 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge5G-DIL: Domain Incremental Learning with Similarity-Aware Sampling for Dynamic 5G Indoor Localization
May 23, 2025Indoor positioning based on 5G data has achieved high accuracy through the adoption of recent machine learning (ML) techniques. However, the performance of learning-based methods degrades significantly when environmental conditions change, thereby hindering their applicability to new scenarios. Acquiring new training data for each environmental change and fine-tuning ML models is both time-consuming and resource-intensive. This paper introduces a domain incremental learning (DIL) approach for dynamic 5G indoor localization, called 5G-DIL, enabling rapid adaptation to environmental changes. We present a novel similarity-aware sampling technique based on the Chebyshev distance, designed to efficiently select specific exemplars from the previous environment while training only on the modified regions of the new environment. This avoids the need to train on the entire region, significantly reducing the time and resources required for adaptation without compromising localization accuracy. This approach requires as few as 50 exemplars from adaptation domains, significantly reducing training time while maintaining high positioning accuracy in previous environments. Comparative evaluations against state-of-the-art DIL techniques on a challenging real-world indoor dataset demonstrate the effectiveness of the proposed sample selection method. Our approach is adaptable to real-world non-line-of-sight propagation scenarios and achieves an MAE positioning error of 0.261 meters, even under dynamic environmental conditions. Code: https://gitlab.cc-asp.fraunhofer.de/5g-pos/5g-dil
VAE-based Feature Disentanglement for Data Augmentation and Compression in Generalized GNSS Interference Classification
Apr 14, 2025Distributed learning and Edge AI necessitate efficient data processing, low-latency communication, decentralized model training, and stringent data privacy to facilitate real-time intelligence on edge devices while reducing dependency on centralized infrastructure and ensuring high model performance. In the context of global navigation satellite system (GNSS) applications, the primary objective is to accurately monitor and classify interferences that degrade system performance in distributed environments, thereby enhancing situational awareness. To achieve this, machine learning (ML) models can be deployed on low-resource devices, ensuring minimal communication latency and preserving data privacy. The key challenge is to compress ML models while maintaining high classification accuracy. In this paper, we propose variational autoencoders (VAEs) for disentanglement to extract essential latent features that enable accurate classification of interferences. We demonstrate that the disentanglement approach can be leveraged for both data compression and data augmentation by interpolating the lower-dimensional latent representations of signal power. To validate our approach, we evaluate three VAE variants - vanilla, factorized, and conditional generative - on four distinct datasets, including two collected in controlled indoor environments and two real-world highway datasets. Additionally, we conduct extensive hyperparameter searches to optimize performance. Our proposed VAE achieves a data compression rate ranging from 512 to 8,192 and achieves an accuracy up to 99.92%.
Evaluation of (Un-)Supervised Machine Learning Methods for GNSS Interference Classification with Real-World Data Discrepancies
Mar 31, 2025



The accuracy and reliability of vehicle localization on roads are crucial for applications such as self-driving cars, toll systems, and digital tachographs. To achieve accurate positioning, vehicles typically use global navigation satellite system (GNSS) receivers to validate their absolute positions. However, GNSS-based positioning can be compromised by interference signals, necessitating the identification, classification, determination of purpose, and localization of such interference to mitigate or eliminate it. Recent approaches based on machine learning (ML) have shown superior performance in monitoring interference. However, their feasibility in real-world applications and environments has yet to be assessed. Effective implementation of ML techniques requires training datasets that incorporate realistic interference signals, including real-world noise and potential multipath effects that may occur between transmitter, receiver, and satellite in the operational area. Additionally, these datasets require reference labels. Creating such datasets is often challenging due to legal restrictions, as causing interference to GNSS sources is strictly prohibited. Consequently, the performance of ML-based methods in practical applications remains unclear. To address this gap, we describe a series of large-scale measurement campaigns conducted in real-world settings at two highway locations in Germany and the Seetal Alps in Austria, and in large-scale controlled indoor environments. We evaluate the latest supervised ML-based methods to report on their performance in real-world settings and present the applicability of pseudo-labeling for unsupervised learning. We demonstrate the challenges of combining datasets due to data discrepancies and evaluate outlier detection, domain adaptation, and data augmentation techniques to present the models' capabilities to adapt to changes in the datasets.
