 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Wikidata Support Analogical Reasoning?
Oct 02, 2022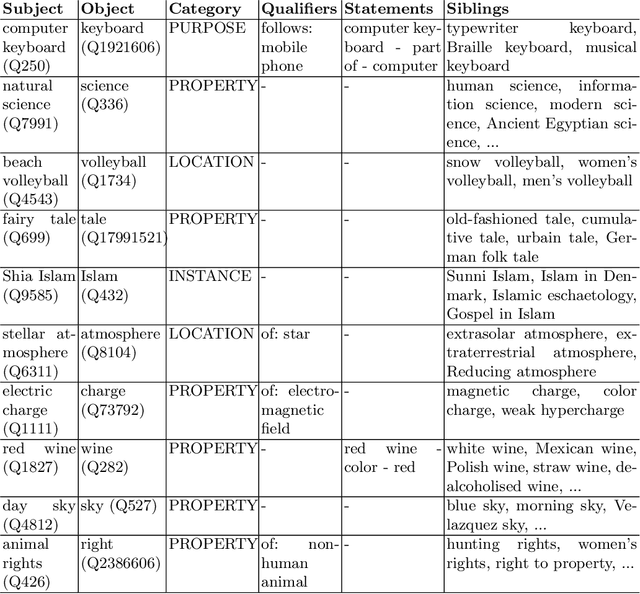
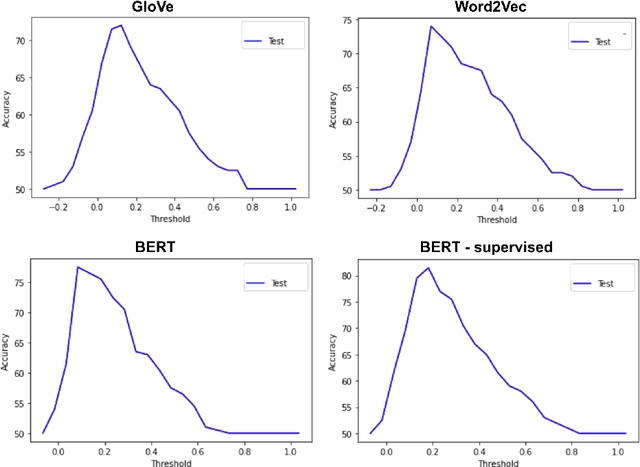

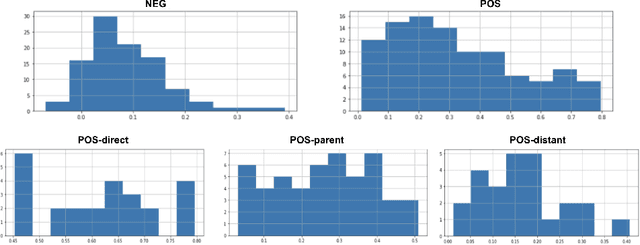
Analogical reasoning methods have been built over various resources, including commonsense knowledge bases, lexical resources, language models, or their combination. While the wide coverage of knowledge about entities and events make Wikidata a promising resource for analogical reasoning across situations and domains, Wikidata has not been employed for this task yet. In this paper, we investigate whether the knowledge in Wikidata supports analogical reasoning. Specifically, we study whether relational knowledge is modeled consistently in Wikidata, observing that relevant relational information is typically missing or modeled in an inconsistent way. Our further experiments show that Wikidata can be used to create data for analogy classification, but this requires much manual effort. To facilitate future work that can support analogies, we discuss key desiderata, and devise a set of metrics to guide an automatic method for extracting analogies from Wikidata.
