 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating and Querying Personalized Versions of Wikidata on a Laptop
Aug 18, 2021
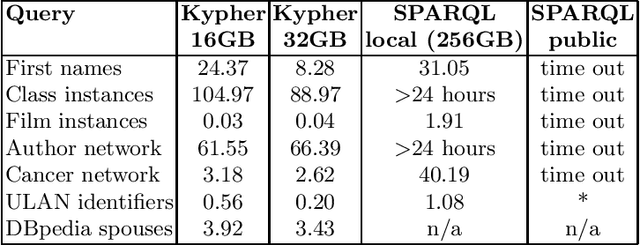


Application developers today have three choices for exploiting the knowledge present in Wikidata: they can download the Wikidata dumps in JSON or RDF format, they can use the Wikidata API to get data about individual entities, or they can use the Wikidata SPARQL endpoint. None of these methods can support complex, yet common, query use cases, such as retrieval of large amounts of data or aggregations over large fractions of Wikidata. This paper introduces KGTK Kypher, a query language and processor that allows users to create personalized variants of Wikidata on a laptop. We present several use cases that illustrate the types of analyses that Kypher enables users to run on the full Wikidata KG on a laptop, combining data from external resources such as DBpedia. The Kypher queries for these use cases run much faster on a laptop than the equivalent SPARQL queries on a Wikidata clone running on a powerful server with 24h time-out limits.
A Study of the Quality of Wikidata
Jul 23, 2021
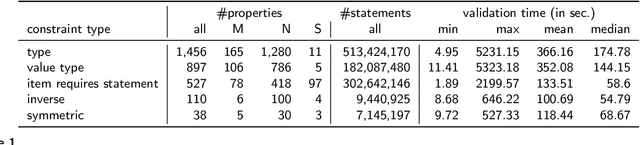
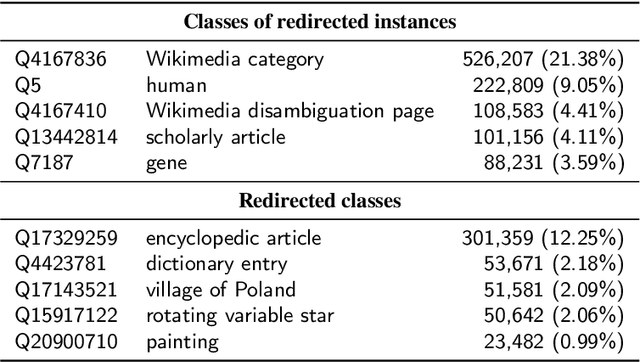
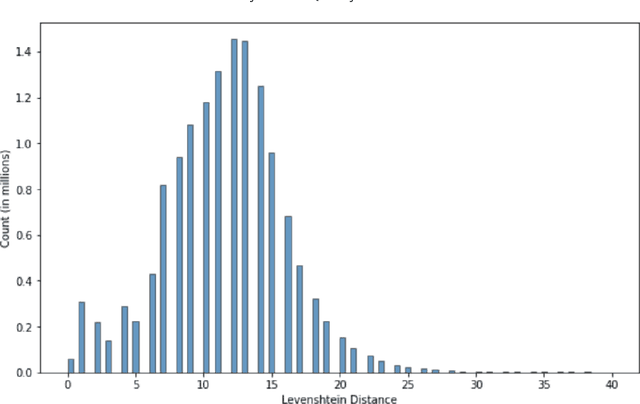
Wikidata has been increasingly adopted by many communities for a wide variety of applications, which demand high-quality knowledge to deliver successful results. In this paper, we develop a framework to detect and analyze low-quality statements in Wikidata by shedding light on the current practices exercised by the community. We explore three indicators of data quality in Wikidata, based on: 1) community consensus on the currently recorded knowledge, assuming that statements that have been removed and not added back are implicitly agreed to be of low quality; 2) statements that have been deprecated; and 3) constraint violations in the data. We combine these indicators to detect low-quality statements, revealing challenges with duplicate entities, missing triples, violated type rules, and taxonomic distinctions. Our findings complement ongoing efforts by the Wikidata community to improve data quality, aiming to make it easier for users and editors to find and correct mistakes.
