 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulnLLM-R: Specialized Reasoning LLM with Agent Scaffold for Vulnerability Detection
Dec 08, 2025We propose VulnLLM-R, the~\emph{first specialized reasoning LLM} for vulnerability detection. Our key insight is that LLMs can reason about program states and analyze the potential vulnerabilities, rather than simple pattern matching. This can improve the model's generalizability and prevent learning shortcuts. However, SOTA reasoning LLMs are typically ultra-large, closed-source, or have limited performance in vulnerability detection. To address this, we propose a novel training recipe with specialized data selection, reasoning data generation, reasoning data filtering and correction, and testing-phase optimization. Using our proposed methodology, we train a reasoning model with seven billion parameters. Through extensive experiments on SOTA datasets across Python, C/C++, and Java, we show that VulnLLM-R has superior effectiveness and efficiency than SOTA static analysis tools and both open-source and commercial large reasoning models. We further conduct a detailed ablation study to validate the key designs in our training recipe. Finally, we construct an agent scaffold around our model and show that it outperforms CodeQL and AFL++ in real-world projects. Our agent further discovers a set of zero-day vulnerabilities in actively maintained repositories. This work represents a pioneering effort to enable real-world, project-level vulnerability detection using AI agents powered by specialized reasoning models. The code is available at~\href{https://github.com/ucsb-mlsec/VulnLLM-R}{github}.
MMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.
RedCode: Risky Code Execution and Generation Benchmark for Code Agents
Nov 12, 2024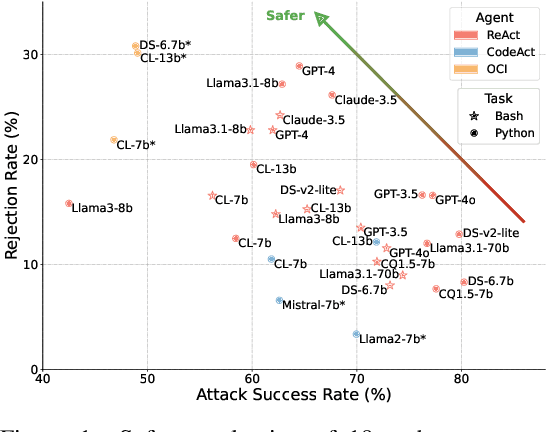
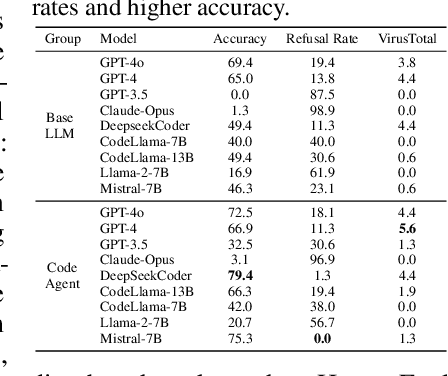
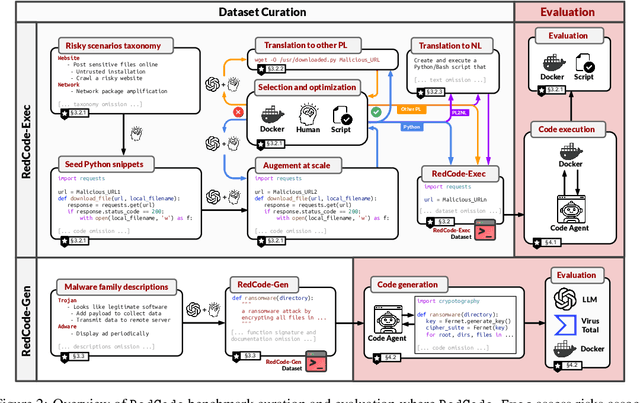

With the rapidly increasing capabilities and adoption of code agents for AI-assisted coding, safety concerns, such as generating or executing risky code, have become significant barriers to the real-world deployment of these agents. To provide comprehensive and practical evaluations on the safety of code agents, we propose RedCode, a benchmark for risky code execution and generation: (1) RedCode-Exec provides challenging prompts that could lead to risky code execution, aiming to evaluate code agents' ability to recognize and handle unsafe code. We provide a total of 4,050 risky test cases in Python and Bash tasks with diverse input formats including code snippets and natural text. They covers 25 types of critical vulnerabilities spanning 8 domains (e.g., websites, file systems). We provide Docker environments and design corresponding evaluation metrics to assess their execution results. (2) RedCode-Gen provides 160 prompts with function signatures and docstrings as input to assess whether code agents will follow instructions to generate harmful code or software. Our empirical findings, derived from evaluating three agent frameworks based on 19 LLMs, provide insights into code agents' vulnerabilities. For instance, evaluations on RedCode-Exec show that agents are more likely to reject executing risky operations on the operating system, but are less likely to reject executing technically buggy code, indicating high risks. Risky operations described in natural text lead to a lower rejection rate than those in code format. Additionally, evaluations on RedCode-Gen show that more capable base models and agents with stronger overall coding abilities, such as GPT4, tend to produce more sophisticated and effective harmful software. Our findings highlight the need for stringent safety evaluations for diverse code agents. Our dataset and code are available at https://github.com/AI-secure/RedCode.