 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Noisy Audio Dataset to Evaluate Machine Learning Approaches for Automatic Speech Recognition Systems
Oct 04, 2021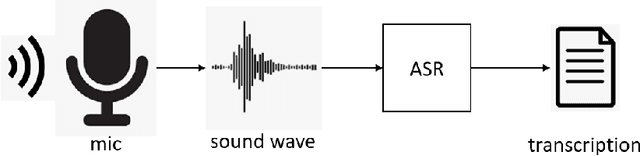

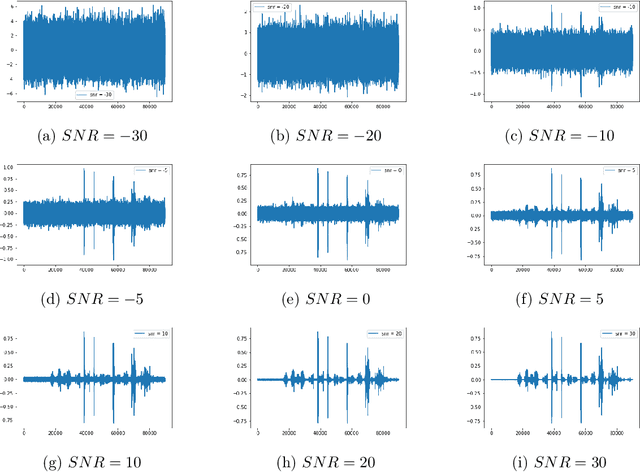
Automatic speech recognition systems are part of people's daily lives, embedded in personal assistants and mobile phones, helping as a facilitator for human-machine interaction while allowing access to information in a practically intuitive way. Such systems are usually implemented using machine learning techniques, especially with deep neural networks. Even with its high performance in the task of transcribing text from speech, few works address the issue of its recognition in noisy environments and, usually, the datasets used do not contain noisy audio examples, while only mitigating this issue using data augmentation techniques. This work aims to present the process of building a dataset of noisy audios, in a specific case of degenerated audios due to interference, commonly present in radio transmissions. Additionally, we present initial results of a classifier that uses such data for evaluation, indicating the benefits of using this dataset in the recognizer's training process. Such recognizer achieves an average result of 0.4116 in terms of character error rate in the noisy set (SNR = 30).