Semantic Workflows and Machine Learning for the Assessment of Carbon Storage by Urban Trees
Sep 22, 2020
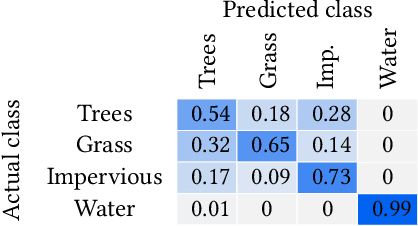
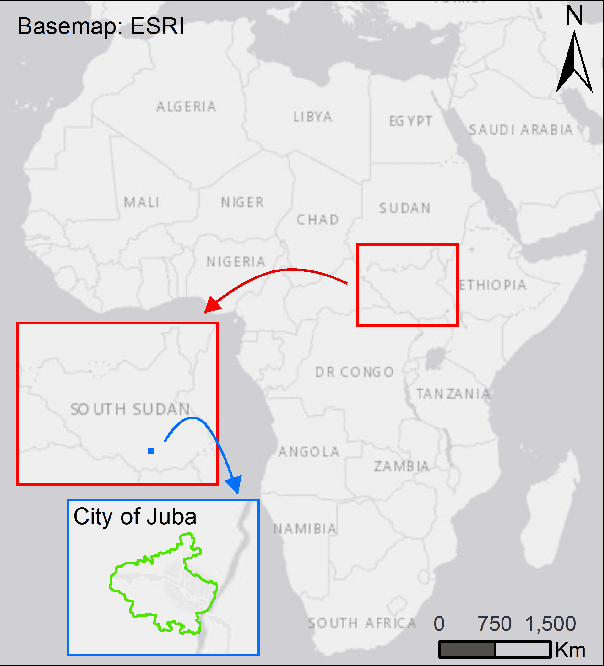
Climate science is critical for understanding both the causes and consequences of changes in global temperatures and has become imperative for decisive policy-making. However, climate science studies commonly require addressing complex interoperability issues between data, software, and experimental approaches from multiple fields. Scientific workflow systems provide unparalleled advantages to address these issues, including reproducibility of experiments, provenance capture, software reusability and knowledge sharing. In this paper, we introduce a novel workflow with a series of connected components to perform spatial data preparation, classification of satellite imagery with machine learning algorithms, and assessment of carbon stored by urban trees. To the best of our knowledge, this is the first study that estimates carbon storage for a region in Africa following the guidelines from the Intergovernmental Panel on Climate Change (IPCC).
* Previously published as part of the SciKnow 2019 Workshop, November 19th, 2019. Los Angeles, California, USA. Collocated with the tenth International Conference on Knowledge Capture (K-CAP)
OBA: An Ontology-Based Framework for Creating REST APIs for Knowledge Graphs
Jul 17, 2020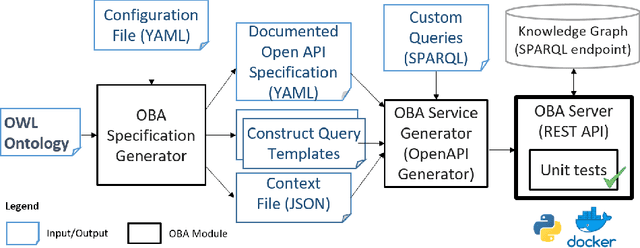
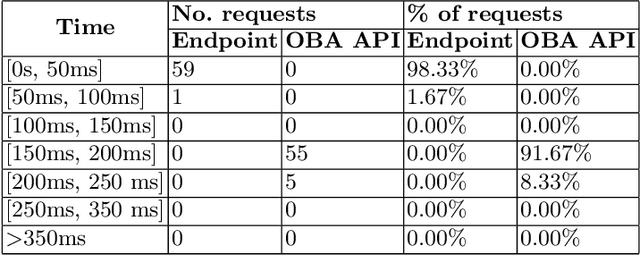
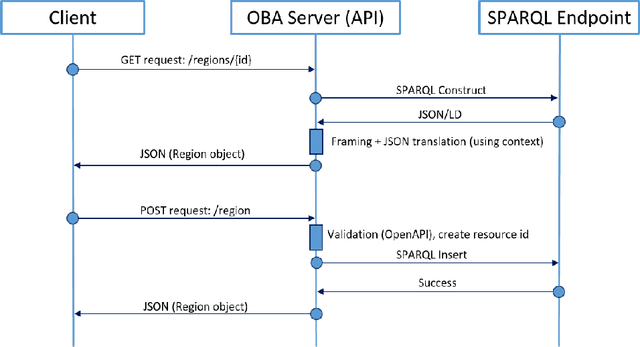
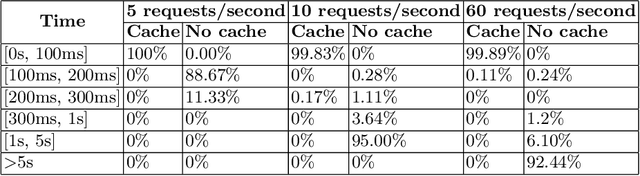
In recent years, Semantic Web technologies have been increasingly adopted by researchers, industry and public institutions to describe and link data on the Web, create web annotations and consume large knowledge graphs like Wikidata and DBPedia. However, there is still a knowledge gap between ontology engineers, who design, populate and create knowledge graphs; and web developers, who need to understand, access and query these knowledge graphs but are not familiar with ontologies, RDF or SPARQL. In this paper we describe the Ontology-Based APIs framework (OBA), our approach to automatically create REST APIs from ontologies while following RESTful API best practices. Given an ontology (or ontology network) OBA uses standard technologies familiar to web developers (OpenAPI Specification, JSON) and combines them with W3C standards (OWL, JSON-LD frames and SPARQL) to create maintainable APIs with documentation, units tests, automated validation of resources and clients (in Python, Javascript, etc.) for non Semantic Web experts to access the contents of a target knowledge graph. We showcase OBA with three examples that illustrate the capabilities of the framework for different ontologies.