* 34 pages, 25 figures
Multimodal-to-Text Prompt Engineering in Large Language Models Using Feature Embeddings for GNSS Interference Characterization
Jan 09, 2025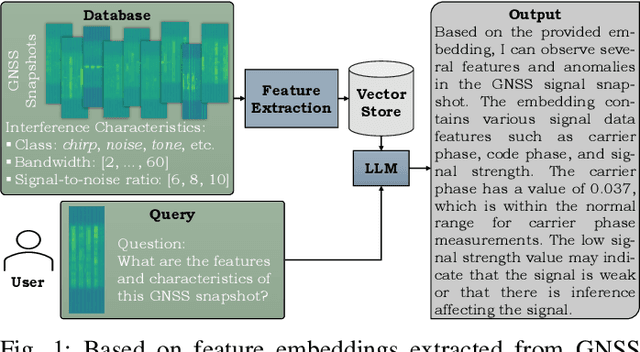



Large language models (LLMs) are advanced AI systems applied across various domains, including NLP, information retrieval, and recommendation systems. Despite their adaptability and efficiency, LLMs have not been extensively explored for signal processing tasks, particularly in the domain of global navigation satellite system (GNSS) interference monitoring. GNSS interference monitoring is essential to ensure the reliability of vehicle localization on roads, a critical requirement for numerous applications. However, GNSS-based positioning is vulnerable to interference from jamming devices, which can compromise its accuracy. The primary objective is to identify, classify, and mitigate these interferences. Interpreting GNSS snapshots and the associated interferences presents significant challenges due to the inherent complexity, including multipath effects, diverse interference types, varying sensor characteristics, and satellite constellations. In this paper, we extract features from a large GNSS dataset and employ LLaVA to retrieve relevant information from an extensive knowledge base. We employ prompt engineering to interpret the interferences and environmental factors, and utilize t-SNE to analyze the feature embeddings. Our findings demonstrate that the proposed method is capable of visual and logical reasoning within the GNSS context. Furthermore, our pipeline outperforms state-of-the-art machine learning models in interference classification tasks.
Federated Learning with MMD-based Early Stopping for Adaptive GNSS Interference Classification
Oct 21, 2024



Federated learning (FL) enables multiple devices to collaboratively train a global model while maintaining data on local servers. Each device trains the model on its local server and shares only the model updates (i.e., gradient weights) during the aggregation step. A significant challenge in FL is managing the feature distribution of novel, unbalanced data across devices. In this paper, we propose an FL approach using few-shot learning and aggregation of the model weights on a global server. We introduce a dynamic early stopping method to balance out-of-distribution classes based on representation learning, specifically utilizing the maximum mean discrepancy of feature embeddings between local and global models. An exemplary application of FL is orchestrating machine learning models along highways for interference classification based on snapshots from global navigation satellite system (GNSS) receivers. Extensive experiments on four GNSS datasets from two real-world highways and controlled environments demonstrate that our FL method surpasses state-of-the-art techniques in adapting to both novel interference classes and multipath scenarios.
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
May 17, 2024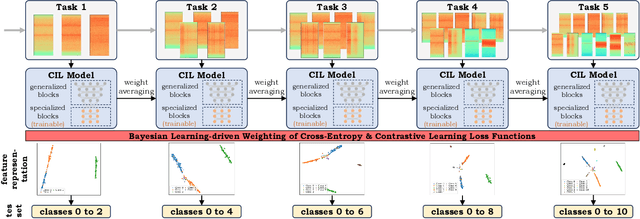
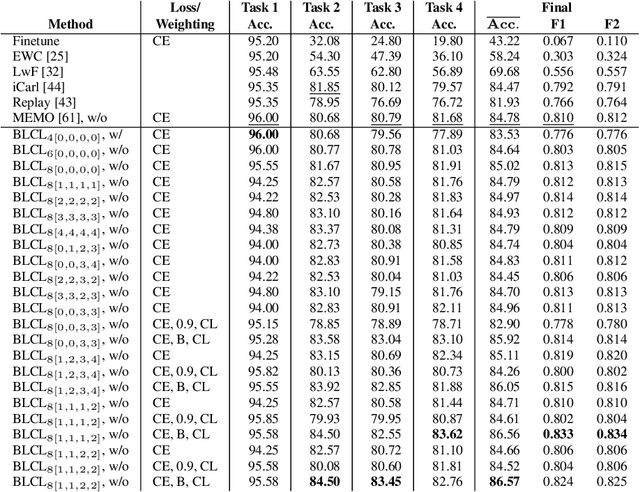
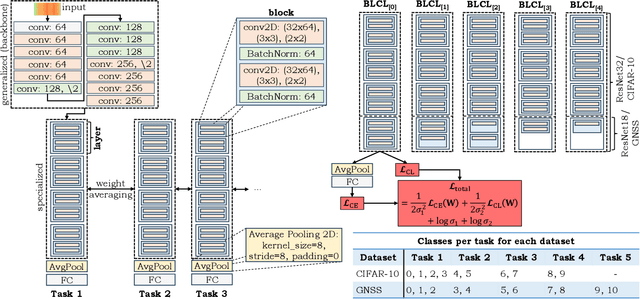
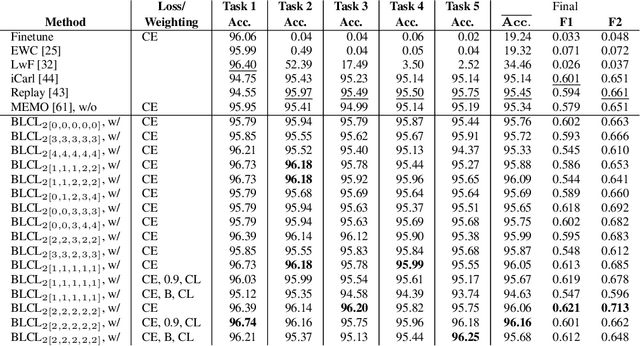
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
