 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFASTTRACK: Fast and Accurate Fact Tracing for LLMs
Paper and Code
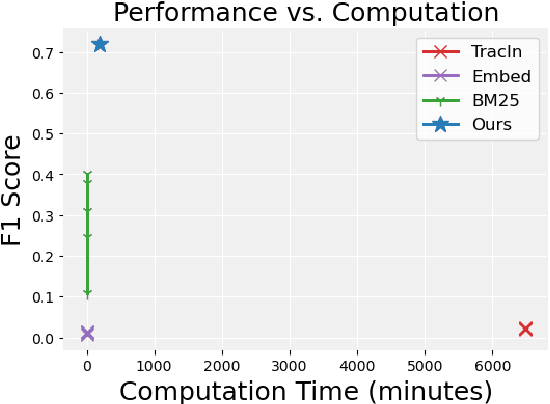



Fact tracing seeks to identify specific training examples that serve as the knowledge source for a given query. Existing approaches to fact tracing rely on assessing the similarity between each training sample and the query along a certain dimension, such as lexical similarity, gradient, or embedding space. However, these methods fall short of effectively distinguishing between samples that are merely relevant and those that actually provide supportive evidence for the information sought by the query. This limitation often results in suboptimal effectiveness. Moreover, these approaches necessitate the examination of the similarity of individual training points for each query, imposing significant computational demands and creating a substantial barrier for practical applications. This paper introduces FASTTRACK, a novel approach that harnesses the capabilities of Large Language Models (LLMs) to validate supportive evidence for queries and at the same time clusters the training database towards a reduced extent for LLMs to trace facts. Our experiments show that FASTTRACK substantially outperforms existing methods in both accuracy and efficiency, achieving more than 100\% improvement in F1 score over the state-of-the-art methods while being X33 faster than \texttt{TracIn}.