 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating and Querying Personalized Versions of Wikidata on a Laptop
Paper and Code

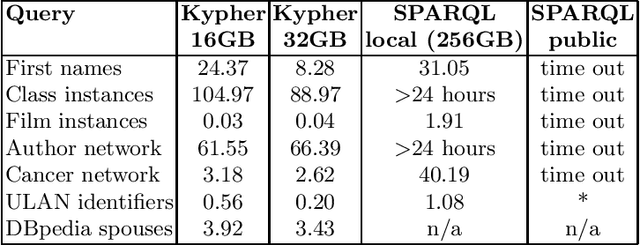


Application developers today have three choices for exploiting the knowledge present in Wikidata: they can download the Wikidata dumps in JSON or RDF format, they can use the Wikidata API to get data about individual entities, or they can use the Wikidata SPARQL endpoint. None of these methods can support complex, yet common, query use cases, such as retrieval of large amounts of data or aggregations over large fractions of Wikidata. This paper introduces KGTK Kypher, a query language and processor that allows users to create personalized variants of Wikidata on a laptop. We present several use cases that illustrate the types of analyses that Kypher enables users to run on the full Wikidata KG on a laptop, combining data from external resources such as DBpedia. The Kypher queries for these use cases run much faster on a laptop than the equivalent SPARQL queries on a Wikidata clone running on a powerful server with 24h time-out limits.