Few-Shot Learning with Uncertainty-based Quadruplet Selection for Interference Classification in GNSS Data
Feb 09, 2024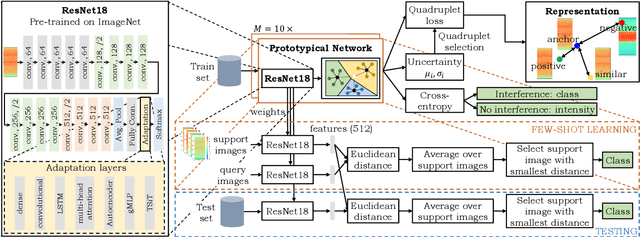

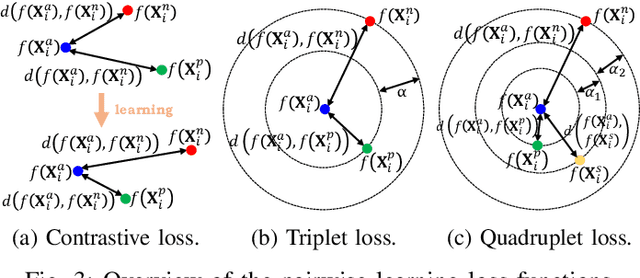
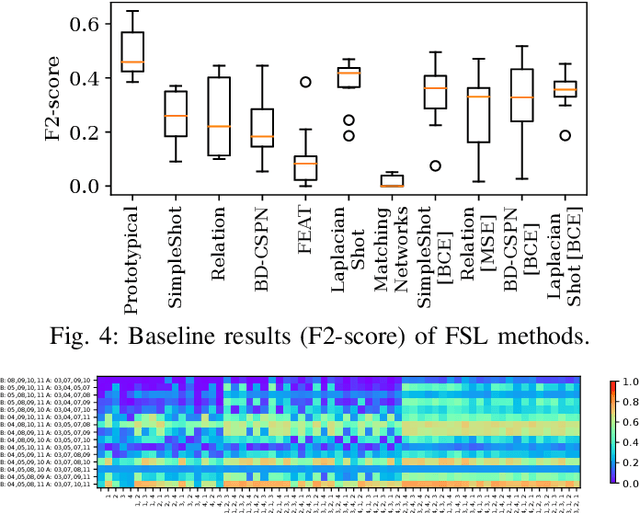
Jamming devices pose a significant threat by disrupting signals from the global navigation satellite system (GNSS), compromising the robustness of accurate positioning. Detecting anomalies in frequency snapshots is crucial to counteract these interferences effectively. The ability to adapt to diverse, unseen interference characteristics is essential for ensuring the reliability of GNSS in real-world applications. In this paper, we propose a few-shot learning (FSL) approach to adapt to new interference classes. Our method employs quadruplet selection for the model to learn representations using various positive and negative interference classes. Furthermore, our quadruplet variant selects pairs based on the aleatoric and epistemic uncertainty to differentiate between similar classes. We recorded a dataset at a motorway with eight interference classes on which our FSL method with quadruplet loss outperforms other FSL techniques in jammer classification accuracy with 97.66%.
Fusing Structure from Motion and Simulation-Augmented Pose Regression from Optical Flow for Challenging Indoor Environments
Apr 14, 2023The localization of objects is a crucial task in various applications such as robotics, virtual and augmented reality, and the transportation of goods in warehouses. Recent advances in deep learning have enabled the localization using monocular visual cameras. While structure from motion (SfM) predicts the absolute pose from a point cloud, absolute pose regression (APR) methods learn a semantic understanding of the environment through neural networks. However, both fields face challenges caused by the environment such as motion blur, lighting changes, repetitive patterns, and feature-less structures. This study aims to address these challenges by incorporating additional information and regularizing the absolute pose using relative pose regression (RPR) methods. The optical flow between consecutive images is computed using the Lucas-Kanade algorithm, and the relative pose is predicted using an auxiliary small recurrent convolutional network. The fusion of absolute and relative poses is a complex task due to the mismatch between the global and local coordinate systems. State-of-the-art methods fusing absolute and relative poses use pose graph optimization (PGO) to regularize the absolute pose predictions using relative poses. In this work, we propose recurrent fusion networks to optimally align absolute and relative pose predictions to improve the absolute pose prediction. We evaluate eight different recurrent units and construct a simulation environment to pre-train the APR and RPR networks for better generalized training. Additionally, we record a large database of different scenarios in a challenging large-scale indoor environment that mimics a warehouse with transportation robots. We conduct hyperparameter searches and experiments to show the effectiveness of our recurrent fusion method compared to PGO.
