 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Quality Enhancement Using Deep Learning-Based Prediction Models for Quantized DCT Coefficients in MPEG I-frames
Paper and Code
Oct 09, 2020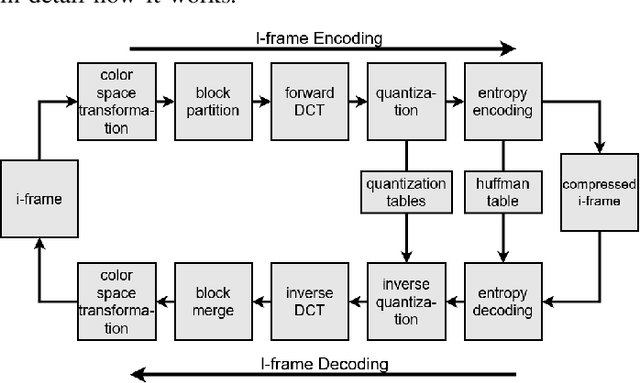


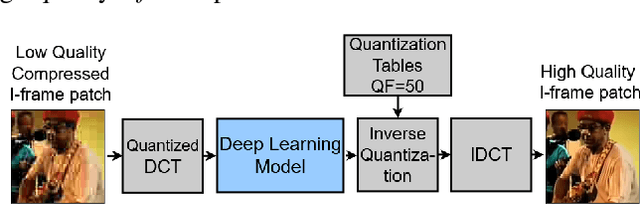
Recent works have successfully applied some types of Convolutional Neural Networks (CNNs) to reduce the noticeable distortion resulting from the lossy JPEG/MPEG compression technique. Most of them are built upon the processing made on the spatial domain. In this work, we propose a MPEG video decoder that is purely based on the frequency-to-frequency domain: it reads the quantized DCT coefficients received from a low-quality I-frames bitstream and, using a deep learning-based model, predicts the missing coefficients in order to recompose the same frames with enhanced quality. In experiments with a video dataset, our best model was able to improve from frames with quantized DCT coefficients corresponding to a Quality Factor (QF) of 10 to enhanced quality frames with QF slightly near to 20.