Viola: A Topic Agnostic Generate-and-Rank Dialogue System
Aug 25, 2021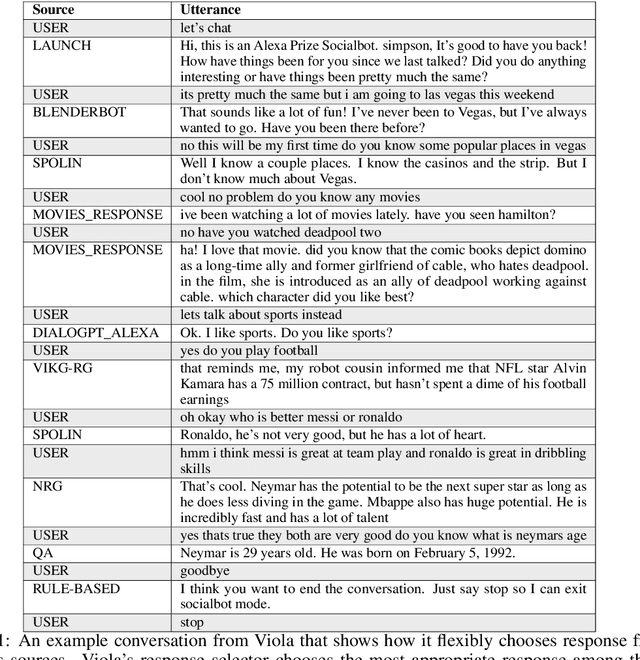
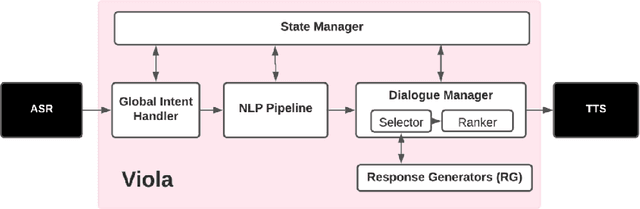
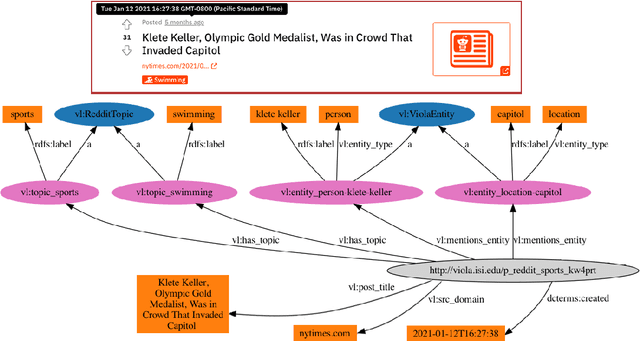
We present Viola, an open-domain dialogue system for spoken conversation that uses a topic-agnostic dialogue manager based on a simple generate-and-rank approach. Leveraging recent advances of generative dialogue systems powered by large language models, Viola fetches a batch of response candidates from various neural dialogue models trained with different datasets and knowledge-grounding inputs. Additional responses originating from template-based generators are also considered, depending on the user's input and detected entities. The hand-crafted generators build on a dynamic knowledge graph injected with rich content that is crawled from the web and automatically processed on a daily basis. Viola's response ranker is a fine-tuned polyencoder that chooses the best response given the dialogue history. While dedicated annotations for the polyencoder alone can indirectly steer it away from choosing problematic responses, we add rule-based safety nets to detect neural degeneration and a dedicated classifier to filter out offensive content. We analyze conversations that Viola took part in for the Alexa Prize Socialbot Grand Challenge 4 and discuss the strengths and weaknesses of our approach. Lastly, we suggest future work with a focus on curating conversation data specifcially for socialbots that will contribute towards a more robust data-driven socialbot.