Representation Learning for Tablet and Paper Domain Adaptation in Favor of Online Handwriting Recognition
Jan 16, 2023The performance of a machine learning model degrades when it is applied to data from a similar but different domain than the data it has initially been trained on. The goal of domain adaptation (DA) is to mitigate this domain shift problem by searching for an optimal feature transformation to learn a domain-invariant representation. Such a domain shift can appear in handwriting recognition (HWR) applications where the motion pattern of the hand and with that the motion pattern of the pen is different for writing on paper and on tablet. This becomes visible in the sensor data for online handwriting (OnHW) from pens with integrated inertial measurement units. This paper proposes a supervised DA approach to enhance learning for OnHW recognition between tablet and paper data. Our method exploits loss functions such as maximum mean discrepancy and correlation alignment to learn a domain-invariant feature representation (i.e., similar covariances between tablet and paper features). We use a triplet loss that takes negative samples of the auxiliary domain (i.e., paper samples) to increase the amount of samples of the tablet dataset. We conduct an evaluation on novel sequence-based OnHW datasets (i.e., words) and show an improvement on the paper domain with an early fusion strategy by using pairwise learning.
Domain Adaptation for Time-Series Classification to Mitigate Covariate Shift
Apr 07, 2022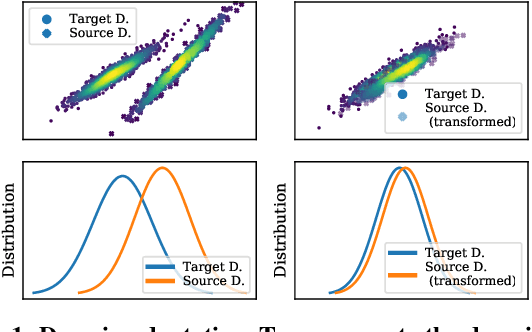
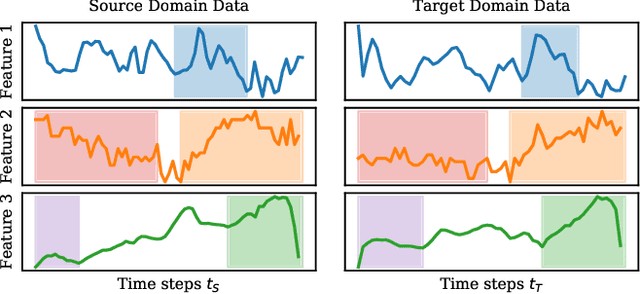
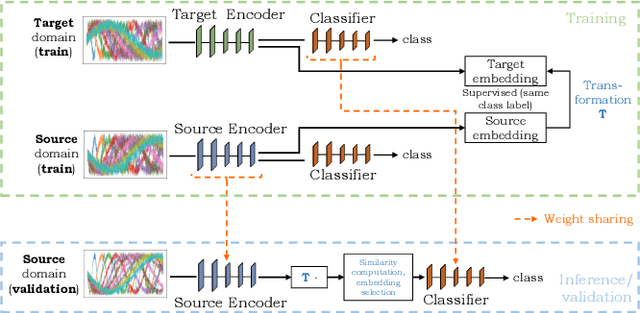
The performance of a machine learning model degrades when it is applied to data from a similar but different domain than the data it has initially been trained on. To mitigate this domain shift problem, domain adaptation (DA) techniques search for an optimal transformation that converts the (current) input data from a source domain to a target domain to learn a domain-invariant representations that reduces domain discrepancy. This paper proposes a novel supervised domain adaptation based on two steps. First, we search for an optimal class-dependent transformation from the source to the target domain from a few samples. We consider optimal transport methods such as the earth mover distance with Laplacian regularization, Sinkhorn transport and correlation alignment. Second, we use embedding similarity techniques to select the corresponding transformation at inference. We use correlation metrics and maximum mean discrepancy with higher-order moment matching techniques. We conduct an extensive evaluation on time-series datasets with domain shift including simulated and various online handwriting datasets to demonstrate the performance.