KGTK: A Toolkit for Large Knowledge Graph Manipulation and Analysis
May 29, 2020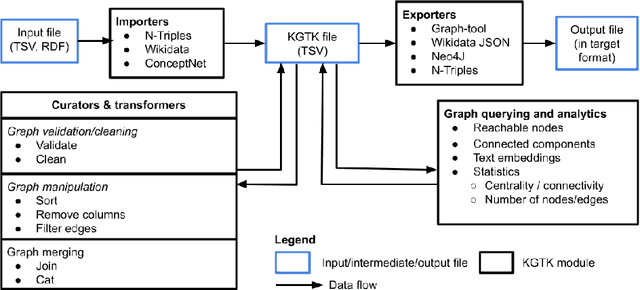
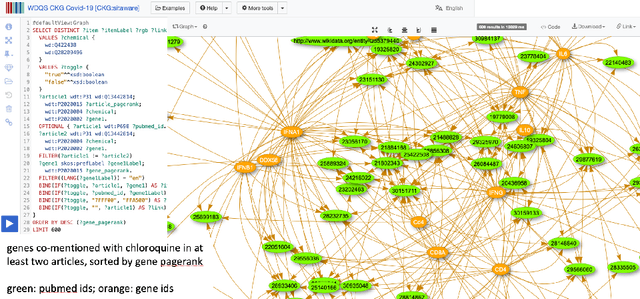
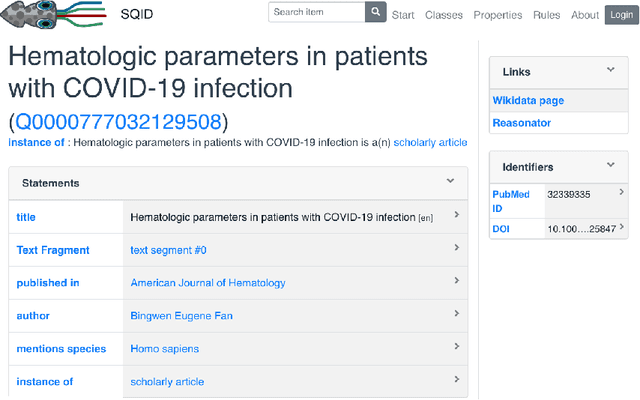
Knowledge graphs (KGs) have become the preferred technology for representing, sharing and adding knowledge to modern AI applications. While KGs have become a mainstream technology, the RDF/SPARQL-centric toolset for operating with them at scale is heterogeneous, difficult to integrate and only covers a subset of the operations that are commonly needed in data science applications. In this paper, we present KGTK, a data science-centric toolkit to represent, create, transform, enhance and analyze KGs. KGTK represents graphs in tables and leverages popular libraries developed for data science applications, enabling a wide audience of developers to easily construct knowledge graph pipelines for their applications. We illustrate KGTK with real-world scenarios in which we have used KGTK to integrate and manipulate large KGs, such as Wikidata, DBpedia and ConceptNet, in our own work.