An Effective Pixel-Wise Approach for Skin Colour Segmentation Using Pixel Neighbourhood Technique
Aug 24, 2021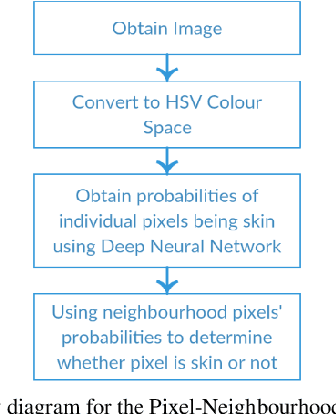
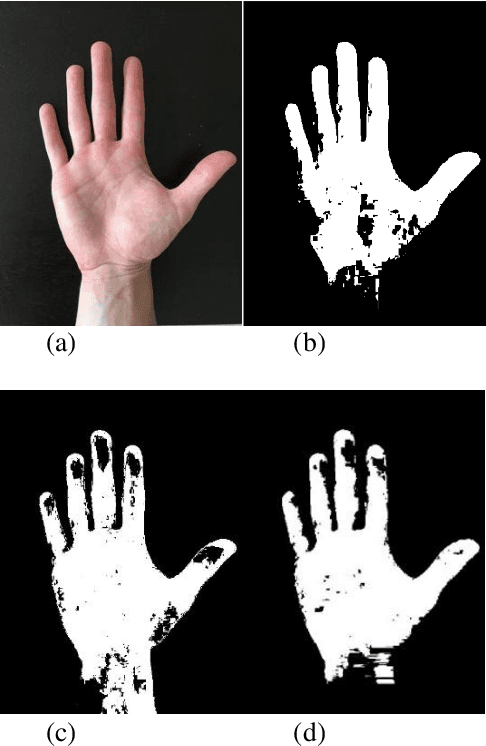

This paper presents a novel technique for skin colour segmentation that overcomes the limitations faced by existing techniques such as Colour Range Thresholding. Skin colour segmentation is affected by the varied skin colours and surrounding lighting conditions, leading to poorskin segmentation for many techniques. We propose a new two stage Pixel Neighbourhood technique that classifies any pixel as skin or non-skin based on its neighbourhood pixels. The first step calculates the probability of each pixel being skin by passing HSV values of the pixel to a Deep Neural Network model. In the next step, it calculates the likeliness of pixel being skin using these probabilities of neighbouring pixels. This technique performs skin colour segmentation better than the existing techniques.
* 5 pages
Real-time Indian Sign Language (ISL) Recognition
Aug 24, 2021
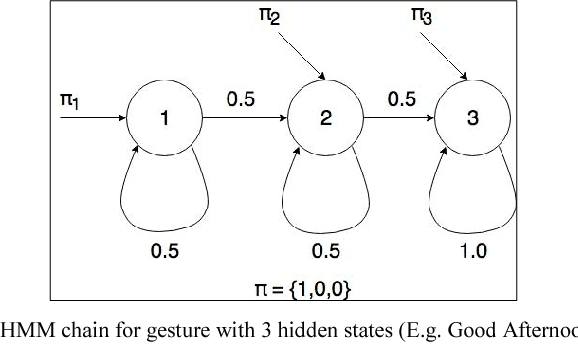
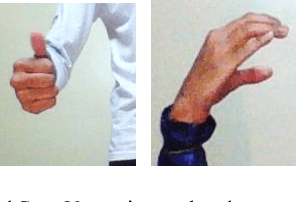

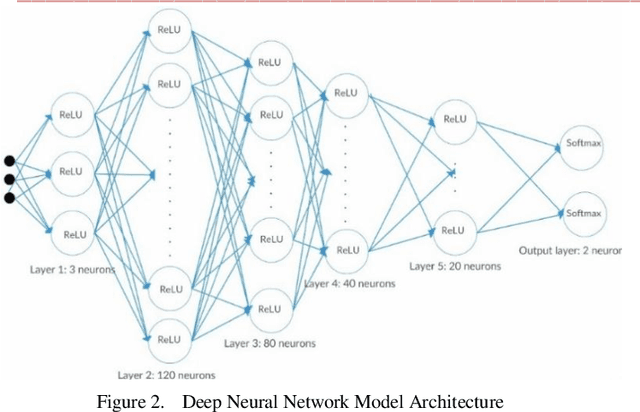
This paper presents a system which can recognise hand poses & gestures from the Indian Sign Language (ISL) in real-time using grid-based features. This system attempts to bridge the communication gap between the hearing and speech impaired and the rest of the society. The existing solutions either provide relatively low accuracy or do not work in real-time. This system provides good results on both the parameters. It can identify 33 hand poses and some gestures from the ISL. Sign Language is captured from a smartphone camera and its frames are transmitted to a remote server for processing. The use of any external hardware (such as gloves or the Microsoft Kinect sensor) is avoided, making it user-friendly. Techniques such as Face detection, Object stabilisation and Skin Colour Segmentation are used for hand detection and tracking. The image is further subjected to a Grid-based Feature Extraction technique which represents the hand's pose in the form of a Feature Vector. Hand poses are then classified using the k-Nearest Neighbours algorithm. On the other hand, for gesture classification, the motion and intermediate hand poses observation sequences are fed to Hidden Markov Model chains corresponding to the 12 pre-selected gestures defined in ISL. Using this methodology, the system is able to achieve an accuracy of 99.7% for static hand poses, and an accuracy of 97.23% for gesture recognition.
