 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Prostate Cancer Detection and Segmentation on Biparametric MRI using Non-local Mask R-CNN with Histopathological Ground Truth
Oct 28, 2020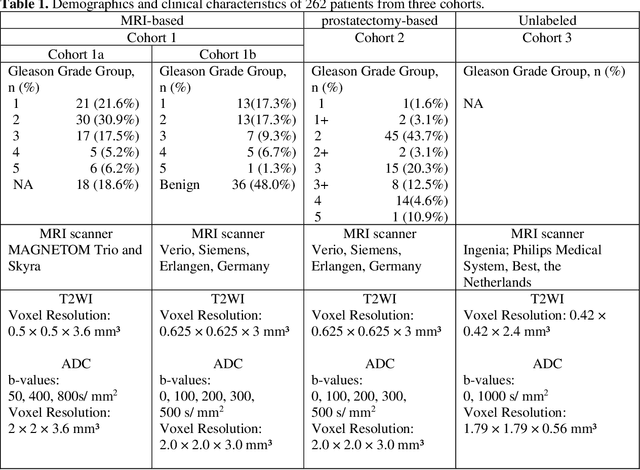

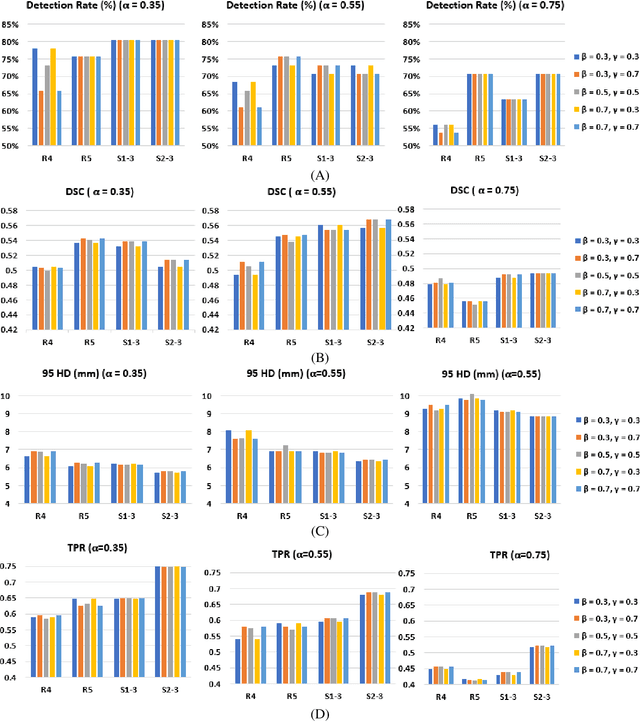
Purpose: We aimed to develop deep machine learning (DL) models to improve the detection and segmentation of intraprostatic lesions (IL) on bp-MRI by using whole amount prostatectomy specimen-based delineations. We also aimed to investigate whether transfer learning and self-training would improve results with small amount labelled data. Methods: 158 patients had suspicious lesions delineated on MRI based on bp-MRI, 64 patients had ILs delineated on MRI based on whole mount prostatectomy specimen sections, 40 patients were unlabelled. A non-local Mask R-CNN was proposed to improve the segmentation accuracy. Transfer learning was investigated by fine-tuning a model trained using MRI-based delineations with prostatectomy-based delineations. Two label selection strategies were investigated in self-training. The performance of models was evaluated by 3D detection rate, dice similarity coefficient (DSC), 95 percentile Hausdrauff (95 HD, mm) and true positive ratio (TPR). Results: With prostatectomy-based delineations, the non-local Mask R-CNN with fine-tuning and self-training significantly improved all evaluation metrics. For the model with the highest detection rate and DSC, 80.5% (33/41) of lesions in all Gleason Grade Groups (GGG) were detected with DSC of 0.548[0.165], 95 HD of 5.72[3.17] and TPR of 0.613[0.193]. Among them, 94.7% (18/19) of lesions with GGG > 2 were detected with DSC of 0.604[0.135], 95 HD of 6.26[3.44] and TPR of 0.580[0.190]. Conclusion: DL models can achieve high prostate cancer detection and segmentation accuracy on bp-MRI based on annotations from histologic images. To further improve the performance, more data with annotations of both MRI and whole amount prostatectomy specimens are required.
KGTK: A Toolkit for Large Knowledge Graph Manipulation and Analysis
May 29, 2020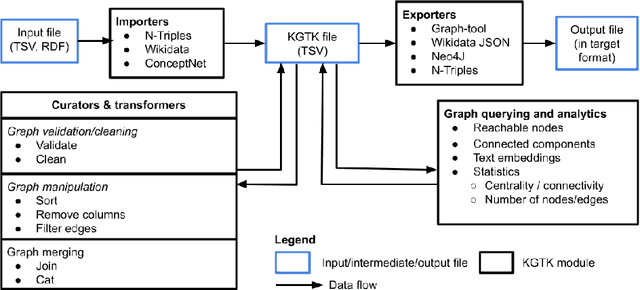
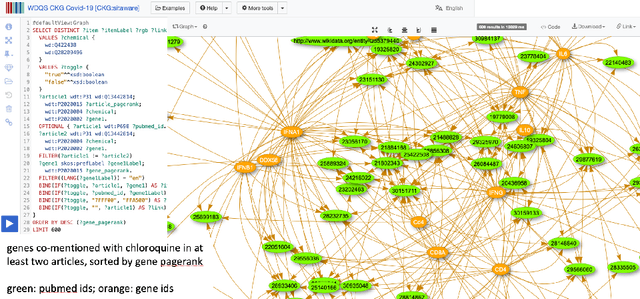
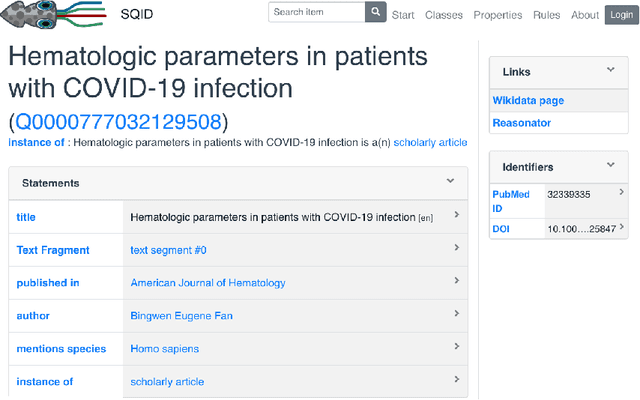
Knowledge graphs (KGs) have become the preferred technology for representing, sharing and adding knowledge to modern AI applications. While KGs have become a mainstream technology, the RDF/SPARQL-centric toolset for operating with them at scale is heterogeneous, difficult to integrate and only covers a subset of the operations that are commonly needed in data science applications. In this paper, we present KGTK, a data science-centric toolkit to represent, create, transform, enhance and analyze KGs. KGTK represents graphs in tables and leverages popular libraries developed for data science applications, enabling a wide audience of developers to easily construct knowledge graph pipelines for their applications. We illustrate KGTK with real-world scenarios in which we have used KGTK to integrate and manipulate large KGs, such as Wikidata, DBpedia and ConceptNet, in our own work.