 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cluster-Matching-Based Method for Video Face Recognition
Oct 20, 2020



Face recognition systems are present in many modern solutions and thousands of applications in our daily lives. However, current solutions are not easily scalable, especially when it comes to the addition of new targeted people. We propose a cluster-matching-based approach for face recognition in video. In our approach, we use unsupervised learning to cluster the faces present in both the dataset and targeted videos selected for face recognition. Moreover, we design a cluster matching heuristic to associate clusters in both sets that is also capable of identifying when a face belongs to a non-registered person. Our method has achieved a recall of 99.435% and a precision of 99.131% in the task of video face recognition. Besides performing face recognition, it can also be used to determine the video segments where each person is present.
Video Quality Enhancement Using Deep Learning-Based Prediction Models for Quantized DCT Coefficients in MPEG I-frames
Oct 09, 2020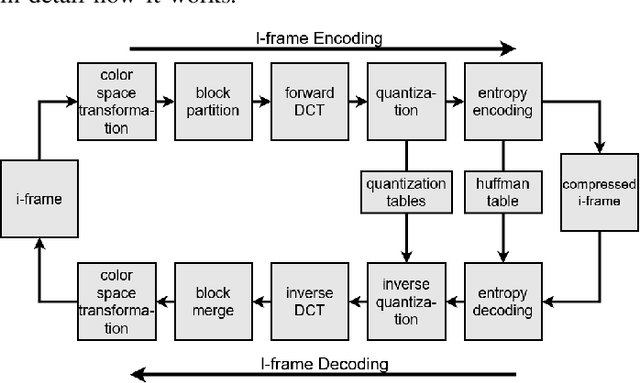


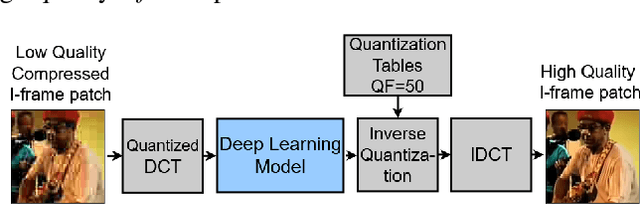
Recent works have successfully applied some types of Convolutional Neural Networks (CNNs) to reduce the noticeable distortion resulting from the lossy JPEG/MPEG compression technique. Most of them are built upon the processing made on the spatial domain. In this work, we propose a MPEG video decoder that is purely based on the frequency-to-frequency domain: it reads the quantized DCT coefficients received from a low-quality I-frames bitstream and, using a deep learning-based model, predicts the missing coefficients in order to recompose the same frames with enhanced quality. In experiments with a video dataset, our best model was able to improve from frames with quantized DCT coefficients corresponding to a Quality Factor (QF) of 10 to enhanced quality frames with QF slightly near to 20.