* 9 pages
Creating and Querying Personalized Versions of Wikidata on a Laptop
Aug 18, 2021
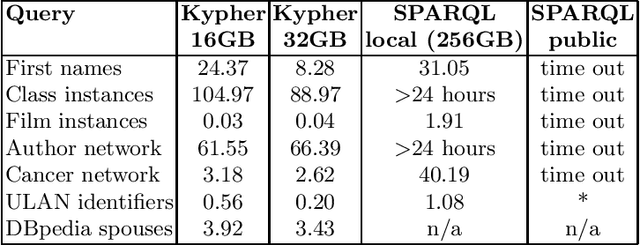


Application developers today have three choices for exploiting the knowledge present in Wikidata: they can download the Wikidata dumps in JSON or RDF format, they can use the Wikidata API to get data about individual entities, or they can use the Wikidata SPARQL endpoint. None of these methods can support complex, yet common, query use cases, such as retrieval of large amounts of data or aggregations over large fractions of Wikidata. This paper introduces KGTK Kypher, a query language and processor that allows users to create personalized variants of Wikidata on a laptop. We present several use cases that illustrate the types of analyses that Kypher enables users to run on the full Wikidata KG on a laptop, combining data from external resources such as DBpedia. The Kypher queries for these use cases run much faster on a laptop than the equivalent SPARQL queries on a Wikidata clone running on a powerful server with 24h time-out limits.
A Study of the Quality of Wikidata
Jul 23, 2021
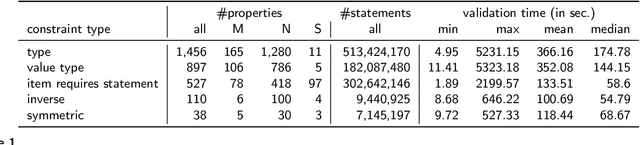
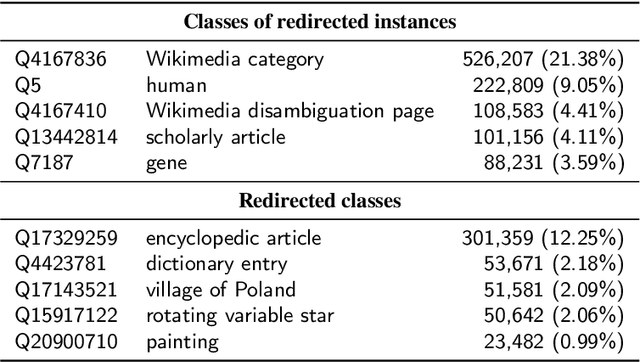
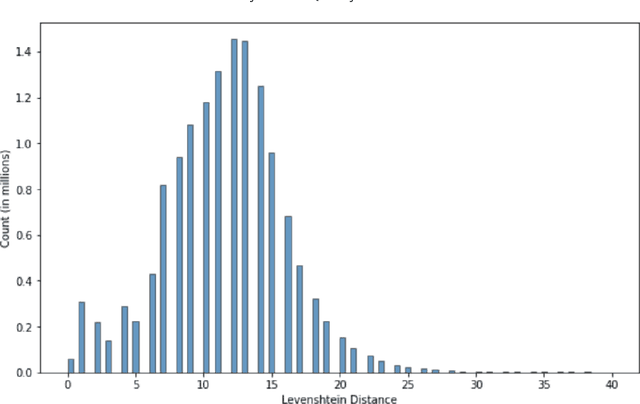
Wikidata has been increasingly adopted by many communities for a wide variety of applications, which demand high-quality knowledge to deliver successful results. In this paper, we develop a framework to detect and analyze low-quality statements in Wikidata by shedding light on the current practices exercised by the community. We explore three indicators of data quality in Wikidata, based on: 1) community consensus on the currently recorded knowledge, assuming that statements that have been removed and not added back are implicitly agreed to be of low quality; 2) statements that have been deprecated; and 3) constraint violations in the data. We combine these indicators to detect low-quality statements, revealing challenges with duplicate entities, missing triples, violated type rules, and taxonomic distinctions. Our findings complement ongoing efforts by the Wikidata community to improve data quality, aiming to make it easier for users and editors to find and correct mistakes.