Best Practices for Implementing FAIR Vocabularies and Ontologies on the Web
Mar 29, 2020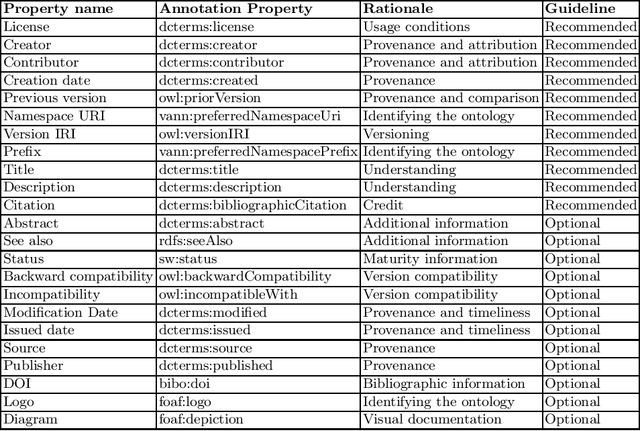
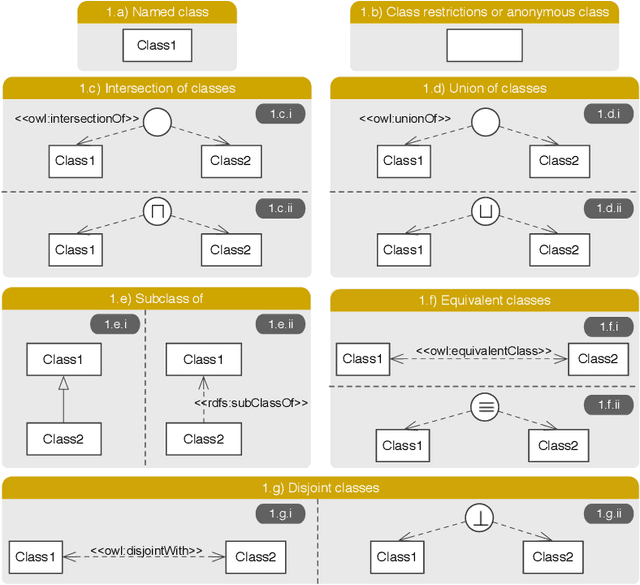
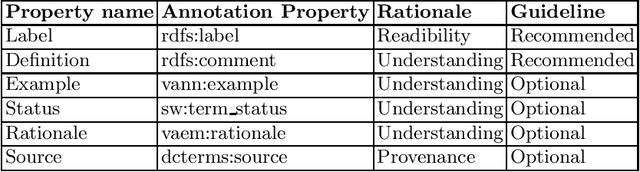
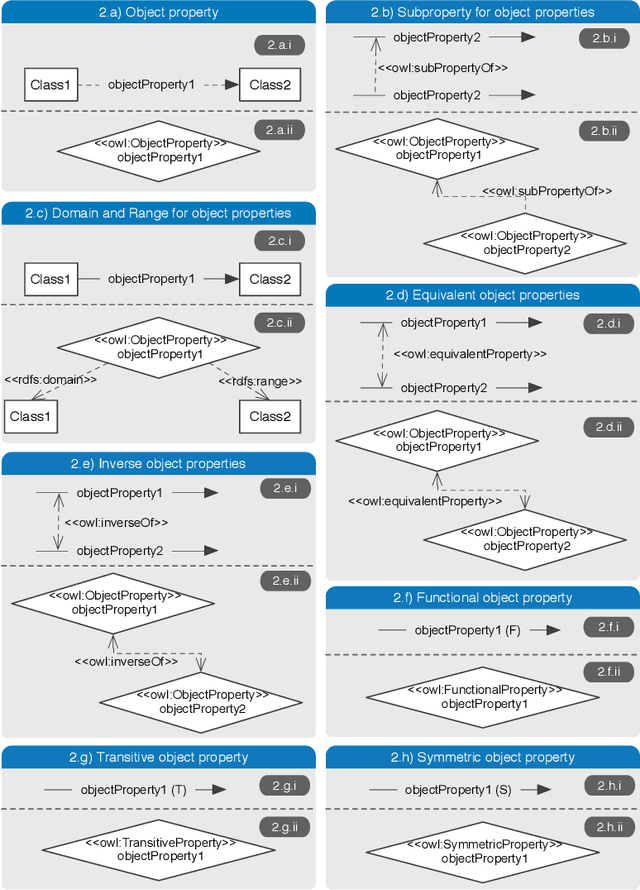
With the adoption of Semantic Web technologies, an increasing number of vocabularies and ontologies have been developed in different domains, ranging from Biology to Agronomy or Geosciences. However, many of these ontologies are still difficult to find, access and understand by researchers due to a lack of documentation, URI resolving issues, versioning problems, etc. In this chapter we describe guidelines and best practices for creating accessible, understandable and reusable ontologies on the Web, using standard practices and pointing to existing tools and frameworks developed by the Semantic Web community. We illustrate our guidelines with concrete examples, in order to help researchers implement these practices in their future vocabularies.