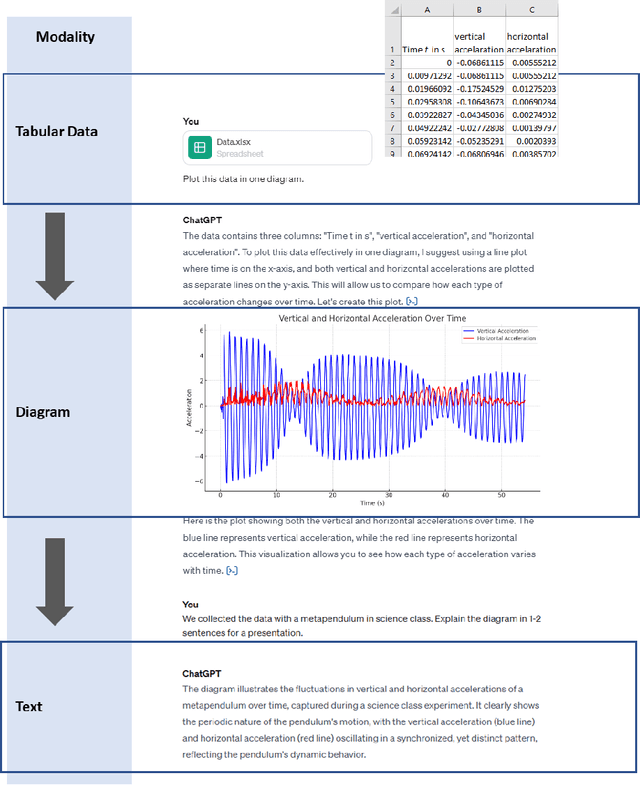
The integration of Artificial Intelligence (AI), particularly Large Language Model (LLM)-based systems, in education has shown promise in enhancing teaching and learning experiences. However, the advent of Multimodal Large Language Models (MLLMs) like GPT-4 with vision (GPT-4V), capable of processing multimodal data including text, sound, and visual inputs, opens a new era of enriched, personalized, and interactive learning landscapes in education. Grounded in theory of multimedia learning, this paper explores the transformative role of MLLMs in central aspects of science education by presenting exemplary innovative learning scenarios. Possible applications for MLLMs could range from content creation to tailored support for learning, fostering competencies in scientific practices, and providing assessment and feedback. These scenarios are not limited to text-based and uni-modal formats but can be multimodal, increasing thus personalization, accessibility, and potential learning effectiveness. Besides many opportunities, challenges such as data protection and ethical considerations become more salient, calling for robust frameworks to ensure responsible integration. This paper underscores the necessity for a balanced approach in implementing MLLMs, where the technology complements rather than supplants the educator's role, ensuring thus an effective and ethical use of AI in science education. It calls for further research to explore the nuanced implications of MLLMs on the evolving role of educators and to extend the discourse beyond science education to other disciplines. Through the exploration of potentials, challenges, and future implications, we aim to contribute to a preliminary understanding of the transformative trajectory of MLLMs in science education and beyond.
Assessing Student Errors in Experimentation Using Artificial Intelligence and Large Language Models: A Comparative Study with Human Raters
Aug 11, 2023Identifying logical errors in complex, incomplete or even contradictory and overall heterogeneous data like students' experimentation protocols is challenging. Recognizing the limitations of current evaluation methods, we investigate the potential of Large Language Models (LLMs) for automatically identifying student errors and streamlining teacher assessments. Our aim is to provide a foundation for productive, personalized feedback. Using a dataset of 65 student protocols, an Artificial Intelligence (AI) system based on the GPT-3.5 and GPT-4 series was developed and tested against human raters. Our results indicate varying levels of accuracy in error detection between the AI system and human raters. The AI system can accurately identify many fundamental student errors, for instance, the AI system identifies when a student is focusing the hypothesis not on the dependent variable but solely on an expected observation (acc. = 0.90), when a student modifies the trials in an ongoing investigation (acc. = 1), and whether a student is conducting valid test trials (acc. = 0.82) reliably. The identification of other, usually more complex errors, like whether a student conducts a valid control trial (acc. = .60), poses a greater challenge. This research explores not only the utility of AI in educational settings, but also contributes to the understanding of the capabilities of LLMs in error detection in inquiry-based learning like experimentation.